
बड़े विजन मॉडल डेल्स (LVLMS) छवि प्रसंस्करण क्षमताओं के साथ बड़े भाषा मॉडल को एकीकृत करते हैं, उन्हें छवियों की व्याख्या करने और संगत पाठ प्रतिक्रिया का उत्पादन करने में सक्षम बनाते हैं। वे अक्सर तब चलते हैं जब वे दृश्य वस्तुओं को पहचानते हैं और संकेतों पर प्रतिक्रिया करते हैं, जब मल्टी-स्टेप लॉजिक को समस्याओं के साथ प्रस्तुत किया जाता है। विज़न-लैंग्वेज काम करता है, जैसे कि चार्ट को समझना, दृश्य गणित के प्रश्नों को हल करना, या आंकड़ों की व्याख्या करना, मान्यता से अधिक मांग करना; उन्हें दृश्य संकेतों के आधार पर तार्किक उपायों का पालन करने की क्षमता की आवश्यकता होती है। मॉडल आर्किटेक्चर में प्रगति के बावजूद, वर्तमान प्रणाली इस तरह के जटिल विचारों में सटीक और व्याख्यात्मक उत्तर देने के लिए लगातार संघर्ष करती हैं।
वर्तमान दृष्टि-भाषा मॉडल के मॉडल में मुख्य सीमा जटिल तर्क करने में उनकी अक्षमता है जिसमें तार्किक कटौती के कई चरण शामिल हैं, खासकर जब पाठ्य प्रश्नों के साथ संयोजन में छवियों की व्याख्या करते हैं। ये मॉडल हमेशा अपने तर्क को सत्यापित या सुधार नहीं करते हैं, जो गलत या उथले आउटपुट का कारण बनता है। इसके अलावा, इन मॉडलों का पालन करने वाली तर्क श्रृंखलाएं आमतौर पर पारदर्शी या सत्यापित नहीं होती हैं, जिससे उनके निष्कर्षों की ताकत सुनिश्चित करना मुश्किल हो जाता है। चुनौती ने इस तर्क की दूरी को हटा दिया है, जिसे केवल टेक्स्ट-मॉडल डेलो ने सुदृढीकरण सीखने की तकनीकों पर प्रभावी रूप से ध्यान केंद्रित करना शुरू कर दिया है, लेकिन दृष्टि-भाषा के मॉडल अभी भी पूरी तरह से स्वीकार किए जाते हैं।
इस अध्ययन से पहले, ऐसी प्रणालियों में तर्क को बढ़ाने के प्रयास काफी हद तक मानक फाइन-ट्यूनिंग या संकेत तकनीकों पर निर्भर करते हैं। हालांकि बुनियादी कार्यों में सहायक, इन दृष्टिकोणों के परिणामस्वरूप अक्सर क्रिया या दोहराव के उत्पादन के साथ सीमित गहराई होती है। विज़न-लिंगुआ मॉडल डेलो, जैसे कि QWEN2.5-VL-7B, ने अपने दृश्य निर्देश-अनचाहे क्षमताओं के कारण वादे दिखाए, लेकिन अपने पाठ-कुछ समकक्षों जैसे कि डीप्सिक-आर 1 के साथ तुलनात्मक मल्टी-स्टेप लॉजिक का अभाव था। यहां तक कि जब संरचित प्रश्नों के साथ पूछा जाता है, तो ये मॉडल अपने आउटपुट को प्रतिबिंबित करने या मध्यवर्ती तर्क उपायों को मान्य करने के लिए संघर्ष करते हैं। यह एक महत्वपूर्ण बाधा थी, विशेष रूप से उपयोग के मामलों के लिए, जैसे कि संरचनात्मक निर्णय, जैसे कि दृश्य समस्या या शैक्षिक समर्थन उपकरणों को हल करना।
कैलिफोर्निया विश्वविद्यालय के शोधकर्ताओं, लॉस एंजिल्स ने ओपनवॉकर -7 बी नामक एक मॉडल पेश किया। इस मॉडल को एक उपन्यास प्रशिक्षण विधि द्वारा विकसित किया गया था जो दोहरावदार लूप में देखे गए फाइन-ट्यूनिंग (एसएफटी) और सुदृढीकरण लर्निंग (आरएल) को जोड़ती है। संरचनात्मक तर्क श्रृंखलाओं का उत्पादन करने के लिए Dippic-R1 के डिस्टिल्ड संस्करण में Qwen2.5-VL-3B और डाइटिंग का उपयोग करके छवि q tions का उत्पादन करके प्रक्रिया शुरू हुई। इस आउटपुट ने SFT के पहले दौर के लिए प्रशिक्षण डेटा बनाया, जो बुनियादी तर्क रचनाओं को सीखने में मॉडल का मार्गदर्शन करता है। इसके बाद, समूह सापेक्ष नीति ऑप्टिमेशन Ptimization (GRPO) का उपयोग करके एक सुदृढीकरण शिक्षा के चरण को इनाम प्रतिक्रिया के आधार पर मॉडल के तर्क को बेहतर बनाने के लिए लागू किया गया था। यह संयोजन अगले चक्र के लिए एक नए प्रशिक्षण डेटा के रूप में प्रत्येक पुनरावृत्ति के शुद्ध आउटपुट का उपयोग करते हुए, मॉडल को आत्म-सुधार करने में सक्षम बनाता है।
इस विधि में सावधानियां डेटा क्यूरेशन और कई प्रशिक्षण चरण शामिल हैं। पहले पुनरावृत्ति में, एसएफटी के लिए 25,000 उदाहरणों का उपयोग किया गया था, जो कि फिगेरका, ज्यामिति 3K, टैब बमडब्ल्यूपी और विस्विस जैसे डेटासेट से प्राप्त किए गए थे। इन उदाहरणों को अत्यधिक क्रिया या निरर्थक प्रतिबिंबों को दूर करने के लिए फ़िल्टर किया गया था, जिससे प्रशिक्षण की गुणवत्ता में सुधार हुआ। जीआरपीओ को तब 5,000 नमूनों के एक छोटे, अधिक कठिन डेटासेट पर लागू किया गया था। इसके कारण मैथविस्टा बेंचमार्क पर 62.5% से 65.6% की सटीकता हुई। दूसरे संशोधन में, एसएफटी के लिए अन्य 5,000 उच्च गुणवत्ता वाले उदाहरणों का उपयोग किया गया था, जिसमें सटीकता 66.1%थी। जीआरपीओ के दूसरे दौर ने ऑपरेशन को 69.4%तक पहुंचा दिया। इन चरणों के आसपास, मॉडल का मूल्यांकन प्रत्येक संशोधन के साथ निरंतर प्रभाव के लाभ के साथ कई बेंचमार्क, मेथविस्टा, मेथर और मैथवाइज पर किया गया था।
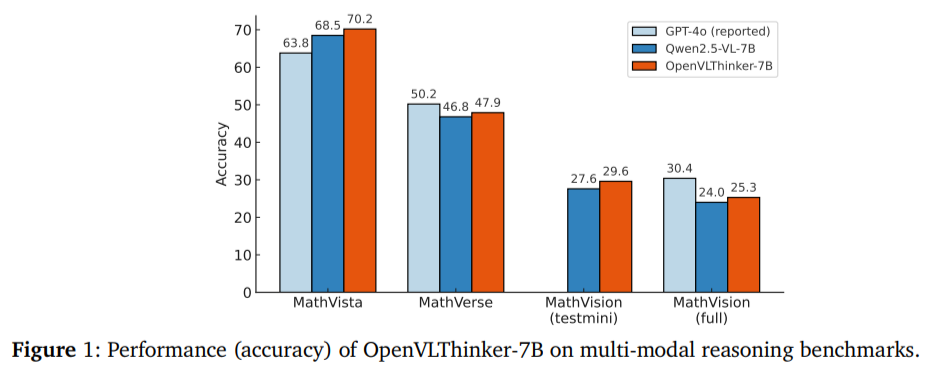
एक मात्रात्मक तरीके से, OpenVlthinkar-7B इसका बेस मॉडल, Qwen2.5-VL-7B, काफी अधिक हो गया। मेथविस्टा पर, यह बेस मॉडल के 50.2% की तुलना में 70.2% सटीकता तक पहुंच गया है। मेथर पर, सुधार 46.8% से 68.5% था। Mathwision पूर्ण परीक्षण की सटीकता 24.0%से बढ़कर 29.6%हो गई, और Mathwision परीक्षण 25.3%से सुधार हुआ। ये अपडेट बताते हैं कि मॉडल ने तर्क पैटर्न का पालन करना सीखा और इसे अदृश्य मल्टीमॉडल कार्यों में बेहतर सामान्य बना दिया। प्रशिक्षण के प्रत्येक पुनरावृत्ति से मजबूर होने वाले लाभों का योगदान, लूप्ड संरचना में पुरस्कार-आधारित शिक्षा के साथ फाइन-ट्यूनिंग को संयोजित करने की ताकत का प्रदर्शन किया।

इस मॉडल की शक्ति का मुख्य हिस्सा इसकी दोहरावदार रचना में निहित है। व्यापक डेटासेट पर भरोसा करने के बजाय, यह गुणवत्ता और संरचना पर केंद्रित है। SFT और RL का प्रत्येक चक्र छवियों, प्रश्नों और उत्तरों के बीच संबंध को समझने के लिए मॉडल की क्षमता में सुधार करता है। आत्म-गुणवत्ता और सुधार व्यवहार, शुरू में मानक LVLMS में कमी थी, सत्यापित इनाम संकेतों के साथ सुदृढीकरण शिक्षा के लिए एक उपाय के रूप में उभरा। इसने OpenVlthinkar -7B लॉजिक को उन चिह्नों का उत्पादन करने की अनुमति दी जो तार्किक रूप से सुसंगत और व्याख्यात्मक थे। सूक्ष्म-सुधार, जैसे कि कम आत्म-प्रतिबिंब या लघु तर्क श्रृंखलाओं के साथ सटीकता में वृद्धि, इसके समग्र प्रभाव के लाभ में योगदान देता है।

अनुसंधान से कुछ प्रमुख टेकवे:
- UCLA शोधकर्ताओं ने Qwen2.5-VL-7B बेस मॉडल के साथ शुरू होने वाले संयुक्त SFT और RL दृष्टिकोण का उपयोग करके OpenValthininker-7B विकसित किया।
- Tion pission पीढ़ी, तर्क आसवन और वैकल्पिक SFT और GRPO सुदृढीकरण शिक्षा के साथ जुड़े पुनरावृत्ति प्रशिक्षण चक्र का उपयोग।
- प्रारंभिक SFT ने 25,000 फ़िल्टर किए गए उदाहरणों का उपयोग किया, जबकि RL चरणों ने ज्यामिति 3K और SuperClower जैसे डेटासेट से 5,000 कठोर नमूनों के छोटे सेटों का उपयोग किया।
- मेथविस्टा पर, सटीकता 50.2% (बेस मॉडल) से बढ़कर 70.2% हो गई। मैथर्स की सटीकता 46.8% से बढ़कर 68.5% हो गई, और अन्य डेटासेट ने भी महत्वपूर्ण लाभ देखे।
- जीआरपीओ प्रभावी रूप से उचित उत्तरों को पुरस्कृत करके, क्रिया को कम करके और तार्किक प्रासंगिकता में सुधार करके तर्क व्यवहार को शुद्ध करता है।
- प्रत्येक प्रशिक्षण पुनरावृत्ति ने अतिरिक्त प्रदर्शन को बढ़ाया, जो आत्म-सुधार रणनीति की प्रभावशीलता की पुष्टि करता है।
- मल्टीमॉडल मॉडल शैक्षिक, दृश्य विश्लेषिकी और सहायक तकनीकी अनुप्रयोगों के लिए उपयोगी, डेलो में आर 1-स्टाइल मल्टी-स्टेप लॉजिक लाने के लिए एक व्यावहारिक तरीका स्थापित करते हैं।
जाँच करना कागज पर मॉडल, हग फेस और गिथब पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में अधिक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।