

Transformer Models Delo AI Systems significantly affects how natural language understands, translation and logic functions. These large -scale models, especially the larger language models deles (LLMS), have grown in size and complexity where they include widespread capabilities in different domains. However, applying these models to new, specific tasks is a complex operation. Each new application generally calculates cautious dataset selection, hours of fine-tuning and composure degree. Although these models offer a strong foundation in the Junoweltge, their rigidity in handling new domains with minimal data remains the main limit. As researchers aim to bring AI closer to human adaptability, attention has turned to more efficient methods that allow such models to change their behavior without rearranging each parameter.
Challenge to customize LLMS for new tasks
The central difficulty is to accept foundation models in unique applications without repeating the expensive and time-intensive training cycle. Most solutions today depend on creating new adapters for each task, which are different components trained to further the behavior of the model. These adapters must be made from scratch for each task, and no benefits learned from one application can often be transferred to another. This adaptation process takes time consuming and lacks measurement. Moreover, tuning models on specialized datasets usually require high level precision in hyperperameter preferences, and failure to find the right configuration can lead to poor results. Even when adaptation is successful, the result is often a large collection of different function-specific components that are not integrated or easy to use.
In response to these limits, researchers have adopted low-rank adaptation (LORA), a technique that changes only a small set of dimensions instead of the full model. Lora injects low-rank matrices in specific layers of stable LLM, allowing the base weight to remain unchanged when enabling work-specific customization. This method reduces the number of trainable parameters. However, for each task, the new lora adapter still needs to be trained from scratch. When full-tuning is more efficient, this method does not allow for fast, fly adaptation. Recent progresses have tried to further compress these adapters or connect multiple adapters during the forecasting; However, they still rely much on previous training and cannot dynamically produce new adapters.
Introducing Text-to-Lora: Instant adapter generation from work descriptions
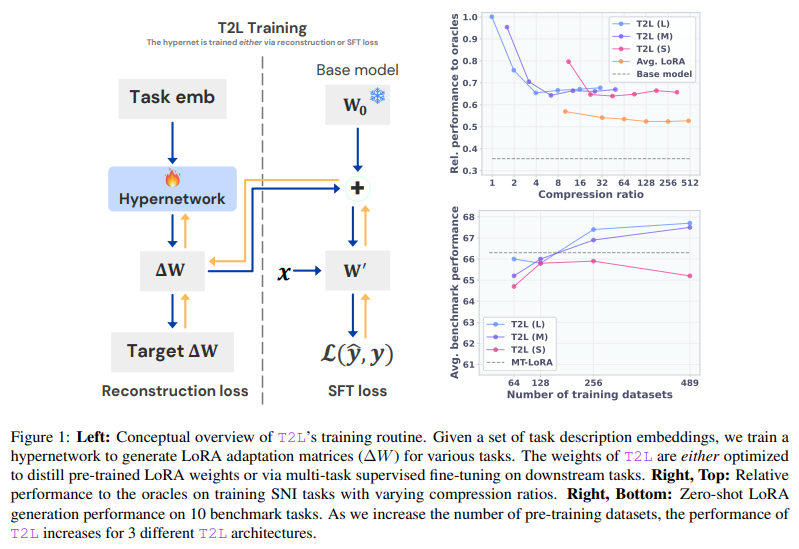
Sakana AI researchers introduced Text-to-Lora (T2L)Instead of creating and training new adapters for each task, the textual descriptions of the target work are designed to immediately create the work-specific laura adapters. T2L acts as a hypernetwork capable of outputing the adapter weight in a single forward pass. It learns from the library of the lauras adapters covering various domains, including GSM8K, Arc-Challenge, Bullac and others. Once trained, T2L can interpret a description of a task and generate the required adapter without additional training. This capacity not only eliminates the need for a manual adapter generation, but also enables the system to normalize the tasks that never come before.
T2L uses a combination of module-specific and level-specific embeddings to guide the Pay Generation process. Three architectural variants were tested: a large version with 55 million dimensions, medium with 34 million, and only 5 million small. Despite their differences in size, all models were able to create low-rank matrices needed for adapter functionality. Training used a super natural instruction dataset in 479 tasks, in which each function is described in natural language and encoded in vector form. By merging these descriptions with the layer and module embeddings, the T2L adapter forms the low-rank A and B matrices required for the functionality. This allows a model to replace hundreds of hand -formed loras, producing compatible results with many small calculation steps.

Benchmark performance and scalability of T2L
On benchmarks like Arc-Essky and GSM8K, T2L matches or exceeds the influence of Task-specific loras. For example, the accuracy on the arc-Ezy using T2L was 76.6%, which matched the excellence of a manually tuned adapter. On the bullet, it reached 89.9%, slightly outperforming the original adapter. PICA And even more difficult benchmarks like Vingrande, where the influence is damaged by excessive impact, T2L produces better results than manually trained adapters. These updates are believed to be from harmful compression in underlying hypernetwork training, which acts as a form of regularization. While the number of training datasets increases from 16 to 479, the performance of zero-shot settings has improved significantly, showing the ability of T2L to normalize extensive contact during training.

Some of the key techways from the research includes:
- T2L allows instant adaptation of LLMS using natural language descriptions.
- It supports zero-shot ts generalization in the unwanted tasks during training.
- Three architectural variants of T2L were tested with a calculation of dimensions of 55 m, 34m and 5M.
- Benchmarks include ARCE, Bullac, GSM8K, Helasswag, Pica, MBPP and more.
- T2 LA received a benchmark accuracy of 76.6% (ARCE), 89.9% (BullQ), and 92.6% (Helswag).
- It matched or exceeded manually trained lauras in influence on multiple tasks.
- Super Natural Notifications Trained using 479 tasks from the dataset.
- T2L Task uses the GTE-Large-N-V11 model to generate embeddings.
- Laura adapters produced by T2L target only query and value estimates in attention blocks, total 3.4M parameters.
- The performance remains consistent with the loss of high reconstruction, showing the elasticity of compression.
In conclusion, this research highlights the front main step in the flexible and efficient model adaptation. Instead of relying on repeated, resource-rich processes, T2L uses a natural language as a control method, enabling models to specialize using simple function descriptions. This capacity dramatically reduces the time and cost required to adapt to LLMS in new domains. Moreover, it suggests that as long as sufficient pre -adapters are available for training, future models can potentially adapt to seconds in any task described in plain English. The use of hypernetworks for the construction of dynamic adapters also requires less storage for model specialty, increasing the practicality of this method in the product environment.
Check Paper And Githb -page. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 100 k+ ml subredit And subscribe Our newsletter.
Asif Razzaq is the CEO of MarketechPost Media Inc. as a visionary entrepreneur and engineer, Asif is committed to increasing the possibility of artificial intelligence for social good. Their most recent effort is the inauguration of the artificial intelligence media platform, MarktecPost, for its depth of machine learning and deep learning news for its depth of coverage .This is technically sound and easily understandable by a large audience. The platform has more than 2 million monthly views, showing its popularity among the audience.


