
नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
अलीबाबा समूह ने क्वीनलॉन्ग-एल 1 को पेश किया है, जो एक नई संरचना है जो बड़ी भाषा मॉडल (एलएलएम) को बहुत लंबे इनपुट में लॉग इन करने में सक्षम बनाती है। यह विकास उद्यम अनुप्रयोगों की नई लहर को अवगुण कर सकता है, जिसके लिए विस्तृत कॉर्पोरेट फाइलिंग, लंबे वित्तीय विवरण या जटिल कानूनी अनुबंधों जैसे व्यापक दस्तावेजों को समझने और अंतर्दृष्टि आकर्षित करने के लिए मॉडल की आवश्यकता होती है।
एआई के लिए लंबे समय के तर्क की चुनौती
हाल के लॉजिक मॉडल ने अपनी समस्या को हल करने के लिए क्षमताओं में काफी सुधार किया है, विशेष रूप से हाल की प्रगति (LRMS), विशेष रूप से सुदृढीकरण सीखने (आरएल) के माध्यम से। अनुसंधान से पता चलता है कि जब आरएल को ठीक-ट्यूनिंग के साथ प्रशिक्षित किया जाता है, तो LRMS मानव “धीमी सोच” के समान कौशल प्राप्त करता है, जहां वे जटिल कार्यों से निपटने के लिए एक सभ्य रणनीति विकसित करते हैं।
हालांकि, ये अपग्रेड मुख्य रूप से तब देखे जाते हैं जब मॉडल अपेक्षाकृत कम टुकड़ों के साथ काम करते हैं, आमतौर पर लगभग 4,000 टोकन। इन मॉडलों के अपने तर्क को लंबे समय तक संदर्भित करने की क्षमता (जैसे, 120,000 टोकन) एक बड़ी चुनौती है। इस तरह के एक लंबे समय के तर्क के लिए पूरे संदर्भ की एक मजबूत समझ और बहु-चरण विश्लेषण की क्षमता की आवश्यकता होती है। क्वीनलॉन्ग-एल 1 के डेवलपर्स ने अपने पेपर में लिखा है, “यह सीमा व्यावहारिक अनुप्रयोगों के लिए एक महत्वपूर्ण बाधा है, जैसे कि डीप वांडा रिसर्च, जहां एलआरएम को ज्ञान-गहन वातावरण से जानकारी एकत्र करनी चाहिए,” इकट्ठा करने और प्रक्रिया करने की आवश्यकता है।
शोधकर्ता इन चुनौतियों को लंबे समय में “लॉजिक आरएल” की अवधारणा में औपचारिक बनाते हैं। लघु संदर्भ तर्क के विपरीत, जो अक्सर मॉडल के अंदर संग्रहीत Junoweltge कहानियों पर निर्भर करता है, लॉजिक आरएल को लंबे इनपुट और भूमि से सटीक प्रासंगिक जानकारी प्राप्त करने के लिए मॉडल की आवश्यकता होती है। इसके बाद ही वे इस निहित जानकारी के आधार पर तर्क की श्रृंखला का उत्पादन कर सकते हैं।
आरएल द्वारा प्रशिक्षण मॉडल इसके लिए मुश्किल हैं और अक्सर अनुचित शिक्षा और अस्थिर इष्टतम ptimization प्रक्रियाओं में परिणाम होता है। मॉडल अच्छे समाधानों में बदलने या विभिन्न तर्क पथ खोजने के लिए अपनी क्षमता खोने के लिए संघर्ष करते हैं।
Quanlong-L1: बहु-चरण दृष्टिकोण
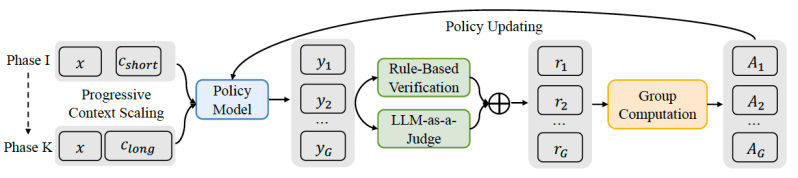
क्वीनलॉन्ग-एल 1 एक सुदृढीकरण शिक्षा ढांचा है जिसे लंबे संदर्भ में छोटे ग्रंथों के साथ संक्रमण में मदद करने के लिए डिज़ाइन किया गया है। संरचना संरचित, बहु-चरण प्रक्रिया द्वारा मौजूदा लघु संदर्भ LRM को ध्यान से बढ़ाती है:
वार्म-अप प्रेरित फाइन-ट्यूनिंग (SFT): मॉडल सबसे पहले SFT चरण के माध्यम से जाता है, जहां इसे लंबे समय तक तर्क के उदाहरणों पर प्रशिक्षित किया जाता है। यह चरण एक ठोस नींव स्थापित करता है, जो मॉडल को भूमि की जानकारी के लिए लंबे इनपुट के साथ सटीक रूप से सक्षम बनाता है। उस संदर्भ को समझना, तार्किक तर्क श्रृंखलाओं का उत्पादन करने और उत्तर के दिलचस्प में बुनियादी क्षमताओं को विकसित करने में मदद करता है।
पाठ्यक्रम इस स्तर पर, मॉडल को कई चरणों द्वारा प्रशिक्षित किया जाता है, इनपुट दस्तावेजों की लक्ष्य लंबाई धीरे -धीरे बढ़ रही है। यह व्यवस्थित, चरण-दर-चरण दृष्टिकोण मॉडल को लंबे समय तक अपनी तर्क रणनीति के अनुकूल बनाने में मदद करता है। जब मॉडल को अचानक बहुत लंबे ग्रंथों पर प्रशिक्षित किया जाता है, तो वे अक्सर अस्थिरता से बचते हैं।
कठिनाई जोरदार मिसाल के नमूने: अंतिम प्रशिक्षण चरण में पिछले प्रशिक्षण चरणों के चुनौतीपूर्ण उदाहरण शामिल हैं, यह सुनिश्चित करते हुए कि मॉडल सख्त समस्याओं से सीखना जारी रखता है। यह कठिन पैटर्न पसंद करता है और मॉडल को अधिक विविध और जटिल तर्क पथ का पता लगाने के लिए प्रोत्साहित करता है।

इस संरचनात्मक प्रशिक्षण के अलावा, क्वान्लॉन्ग-एल 1 एक अलग पुरस्कार प्रणाली का भी उपयोग करता है। जबकि छोटे संदर्भ में तर्क कार्यों के लिए प्रशिक्षण अक्सर सख्त नियम-आधारित पुरस्कारों (उदाहरण के लिए, गणित की समस्या का सही उत्तर) पर निर्भर करता है, क्वीनलॉन्ग-एल 1 एक हाइब्रिड पुरस्कार विधि को नियुक्त करता है। यह एक नियम-आधारित सत्यापन को जोड़ती है, जो “एलएलएम-ए-ए-ए-ऑडेज” के साथ शुद्धता के मानदंडों के सख्त पालन की जांच करके सटीकता की गारंटी देता है। यह न्यायाधीश न्यायाधीश मॉडल डेल के उत्तर के उत्तर की तुलना भूमि सत्य से करता है, लंबे, संवेदनशील दस्तावेजों से निपटने के दौरान विभिन्न तरीकों से अधिक राहत और विभिन्न तरीकों से बेहतर हैंडलिंग व्यक्त की जा सकती है।
परीक्षण में Cuvenlong-L1 डालें
अलीबाबा टीम ने एक प्राथमिक फ़ंक्शन के रूप में दस्तावेज़ प्रश्न-उत्तर (DOCQA) का उपयोग करके क्वीनलॉन्ग-एल 1 का मूल्यांकन किया। यह परिदृश्य उद्यम आवश्यकताओं के लिए बहुत प्रासंगिक है, जहां AIA Ga ense दस्तावेजों को जटिल प्रश्नों के उत्तर देने के लिए समझा जाना चाहिए।
सात लंबे संदर्भों में व्यावहारिक परिणाम DOCCA बेंचमार्क में क्वानलॉन्ग-एल 1 की क्षमताओं को दर्शाते हैं। गौरतलब है कि क्वीनलॉन्ग-एल 1-32 बी मॉडल (डीपस्क-आर 1-डिस्टिल क्यूवेन -32 बी पर आधारित) ने क्लाउड -3.7 सोननेट थिंकिंग ऑफ एन्थ्रोपिक, और ओपनई के ओ 3-मिनी और क्यूवेन 3-235 बी-ए 22 बी के साथ तुलनात्मक संचालन हासिल किया। छोटे Quanlong-L1-14B मॉडल ने भी Google की मिथुन 2.0 फ्लैश थिंकिंग को पीछे छोड़ दिया और 3-32B को क्वेन किया।

वास्तविक दुनिया के अनुप्रयोगों से संबंधित एक महत्वपूर्ण खोज यह है कि आरएल प्रशिक्षण एक विशिष्ट लंबे संदर्भ में तर्क व्यवहार कैसे विकसित करता है। पेपर नोट करता है कि क्वीनलॉन्ग-एल 1 के साथ प्रशिक्षित मॉडल “ग्राउंडिंग” हैं (एक दस्तावेज़ के विशिष्ट भागों के उत्तरों को जोड़ते हुए), “सबगोल सेटिंग” (जटिल प्रश्नों को तोड़ता है), “बैकट्रैकिंग” (मध्य-पुनर्निर्मित “अपनी गलतियों) और” उनके उत्तरों को डबल-चेक करना)।
उदाहरण के लिए, जब एक बेस मॉडल वित्तीय दस्तावेज में अप्रासंगिक विवरण द्वारा कंधे से कंधा मिलाकर हो सकता है या असंबंधित जानकारी के ओवर-एनालाइजिंग के लूप में फंस सकता है, तो क्वीनलॉन्ग-एल 1 प्रशिक्षित मॉडल डेल प्रभावी आत्म-प्रतिबिंब में संलग्न होने की क्षमता दिखाता है। वह सफलतापूर्वक इस डिस्ट्रेक्टर विवरण को फ़िल्टर कर सकता है, गलत तरीके से पीछे हट सकता है, और सही उत्तर तक पहुंच सकता है।
क्वानलॉन्ग-एल 1 जैसी तकनीक उद्यम में एआई की उपयोगिता का काफी विस्तार कर सकती है। संभावित अनुप्रयोगों में कानूनी प्रौद्योगिकी (हजारों कानूनी दस्तावेजों का विश्लेषण), वित्त (डीप PANDP डॉट अनुसंधान और जोखिम मूल्यांकन या निवेश के अवसरों के लिए वित्तीय फाइलें) और ग्राहक सेवा (अधिक सूचित समर्थन प्रदान करने के लिए लंबे उपभोक्ता बातचीत इतिहास का विश्लेषण) शामिल हैं। शोधकर्ताओं ने क्वानलॉन्ग-एल 1 नुस्खा और प्रशिक्षित मॉडल के लिए वेट के लिए एक कोड जारी किया है।