


Понимание различных типов данных, таких как текстВ изображенияВ Видеои аудио В одной модели большая проблема. Большие языковые модели, которые обрабатывают все эти вместе, борются за выполнение моделей, предназначенных только для одного типа. Обучение таким моделям сложно, потому что разные типы данных имеют разные шаблоны, что затрудняет сбалансировку точности между задачами. Многие модели не могут должным образом выравнивать информацию из различных входов, замедляя ответы и требующие больших объемов данных. Эти проблемы затрудняют создание по -настоящему эффективной модели, которая может в равной степени хорошо понимать все типы данных.
В настоящее время модели сосредоточены на конкретных задачах, таких как распознавание изображений, анализ видео или обработка звука отдельно. Некоторые модели пытаются объединить эти задачи, но их производительность остается намного слабее, чем специализированные модели. Модели на языке зрения улучшаются и теперь обрабатывают видео, 3D-контент и смешанные входы, но интеграция звука правильно остается серьезной проблемой. Большие аудио текстовые модели пытаются соединить речь с языковыми моделями, но понимание сложного звука, такого как музыка и события, остается недоразвитым. Новее Omni-Modal Модели пытаются обрабатывать несколько типов данных, но борются с плохой производительностью, несбалансированным обучением и неэффективной обработкой данных.
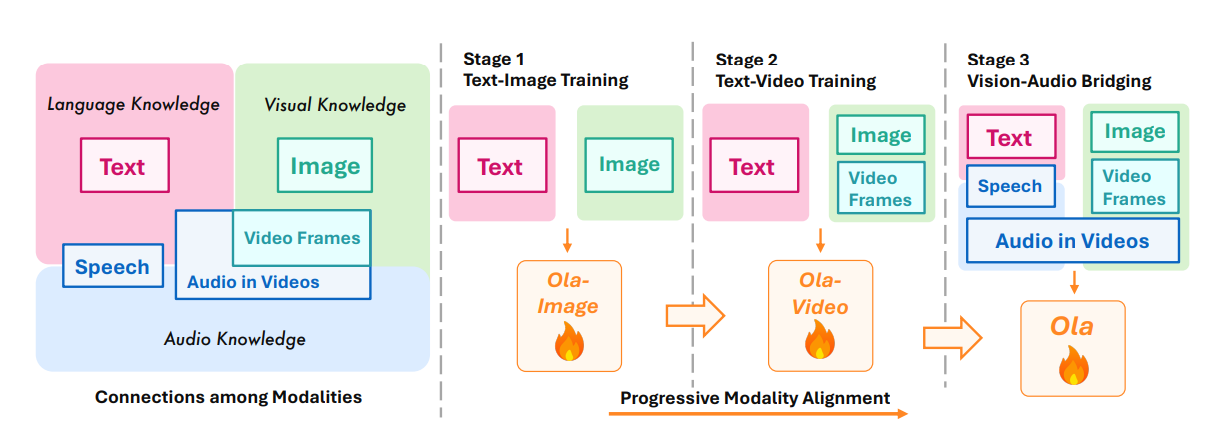
Чтобы решить это, исследователи из Университет ЦингхуаВ Tencent Hunyuan Researchи S-Lab, NTU предложенный Олаan Омни–модальный Модель, разработанная для понимания и создания нескольких модальностей данных, включая текст, речи, изображения, видео и аудио. Структура построена на модульной архитектуре, где каждая модальность имеет выделенный энкодер – текст, изображения, видео и аудио – отвечает для обработки его соответствующего ввода. Эти кодеры отображают свои данные в единое репрезентативное пространство, позволяя центральной модели крупного языка (LLM) интерпретировать и генерировать ответы в разных методах. Для аудио, OLA использует подход с двойным энкодером, который отдельно обрабатывает функции речи и музыки, прежде чем интегрировать их в общее представление. Входы зрения поддерживают свои исходные соотношения сторон, используя Oryxvitобеспечение минимального искажения во время обработки. Модель включает Местное глобальное внимание слой для повышения эффективности, который сжимает длину токена без потери критических функций, максимизируя вычисления без потери производительности. Наконец, синтез речи обрабатывается внешним декодером текста в речь, поддерживая потоковую передачу в реальном времени.
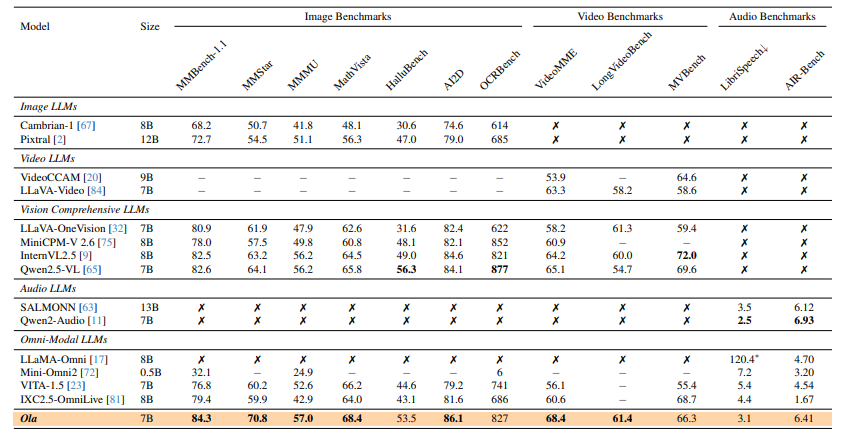
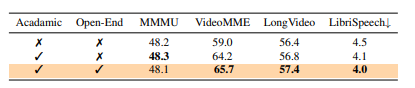
Исследователи провели всеобъемлющий сравнительный анализ через изображение, видео и аудиопонимание, чтобы оценить структуру. Ола опирается QWEN-2,5-7Bинтеграция Oryxvit как кодер видения, Whisper-V3-Large как речевой кодер, и Beats-As2m (CPT2) Как музыкальный кодер. Обучение использовало высокую скорость обучения 1E-3 для MLP адаптер перед тренировками, сведен к 2E-5 для обучения текстовым изображениям и 1e-5 Для обучения видео-аудио, с размером партии 256 над 64 NVIDIA A800 GPUПолем Обширные оценки продемонстрировали возможности Олы по нескольким показателям, включая Mmbench-1.1, Mmstar, Videomme, и Воздушнаягде он превзошел существующие омни-модальные LLMS. В звуковых тестах Ола достигла 1,9% на тестовом подмножестве Librispeech и 6.41 Средний балл на Воздушнаяпревзойдя предыдущие омни-модальные модели и приближаясь к производительности специализированных звуковых моделей. Дальнейший анализ подчеркнул межмодальные преимущества обучения OLA, показывая, что совместное обучение с видео-аудиоными данными улучшила производительность распознавания речи. Стратегии обучения Олы были проанализированы, демонстрируя рост эффективности в омни-модальном обучении, межмодальном выравнивании видео-аудио и прогрессивном обучении модальности.

В конечном счете, предлагаемая модель успешно объединяет текст, изображения, видео и аудиообразование с помощью подхода прогрессивного выравнивания модальности с замечательной производительностью по различным показателям. Его архитектурные инновации, эффективные методы обучения и высококачественная кросс-модальная подготовка данных преодолевают слабые стороны более ранних моделей и представляют возможности омни-модального обучения. Ола Структура и процесс обучения могут использоваться в качестве базовой линии в будущих исследованиях, влияя на развитие в более общих моделях ИИ. Будущая работа может опираться на Ола Фонд для улучшения омни-модального понимания и применения путем усовершенствования межмодального выравнивания и расширения разнообразия данных.
Проверить бумага и страница GitHub. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 75K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Divyesh – стажер консалтинга в Marktechpost. Он преследует Btech в области сельского хозяйства и продовольственной инженерии от Индийского технологического института, Харагпур. Он является энтузиастом науки о данных и машинного обучения, который хочет интегрировать эти ведущие технологии в сельскохозяйственную область и решить проблемы.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)


