
Defusion-based large-based MODELS Dells (LLMS) are being discovered as a promising alternative to traditional ORE Torrentive models, which simultaneously gives the possibility of multi-token generation. Using bilateral meditation methods, these models aim to accelerate decoding, theoretically providing faster estimates than Ore Torrentive systems. However, despite their promise, the diffusion models often struggle in practice to accelerate competitive estimate, while Ore Toreggive big language models limit their ability to match the real-world display of LLMS.
The primary challenge is in the inability to estimate in the spread -based LLMS. These models usually do not support key-value (kV) cache mechanisms, which are required to accelerate the estimate by re-using the calculations of the calculation. KV Without caching, the step of each new pay generation in the diffusion models repeats the full attention, which makes them calculate. Next, when decoding multiple tokens simultaneously – the main feature of the diffusion models – the quality of pay generation often worsens due to disruption in the token dependence under conditional independence. This makes the defusion models unreliable to practical deployment despite their theoretical power.
Attempts to improve diffusion focuses on strategies such as block -wise pay generation and partial caching. For example, models such as Llada and Dream for the convenience of multi-token pay generation include masked diffusion techniques. However, they still have an effective key-value (kV) cache system, and parallel decoding in these models often results in inconsistent output. While some approaches use supporting models for approximately token dependence, these methods represent additional complexity without fully addressing the underlying operations issues. As a result, the pace and quality of the Pay Generation in the diffusion LLM lag behind the Ore Torrentive models.
Hong Kong University, and MIT’s NVIDI researchers introduced fast-DLM, which introduced a structure developed to address these limitations. Fast-DLM Spread brings two innovations for LLMS: an estimated kay cache mechanism and confidence-aware parallel decoding strategy. About how cache is prepared for the bilateral nature of the models, which allow activation to be effectively reused with previous decoding steps. Self-confident parallel decoding decodes selectively based on the threshold of confidence, reducing errors arising from the assumption of token independence. This approach provides a balance between motion and quality of pay generation, which makes it a practical settlement for diffusion-based text generation tasks.
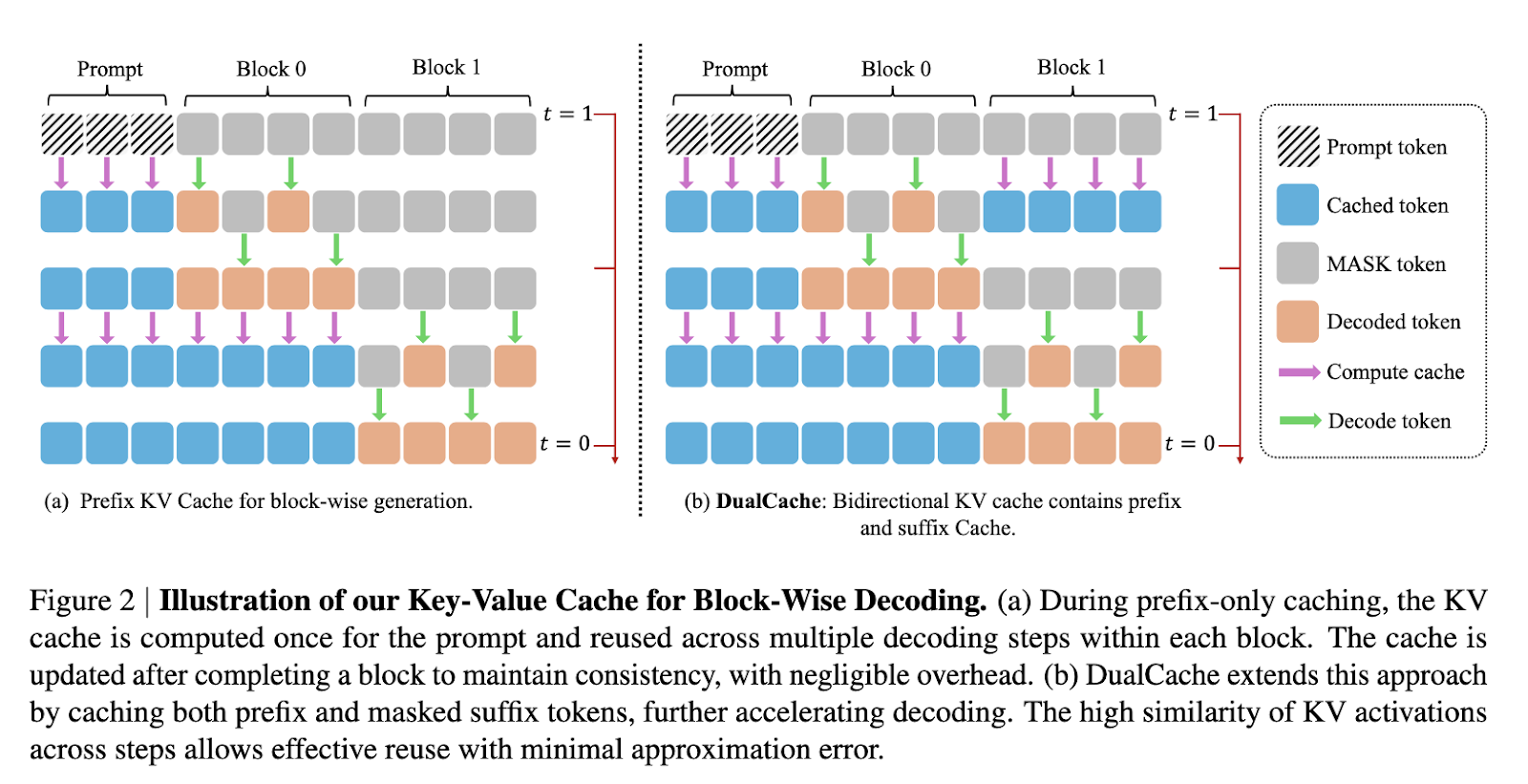
In the inferior, how cache method of fast-DLM is applied by dividing sequences into blocks. Before producing a block, how activists are calculated and stored for other blocks, enabling reuse during subsequent decoding steps. After the block is produced, the cache is updated to all tokens, which reduces the futility of calculation while maintaining accuracy. Cosine similarity in the paper expands this approach by taking advantage of the similarity between adjacent steps, caching both the prefix and the tokens, as shown by the heatmaps. For a parallel decoding component, the system evaluates the confidence of each token and decodes the same more than just the set threshold. This ensures high quality pay -generation even when multiple tokens are decoded in a single step.

Fast-DLM improved significantly in benchmark tests. On the GSM8K dataset, for example, he received 27.6 × speedup on baseline models in 8-shot Toter configurations at the length of 1024 tokens, with an accuracy of 76.0%. On a benchmark of mathematics, 6.5 × speedup was obtained with an accuracy of about 39.3%. Humanwal benchmark saw 2.5 × acceleration with an accuracy of 54..3%, while at MBPP, the system achieved 7.8 × speedup at the length of 512 tokens. In all functions and models, the accuracy remains within 1-2 points of the baseline, showing that the acceleration of fast-DLM does not significantly reduce the quality.
The Research Team effectively addressed the major barriers to diffusion based LLMS by introducing novel caching strategy and confidence -based decoding mechanism. By addressing the inability of estimates and increasing the quality of decoding, Fast-DLM shows how Ore can contact or surpass Torrentive models, making them appropriate for deployment in real-world language generation applications while maintaining LLM Sech accuracy.
Check paper and project page . All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 95K+ ML Subredit And subscribe Our newsletter.
Nikhil is an intern consultant at MarketechPost. He is gaining a dual degree in materials in the technology of the Indian organization in Kharagpur. Nikhil AI/ML is enthusiastic that always researches application in areas such as biometrials and biomedical vigels. With a strong background in the physical expression, he is looking for new progress and chances of contributing.