
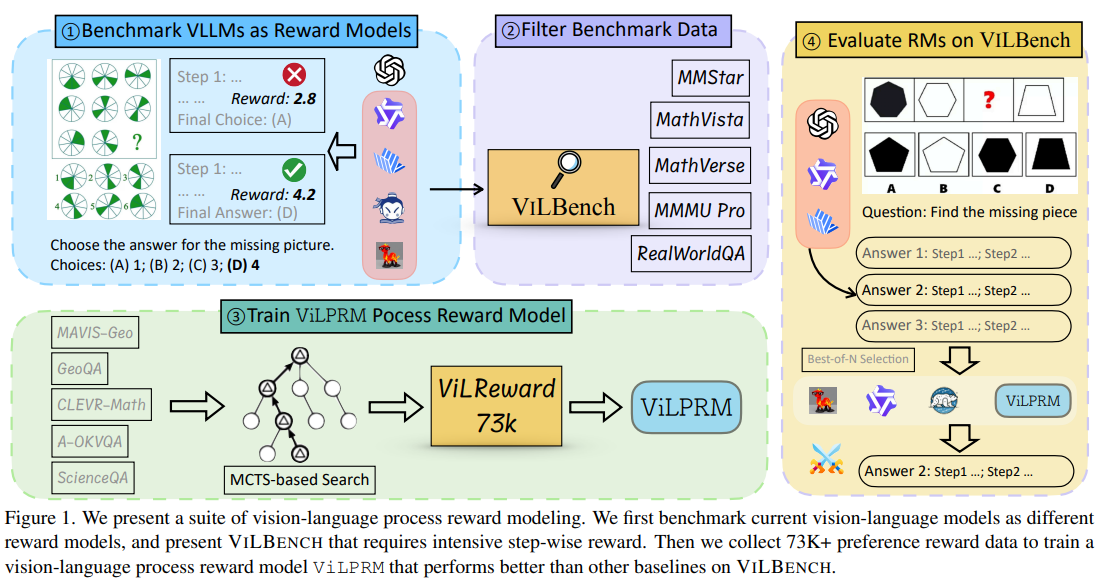
विज़न-लिंग पुरस्कार मॉडल के लिए आगे: चुनौतियां, बेंचमार्क और भूमिका-संरक्षण शिक्षा भूमिका
प्रक्रिया वाले पुरस्कार मॉडल (PRM) जटिल कार्यों के लिए एक प्रभावी तर्क पथ का चयन करने में मदद करते हैं, मॉडल के उत्तरों के लिए एक ठीक-ठीक दानेदार, कदम-वार प्रतिक्रिया।

एलएलएम रूटिंग के लिए एक व्यापक गाइड: टूल्स और फ्रेमवर्क
परिनियोजन LLMS चुनौतियों को प्रस्तुत करता है, विशेष रूप से izing, गणना लागत का प्रबंधन, और उच्च गुणवत्ता वाले प्रभाव को सुनिश्चित करने में। एलएलएम रूटिंग इन चुनौतियों के लिए

जोसेफ मार्विन इंपीरियल के साथ साक्षात्कार: तकनीकी मानकों के साथ जनरेटिव एआई
इस साक्षात्कार श्रृंखला में, हम अपने शोध के बारे में अधिक जानने के लिए कुछ AAAI/SIGAI डॉक्टरेट कंसोर्टियम प्रतिभागियों से मिल रहे हैं। डॉक्टरेट कंसोर्टियम पीएचडी के छात्रों का एक
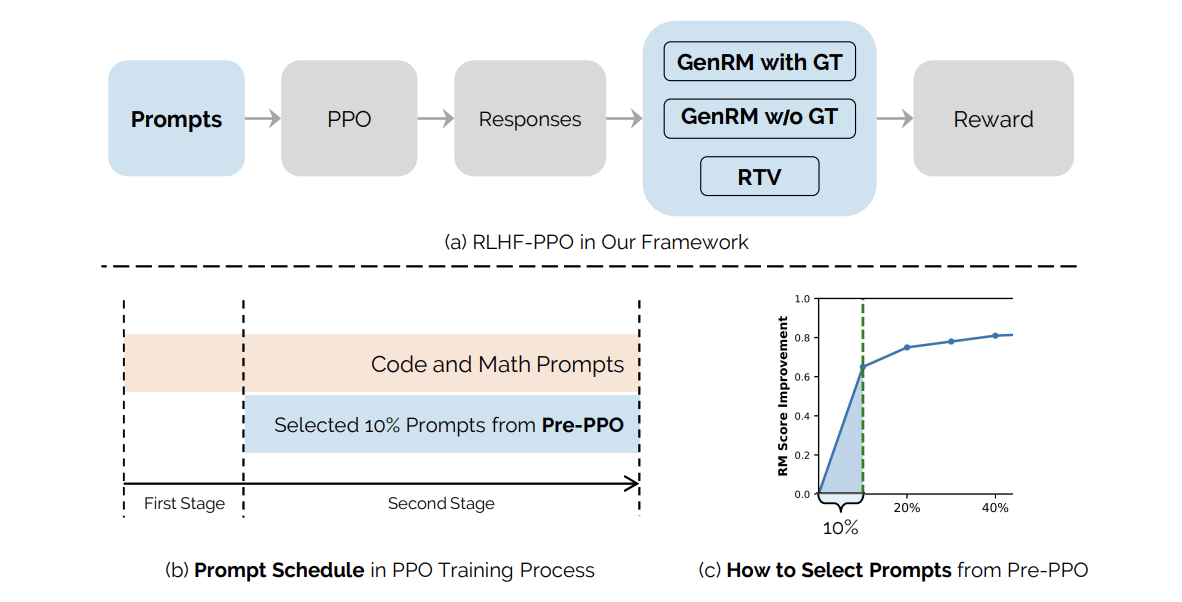
Bidendens का यह AI पेपर तर्कसंगत कार्य वेरिफायर (RTV) को कम करने और पुरस्कार मॉडल (GNRM) पुरस्कार हैकिंग को कम करने के लिए एक हाइब्रिड पुरस्कार प्रणाली का परिचय देता है
मानव प्रतिक्रिया (RLHF) से सुदृढीकरण शिक्षा मानव मूल्यों और वरीयताओं के साथ LLM के आयोजन के लिए महत्वपूर्ण है। डीपीओ गैर -आरएल विकल्पों को पेश करने के बावजूद, उद्योग के

अगला मशीन लर्निंग और एआई सेमिनार: अप्रैल 2025 संस्करण
यह पोस्ट AI- संबंधित सेमिनारों को सूचीबद्ध करती है जो 1 अप्रैल से 31 मई, 2025 के बीच आयोजित होने वाली हैं। यहां सभी घटनाओं के बारे में विस्तार से

मिलिए रिसर्च: एक उपन्यास एआई फ्रेमवर्क जो लॉजिक स्टेप्स पर किसी भी देखे गए डेटा का उपयोग किए बिना सुदृढीकरण शिक्षा के माध्यम से एक खोज के साथ एलएलएम को प्रशिक्षित करता है
बड़ी भाषा मॉडल डेलो (एलएलएमएस) ने विभिन्न कार्यों में महत्वपूर्ण प्रगति दिखाई है, विशेष रूप से तर्क क्षमताओं में। हालांकि, बाहरी पहचान संचालन के साथ तर्क प्रक्रियाओं को प्रभावी ढंग

ऐ विजय। मनो के लिए एक शक्तिशाली उपकरण हो सकता है। लेकिन यह भी अनुसंधान कदाचार को ईंधन दे सकता है
नादिया पीट और AI + AIXDIZINE / मॉडल फॉल / CC-BUY 4.0 द्वारा लाइसेंस प्राप्त की गई छवियां जॉन व्हीट द्वारा, सीएसआईआरओ और स्टीफन हेरर, सीएसआईआरओ इस साल फरवरी में,

बार मेस एसीएम सिग्ची लाइफटाइम रिसर्च अवार्ड प्राप्त करता है | मीट न्यूज
MIT के मीडिया आर्ट्स एंड साइंस जर्मशस प्रोफेसर और MIT मीडिया लैब, Patta मेस में द्रव इंटरफ़ेस रिसर्च ग्रुप के प्रमुख को 2025 ACM SIGCHI LifeTime Research अवार्ड दिया गया

GDPR अनुपालन के लिए कानूनी डोमेन एलएलएम आउटपुट स्कोर करने के लिए पायथन एसडीके द्वारा एटीएल के मूल्यांकन मंच और सेलेन मॉडल का उपयोग करके कोड कार्यान्वयन
इस ट्यूटोरियल में, हम दिखाते हैं कि प्राकृतिक भाषा मानदंड के साथ मूल्यांकन वर्कफ़्लो को स्वचालित करने के लिए एक शक्तिशाली उपकरण, पायथन एसडीके का उपयोग करके एलएलएम-जनित उत्तरों की
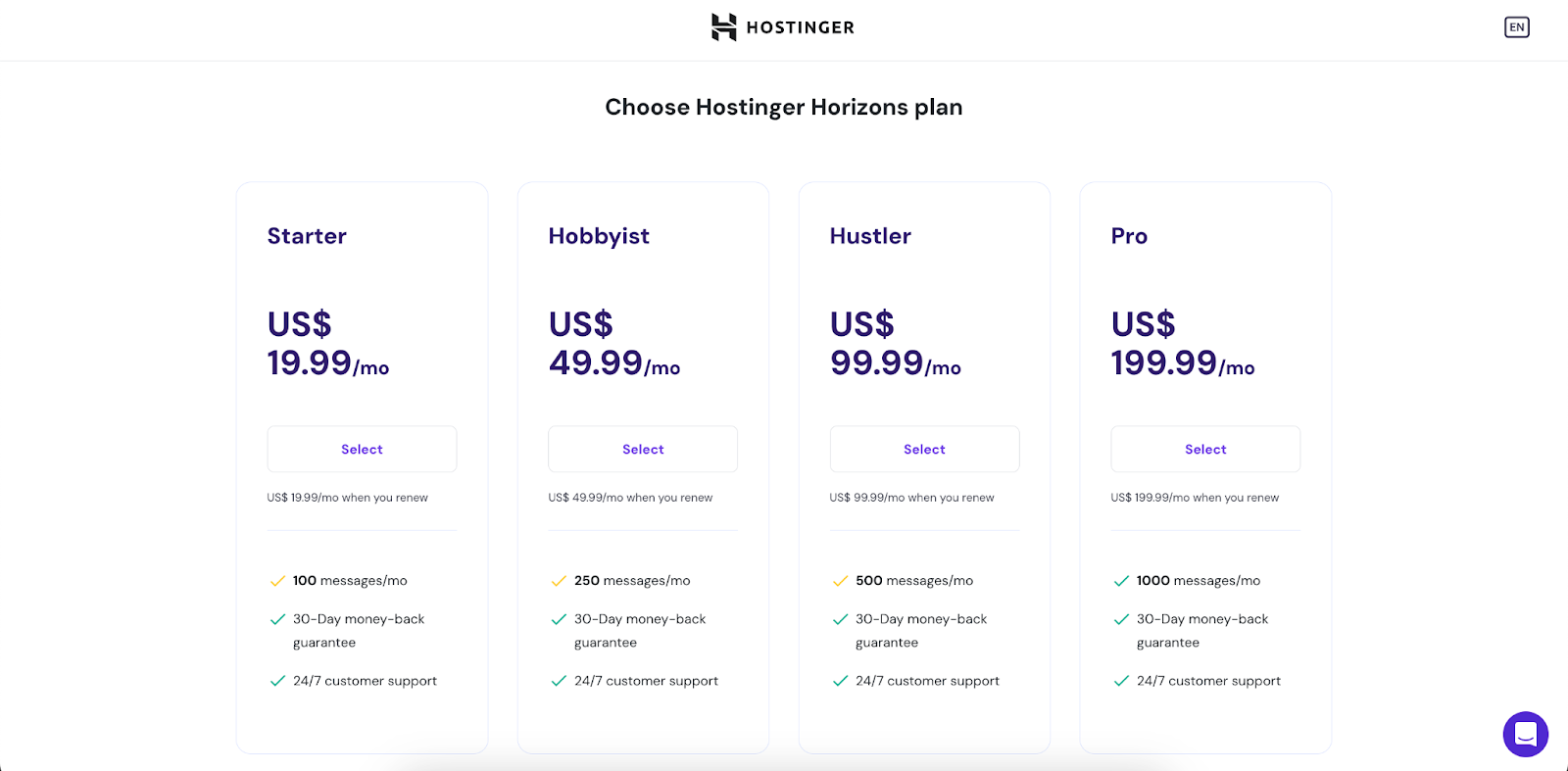
होस्टर क्षितिज से मिलें: नो-कोड एआई टूल जो आपको कोड की एक पंक्ति लिखने के बिना कस्टम वेब एप्लिकेशन बनाने, संपादित करने और प्रकाशित करने की अनुमति देता है।
वेब विकास के बढ़ते परिदृश्य में, नो-कोड प्लेटफार्मों के उद्भव ने एप्लिकेशन निर्माण में काफी वृद्धि की है। इस में, होस्टिंग क्षितिज किसी भी कोडिंग कौशल की आवश्यकता के बिना
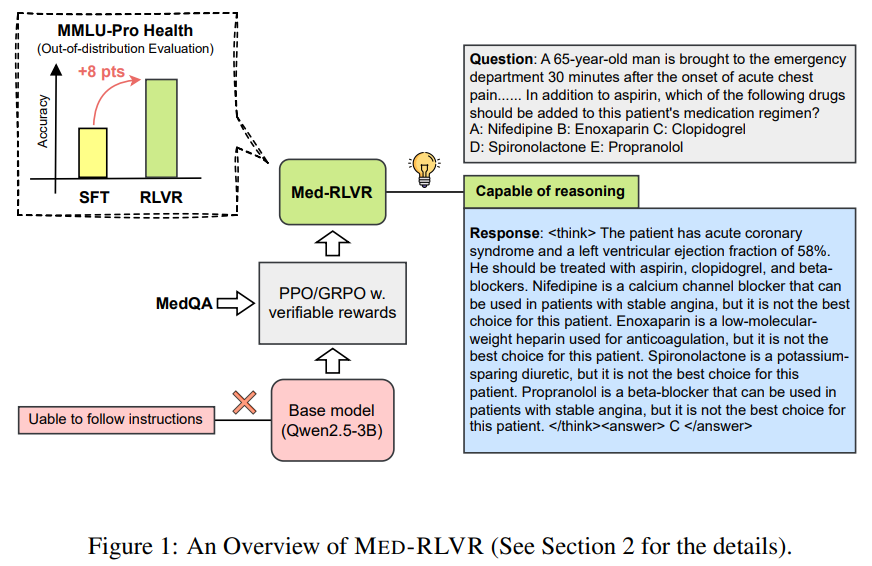
सत्यापित रिवार्ड्स (RLVR) से सुदृढीकरण शिक्षा के साथ चिकित्सा तर्क के लिए: MED-RLVR अंतर्दृष्टि
सत्यापित रिवार्ड्स (RLVR) से सुदृढीकरण शिक्षा हाल ही में प्रत्यक्ष पर्यवेक्षण के बिना भाषा के मॉडल में तर्क क्षमता बढ़ाने के लिए एक आशाजनक विधि के रूप में उभरी है।
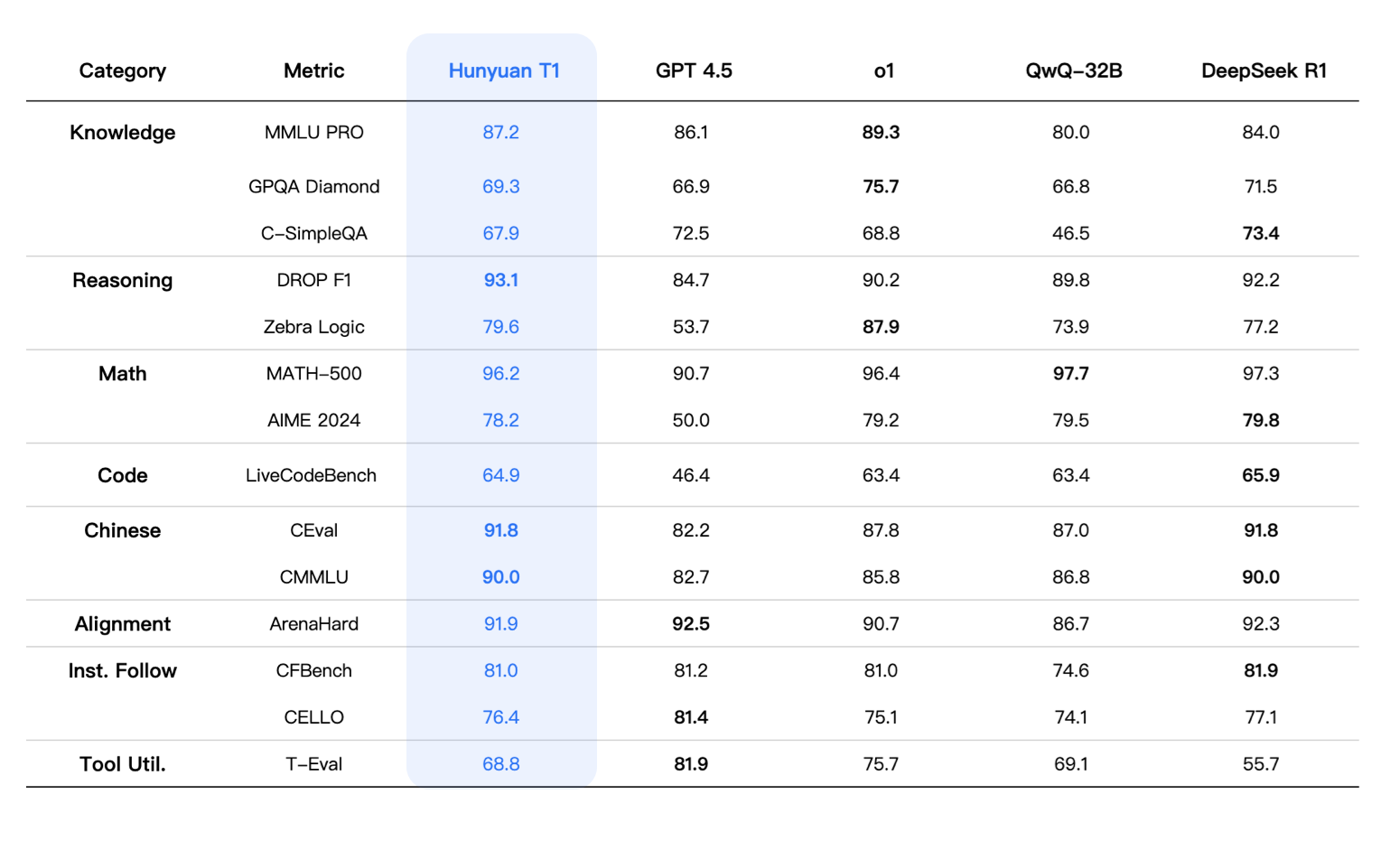
टेंसेंट एआई शोधकर्ताओं ने हुनुआन-टी 1 का परिचय दिया: एक माम्बा-संचालित अल्ट्रा-बिग भाषा मॉडल, डीप पंडो लॉजिक, जिसमें संदर्भित दक्षता और मानव-केंद्रित सुदृढीकरण शिक्षा का उल्लेख है।
बड़ी भाषा मॉडल डेलस आवश्यक संदर्भ को खोए बिना लंबे, जटिल ग्रंथों की प्रक्रिया और कारण के लिए संघर्ष करता है। पारंपरिक मॉडल अक्सर संदर्भ के नुकसान से पीड़ित होते
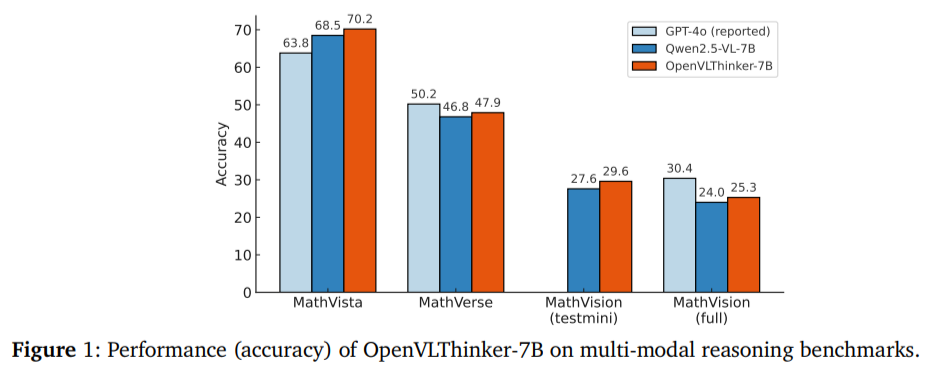
UCLA शोधकर्ता OpenVilthinker-7B प्रकाशित करते हैं: मल्टीमॉडल सिस्टम में जटिल दृश्य तर्क और चरण-दर-चरण समस्या को बढ़ाने के लिए एक सुदृढीकरण शिक्षा-आधारित मॉडल
बड़े विजन मॉडल डेल्स (LVLMS) छवि प्रसंस्करण क्षमताओं के साथ बड़े भाषा मॉडल को एकीकृत करते हैं, उन्हें छवियों की व्याख्या करने और संगत पाठ प्रतिक्रिया का उत्पादन करने में
Google AI ने दवा विकास के लिए कई चिकित्सीय कार्यों के लिए TXGMMA: 2B, 9B और 27B रेंज पेश की, ट्रांसफार्मर के साथ ठीक-ठीक
चिकित्सीय विकसित करना एक स्वाभाविक रूप से महंगा और चुनौतीपूर्ण प्रयास है, जिसमें उच्च विफलता दर और लंबे समय तक विकास की समयरेखा है। पारंपरिक दवा खोज प्रक्रिया को देर

ओपन डीप सर्च (ओडीएस) से मिलें: ओपन सोर्स लॉजिक एजेंट्स डेमोक्रेटाइजेशन सर्च के साथ प्लग-एंड-प्ले फ्रेमवर्क
बड़े -लैंगुएज मॉडल डेलो (एलएलएमएस) से जुड़ी खोज इंजन तकनीकों में तेजी से प्रगति ने Google के GPT -4O खोज पूर्वावलोकन और सोनार लॉजिक प्रो जैसे मुख्य रूप से स्वामित्व

एआई रिंग स्पेल वर्ड्स इन अमेरिकन साइन लैंग्वेज
Hyochul Lim एक जादू पहनता है। फोटो क्रेडिट: लुईस दीपिट्रो लुईस डेपट्रो द्वारा कॉर्नेल की अगुवाई वाली शोध टीम ने माइक्रो-सोरोर तकनीक से लैस एक कृत्रिम बुद्धिमत्ता-संचालित रिंग विकसित की