

ट्रांसफार्मर मॉडल डेलो ने उभरते गुणों के साथ बड़े -स्केल टेक्स्ट पीढ़ी को सक्षम करके भाषा मॉडलिंग को बदल दिया है। हालांकि, वे उन कार्यों के साथ संघर्ष करते हैं जिनके लिए व्यापक योजना की आवश्यकता होती है। शोधकर्ताओं ने लक्ष्यों को प्राप्त करने की अपनी क्षमता में सुधार करने के लिए वास्तुकला, उद्देश्यों और एल्गोरिदम में बदलाव का आविष्कार किया है। जैसा कि पिछले और भविष्य की जानकारी पर प्रशिक्षित मॉडल में देखा गया है, कुछ दृष्टिकोण द्विपक्षीय संदर्भ को शामिल करके पारंपरिक वाम-से-दाएं अनुक्रम मॉडलिंग से परे जाते हैं। अन्य लोग ऑप्टिमेंट पर पीटी करने की कोशिश करते हैं, जैसे कि सुप्त-से-बाइनरी ट्री-आधारित डिकोडिंग, हालांकि बाएं-से-दाएं अयस्क टोरेंटिव तरीके अक्सर सबसे अच्छे होते हैं। एक और हालिया दृष्टिकोण में, ट्रांसफार्मर को संयुक्त रूप से और पिछड़े डिकोडिंग के लिए प्रशिक्षित किया जाता है, जो कॉम्पैक्ट विश्वास राज्यों को बनाए रखने के लिए मॉडल की क्षमता को बढ़ाता है।
हमने आगे अनुसंधान दक्षता में सुधार करने के लिए एक साथ कई टोकन भविष्यवाणियों का पता लगाया है। कुछ मॉडलों को एक समय में एक से अधिक टोकन बनाने के लिए डिज़ाइन किया गया है, जिससे तेजी से और अधिक मजबूत टेक्स्ट पे जेनरेशन होता है। बहु-टोकन पूर्वानुमानों पर pritraining को बड़े पैमाने पर प्रदर्शन बढ़ाने के लिए दिखाया गया है। एक अन्य प्रमुख अंतर्दृष्टि यह है कि ट्रांसफॉर्मर गैर-बाध्यकारी के विश्वास को अपने अवशिष्ट प्रवाह में बदल देते हैं। इसके विपरीत, राज्य से ढके मॉडल अधिक कॉम्पैक्ट प्रतिनिधित्व प्रदान करते हैं लेकिन व्यापार के साथ आते हैं। उदाहरण के लिए, कुछ प्रशिक्षण संरचनाएं विशिष्ट ग्राफ संरचनाओं के साथ संघर्ष करती हैं, मौजूदा तरीकों में सीमाओं का खुलासा करती हैं। ये निष्कर्ष बेहतर संरचित और कुशल अनुक्रम मॉडलिंग के लिए ट्रांसफार्मर आर्किटेक्चर को शुद्ध करने के लिए चल रहे प्रयासों को उजागर करते हैं।
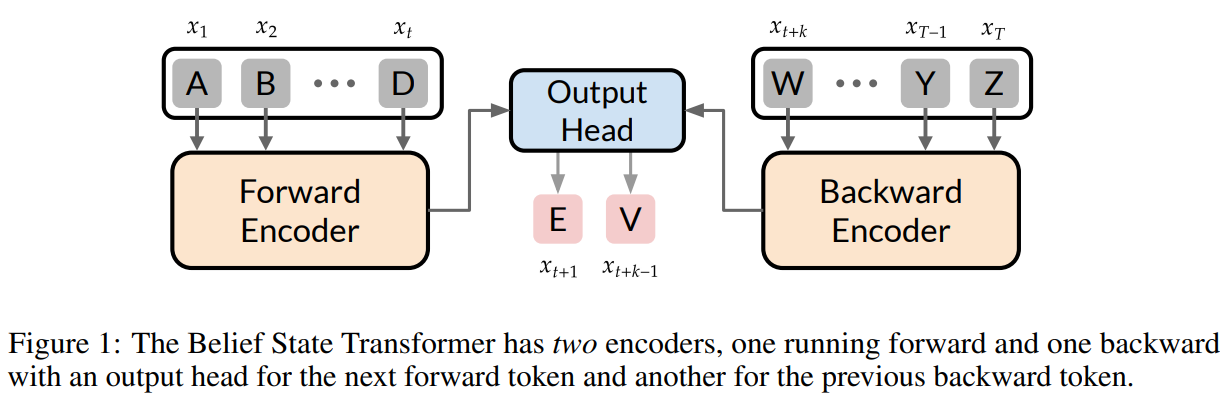
Micros .ft रिसर्च, पेंसिल्वेनिया विश्वविद्यालय, UT ऑस्ट स्टीन और अल्बर्टा विश्वविद्यालय ने मान्यता राज्य ट्रांसफार्मर (BST) की शुरुआत की। यह मॉडल उपसर्ग और प्रत्यय दोनों को देखते हुए आगामी-टोकन पूर्वानुमानों को बढ़ाता है। मानक ट्रांसफॉर्मर के विपरीत, बीएसटी द्विपक्षीय रूप से जानकारी को एनकोड करता है, उपसर्ग के बाद अगले टोकन की भविष्यवाणी करता है, और प्रत्यय से पहले पिछले टोकन। यह दृष्टिकोण चुनौतीपूर्ण कार्यों पर प्रभाव में सुधार करता है, जैसे कि लक्ष्य-स्थिति वाली पाठ उत्पादन और स्टार ग्राफ जैसी संरचित पूर्वानुमान समस्याएं। एक कॉम्पैक्ट विश्वास स्थिति सीखकर, बीएसटी अनुक्रम मॉडलिंग में पारंपरिक तरीकों की ओर जाता है, बड़े -स्केल अनुप्रयोगों के लिए आशाजनक प्रभाव के साथ अधिक कुशल अनुमान और मजबूत पाठ अभ्यावेदन प्रदान करता है।
पारंपरिक नेक्स्ट-टोकन पूर्वानुमान मॉडल के विपरीत, बीएसटी को आगे और पिछड़े दोनों एन्कोडर्स को एकीकृत करके सीक्वेंस मॉडलिंग को बढ़ाने के लिए डिज़ाइन किया गया है। यह उपसर्ग के लिए फ्रंट एनकोडर और प्रत्यय के लिए पिछड़े एनकोडर का उपयोग करता है, अगले और पिछले टोकन की भविष्यवाणी करता है। यह दृष्टिकोण मॉडल को शॉर्टकट रणनीतियों को अपनाने से रोकता है और लंबी निर्भरता शिक्षा में सुधार करता है। बीएसटी स्टार ग्राफ नेविगेशन में बेसलाइन को बेहतर बनाता है, जहां केवल फ्रंट ट्रांसफॉर्मर संघर्ष करते हैं। Abulations इस बात की पुष्टि करते हैं कि राज्य -of -th -art और पिछड़े एनकोडर प्रभाव के लिए सत्यापन आवश्यक है। अनुमान के दौरान, बीएसटी ने पिछड़े एनकोडर को बाहर कर दिया, लक्ष्य-वातानुकूलित व्यवहार को सुनिश्चित करते समय दक्षता बनाए रखा।
केवल फ्रंट और मल्टी-टोकन मॉडल के विपरीत, बीएसटी प्रभावी रूप से एक कॉम्पैक्ट विश्वास स्थिति बनाता है। राज्य की स्थिति भविष्य की भविष्यवाणियों के लिए सभी आवश्यक जानकारी को एन्कोड करती है। BSTA संयुक्त मॉडलिंग उपसर्गों और प्रत्यय द्वारा इस तरह के अभ्यावेदन सिखाता है, जिससे लक्ष्य-वातानुकूलित पाठ पीढ़ी को सक्षम होता है। टिनिस्टरी का उपयोग करने वाले प्रयोग बीएसटी को दर्शाते हैं, अधिक सुसंगत और संरचनात्मक कथन का उत्पादन करते हैं, जो एम-इन-द-मिडिल (FIM) मॉडल को आगे बढ़ाते हैं। GPT -4 के साथ मूल्यांकन BST की सबसे अच्छी कहानी बताने की क्षमता प्रदर्शित करता है, जिसमें उपसर्ग, उत्पन्न पाठ और प्रत्यय के बीच स्पष्ट संबंध हैं। इसके अलावा, बीएसटी उच्च संभावना के अंत के साथ अनुक्रमों का चयन करके, बिना शर्त पाठ पीढ़ी को बिना शर्त पाठ पीढ़ी में सबसे अच्छा है जो पारंपरिक आगामी-टोकन भविष्यवाणियों पर इसके लाभों को दर्शाता है।
अंत में, BST पारंपरिक ललाट मॉडल की सीमाओं को संबोधित करके लक्ष्य-शर्त अगले पूर्वानुमान में सुधार करता है। यह एक कॉम्पैक्ट विश्वास स्थिति बनाता है, जो भविष्य की भविष्यवाणियों के लिए सभी आवश्यक जानकारी को एन्कोड करता है। पारंपरिक ट्रांसफॉर्मर के विपरीत, बीएसटी एक उपसर्ग के लिए अगले टोकन और प्रत्यय के लिए पिछले टोकन की भविष्यवाणी करता है, जिससे यह जटिल कार्यों में अधिक प्रभावी हो जाता है। अनुभवजन्य परिणाम कहानी लेखन में इसके लाभ दिखाते हैं, जिससे फिलिंग-इन-द-मेडियम दृष्टिकोण होता है। जबकि हमारे प्रयोग छोटे पैमाने पर कार्यों पर इसके प्रभाव को मान्य करते हैं, इसकी स्केलेबिलिटी और व्यापक लक्ष्य-वातानुकूलित समस्याओं, दक्षता और अनुमान की गुणवत्ता का पता लगाने के लिए अधिक शोध की आवश्यकता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली
मार्कटेकपोस्ट और आईआईटी मद्रास में एक परामर्श इंटर्न सना हसन, वास्तविक दुनिया की चुनौतियों को दूर करने के लिए प्रौद्योगिकी और एआई को लागू करने के बारे में उत्साहित हैं। व्यावहारिक समस्याओं को हल करने में अधिक रुचि के साथ, यह एआई और वास्तविक जीवन समाधानों के चौराहे के लिए एक नया परिप्रेक्ष्य लाता है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)

