

मल्टीमॉडल एआई एजेंटों को डिजिटल और भौतिक वातावरण में कार्यों को करने के लिए विभिन्न डेटा प्रकारों जैसे छवियों, पाठ और वीडियो को संसाधित करने और एकीकृत करने के लिए डिज़ाइन किया गया है। इसका उपयोग रोबोटिक्स, वर्चुअल असिस्टेंट और यूजर इंटरफेस ऑटो टमाटर में किया जाता है, जहां उन्हें जटिल मल्टीमॉडल इनपुट के आधार पर समझने और काम करने की आवश्यकता होती है। इन प्रणालियों का उद्देश्य मौखिक और स्थानिक खुफिया को खत्म करना है, जो गहरी शिक्षण तकनीकों का लाभ देता है, कई डोमेन में इंटरैक्शन को सक्षम करता है।
एआई सिस्टम अक्सर दृष्टि-भाषा की समझ या रोबोट हेरफेर के विशेषज्ञ होते हैं, लेकिन एक मॉडल में इन क्षमताओं को संयोजित करने के लिए संघर्ष करते हैं। कई एआई मॉडल को डोमेन-विशिष्ट कार्यों के लिए डिज़ाइन किया गया है, जैसे कि यूआई नेविगेशन में शारीरिक तस्करी या डिजिटल वातावरण में रोबोटिक्स, विभिन्न अनुप्रयोगों में उनके सामान्यीकरण को सीमित करते हुए। कई तरीकों को समझने और एकीकृत मॉडल को समझने के लिए चुनौती विकसित की जाती है, संरचनात्मक और असंरचित वातावरण में प्रभावी निर्णयों की गारंटी दी जाती है।
मौजूदा विजन-लैंग्वेज-एक्शन श्रेणी (VLA) मॉडल विज़न-लैंग्वेज जोड़ी के बड़े डेटासेट पर मुद्रण करके मल्टीमॉडल कार्यों को संबोधित करने का प्रयास करते हैं, इसके बाद एक्शन ट्रैक्टरी डेटा होता है। हालांकि, इन मॉडलों में आम तौर पर विभिन्न वातावरणों में अनुकूलनशीलता की कमी होती है। उदाहरणों में PIX2 ACT और वेब गम शामिल हैं, जो UI नेविगेशन में सबसे अच्छा है, और OpenVla और RT -2, जो रोबोटिक हेरफेर के लिए ऑप्टिमेट Ptimaise है। इन मॉडलों को अक्सर अलग -अलग प्रशिक्षण प्रक्रियाओं की आवश्यकता होती है और डिजिटल और भौतिक दोनों वातावरण को सामान्य करने में विफल रहते हैं। इसके अलावा, पारंपरिक मल्टीमॉडल मॉडल स्थानिक और लौकिक बुद्धिमत्ता को एकीकृत करने के लिए संघर्ष करते हैं, अपने जटिल कार्यों को स्वायत्त रूप से करने की उनकी क्षमता को सीमित करते हैं।
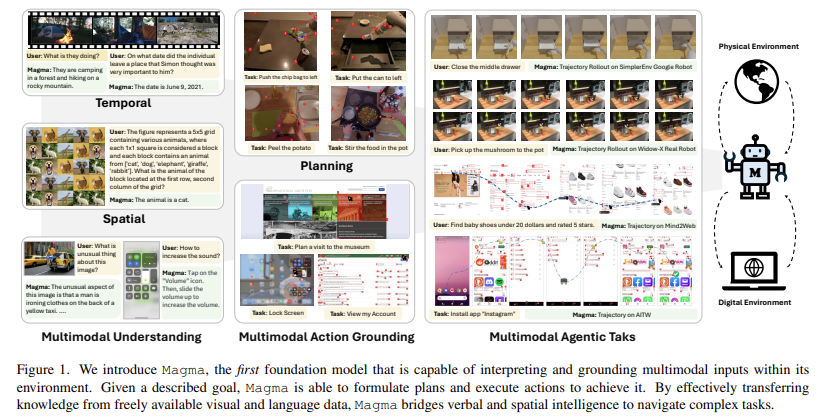
माइक्रोस विश्वविद्यालय के शोधकर्ता ।फिफ्ट रिसर्च, मैरीलैंड विश्वविद्यालय, यूनिवर्सिटी ऑफ विस्कॉन्सिन-मेडिसन कास्ट और वाशिंगटन शिंगटन बादलनिष्पादन के साथ मल्टीमॉडल समझ को एकीकृत करने के लिए डिज़ाइन किया गया एक फाउंडेशन मॉडल एआई एजेंटों को डिजिटल और भौतिक वातावरण में एकीकृत अधिनियम करने में सक्षम बनाता है। मैग्मा को मौजूदा वीएलए मॉडल की कमियों को दूर करने के लिए डिज़ाइन किया गया है, जिसमें मल्टीमॉडल अंडरस्टैंडिंग, एक्शन ग्राउंडिंग और प्लानिंग के साथ एक मजबूत प्रशिक्षण पद्धति शामिल है। मैग्मा को विभिन्न प्रकार के डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, जिसमें छवियां, वीडियो और रोबोटिक एक्शन ट्रैक्टरीज शामिल हैं। इसमें दो उपन्यास तकनीकें शामिल हैं,
- SET-F-MARK (SOM): SOM मॉडल को निष्पादित करने के लिए सक्षम करता है दृश्य वस्तुओं को निष्पादित करें, जैसे कि UI वायुमंडल में बटन
- TRACE-F-MARK (TOM): TOM उसे ऑब्जेक्ट Bubject गतिविधियों का TRAC करने की अनुमति देता है और तदनुसार भविष्य के कार्यों के लिए योजना बनाता है
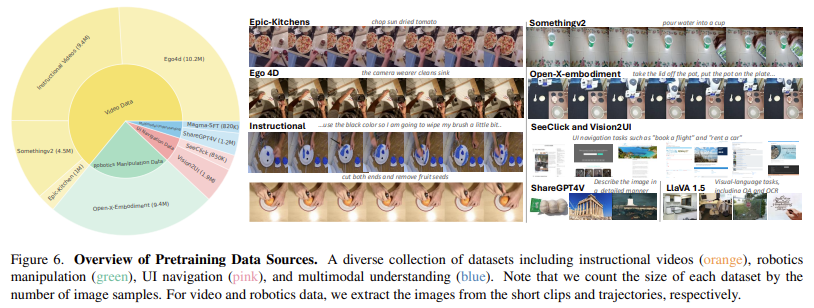
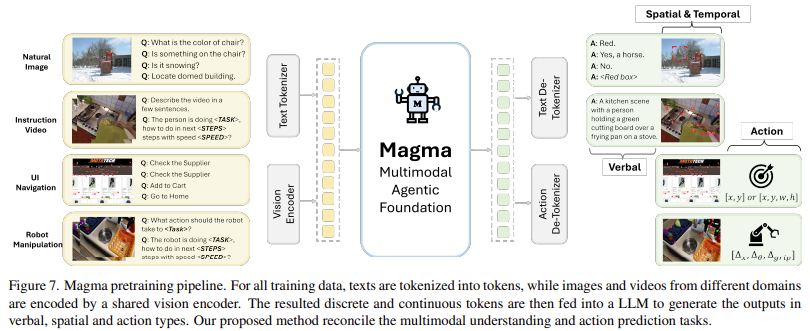
मैग्मा गहरी पांडा शिक्षा आर्किटेक्ट्स और व्यापक मुद्रण के संयोजन को कई डोमेन में अपने प्रभाव को बढ़ाने के लिए नियोजित करता है। यह मॉडल छवियों और वीडियो को संसाधित करने के लिए Exempt-XXL विज़न बैकबोन का उपयोग करता है, जबकि LAMA-3-8B भाषा मॉडल पाठ्य इनपुट को संभालता है। यह आर्किटेक्चर मैग्मा को एक्शन निष्पादन के साथ विज़न-लैंग्वेज समझ को एकीकृत करने में सक्षम बनाता है। यह एक क्यूरेट किए गए डेटासेट पर प्रशिक्षित है, जिसमें CCLIC और विजन 2 UI के UI नेविगेशन फ़ंक्शंस, ओपन-X-AMBODEMENT के रोबोटिक हेरफेर डेटासेट और EGO4D, कुछ-precaed V2, और EPIC-Kitchen जैसे स्रोतों से निर्देशात्मक वीडियो शामिल हैं। SOM और TOM का लाभ देकर, मैग्मा निरीक्षण दृश्य अनुक्रमों के आधार पर भविष्य के कार्यों की भविष्यवाणी करने की अपनी क्षमता को बढ़ाते हुए UI स्क्रीनशॉट और रोबोटिक्स डेटा से प्रभावी ढंग से एक्शन ग्राउंडिंग सीख सकता है। प्रशिक्षण के दौरान, मॉडल 2.7 मिलियन यूआई स्क्रीनश शॉट्स टीएस, 970,000 रोबोटिक त्रासदी और 25 मिलियन से अधिक वीडियो नमूनों को मजबूत मल्टीमॉडल शिक्षा सुनिश्चित करने के लिए संसाधित करता है।
शून्य-शॉट टीयू यूआई नेविगेशन कार्यों में, मैग्मा ने 57.2%के मौलिक चयन की सटीकता प्राप्त की, जैसे कि जीपीटी -4 वी-ओम्निपर और चक्रीय जैसे मॉडल को बेहतर बनाया। रोबोटिक हेरफेर कार्यों में, मैग्मा ने Google रोबोट फ़ंक्शंस में 52.3% और ब्रिज सिमुलेशन में 35.4% की सफलता दर हासिल की, जिसने OpenVLA को काफी पार कर लिया, जिसने एक ही बेंचमार्क में केवल 31.7% और 15.9% हासिल किया। मॉडल ने मल्टीमॉडल अंडरस्टैंडिंग कार्यों में असाधारण प्रदर्शन किया, जिसमें WQ V2 में 80.0% सटीकता, TextVQA में 66.5% और POP मूल्यांकन में 87.4% है। मैग्मा ने बेंचमार्क पर ब्लिंक डेटासेट .8 74..8% और विजुअल स्पैटियल लॉजिक (वीएसआर) पर मजबूत स्थानिक तर्क क्षमताओं को भी दिखाया। वीडियो प्रश्न-उत्तरदायी कार्यों में, मैग्मा ने इरादे और NXTU .9..9% पर 88.6% हासिल किया, जो प्रभावी रूप से अस्थायी जानकारी को संसाधित करने की अपनी क्षमता को उजागर करता है।
कुछ प्रमुख टेकवे मैग्मा पर शोध से उभरते हैं:
- मैग्मा को 39 मिलियन मल्टीमॉडल टेम्पलेट्स पर प्रशिक्षित किया गया था, जिसमें 2.7 मिलियन यूआई स्क्रीनशॉट, 970,000 रोबोटिक सड़कें और 25 मिलियन वीडियो नमूने शामिल थे।
- मॉडल डोमेन-विशिष्ट एआई मॉडल की सीमाओं को समाप्त करते हुए, एक एकीकृत संरचना में दृष्टि, भाषा और कार्रवाई को जोड़ती है।
- SOM क्लिक करने योग्य ऑब्जेक्ट्स bejects की सटीक लेबलिंग को सक्षम करता है, जबकि टॉम समय के साथ ऑब्जेक्ट की गति को ट्रैक करने की अनुमति देता है, जो एक लंबी योजना की क्षमता में सुधार करता है।
- मैग्मा ने यूआई कार्यों में तत्व चयन में 57.2% सटीकता दर, रोबोटिक हेरफेर में 52.3% सफलता दर और डब्ल्यूक्यू कार्यों में 80.0% सटीकता प्राप्त की है।
- मैग्मा ने मौजूदा एआई मॉडल को 19.6% से अधिक से अधिक आकाशीय लॉजिक बेंचमार्क में प्रभावित किया और वीडियो-आधारित तर्क में पिछले मॉडल के 28% में सुधार किया।
- मैग्मा ने अतिरिक्त फाइन-ट्यूनिंग की आवश्यकता के बिना कई कार्यों में सर्वश्रेष्ठ सामान्यीकरण का प्रदर्शन किया, जिससे यह एक बहुत ही अनुकूली एआई एजेंट बन गया।
- मैग्मा की क्षमताएं रोबोटिक्स, स्वायत्त प्रणालियों, यूआई स्वचालन, डिजिटल सहायकों और औद्योगिक शिथिलता एआई में निर्णय लेने और निष्पादन को बढ़ा सकती हैं।
जाँच करना कागज और परियोजना पृष्ठ। इस शोध के लिए सभी क्रेडिट इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एक एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
ASIF Razzaq एक दूरदर्शी उद्यमी और इंजीनियर के रूप में मार्केटएकपोस्ट मीडिया इंक के सीईओ हैं, ASIF सामाजिक अच्छे के लिए कृत्रिम बुद्धिमत्ता की संभावना को बढ़ाने के लिए प्रतिबद्ध है। उनका सबसे हालिया प्रयास आर्टिफिशियल इंटेलिजेंस मीडिया प्लेटफॉर्म, मार्कटेकपोस्ट का उद्घाटन है, जो मशीन लर्निंग की गहराई के लिए और कवरेज की गहराई के लिए गहरी सीखने की खबर के लिए है। यह तकनीकी रूप से ध्वनि है और एक बड़े दर्शकों द्वारा आसानी से समझ में आता है। प्लेटफ़ॉर्म में 2 मिलियन से अधिक मासिक दृश्य हैं, जो दर्शकों के बीच अपनी लोकप्रियता दिखाते हैं।



