


大型語言模型(LLM)廣泛用於醫學,促進診斷決策,患者分類,臨床報告和醫學研究工作流程。儘管它們在受控的醫療測試中非常出色,例如美國醫療許可檢查(USMLE),但他們對現實世界使用的實用性仍未經過良好測試。大多數現有的評估都取決於無法反映臨床實踐複雜性的合成基準。在去年的一項研究中,他們發現,僅5%的LLM分析依賴於實際世界患者信息,這揭示了測試現實世界可用性之間的巨大差異,並表明了確定它們在醫療決策中的可靠性,因此在醫療決策中的作用,因此也質疑安全性和在實際World臨床環境中使用的安全性。
最先進的評估方法主要是用合成數據集,結構化知識考試和正規體檢對語言模型進行評分。儘管這些考試測試了理論知識,但它們並不能反映具有復雜互動的實際患者情況。大多數測試會產生單一的度量結果,而無需關注關鍵細節,例如事實的正確性,臨床適用性和反應偏見的可能性。此外,廣泛使用的公共數據集是同質的,損害了對不同醫學專業和患者種群的概括。另一個主要的挫折是,大多數針對這些基準測試的模型表現出過度適合測試範例,因此在動態醫療保健環境中失去了大部分性能。缺乏包含現實世界患者互動的全系統框架進一步侵蝕了他們用於實際醫療用途的信心。
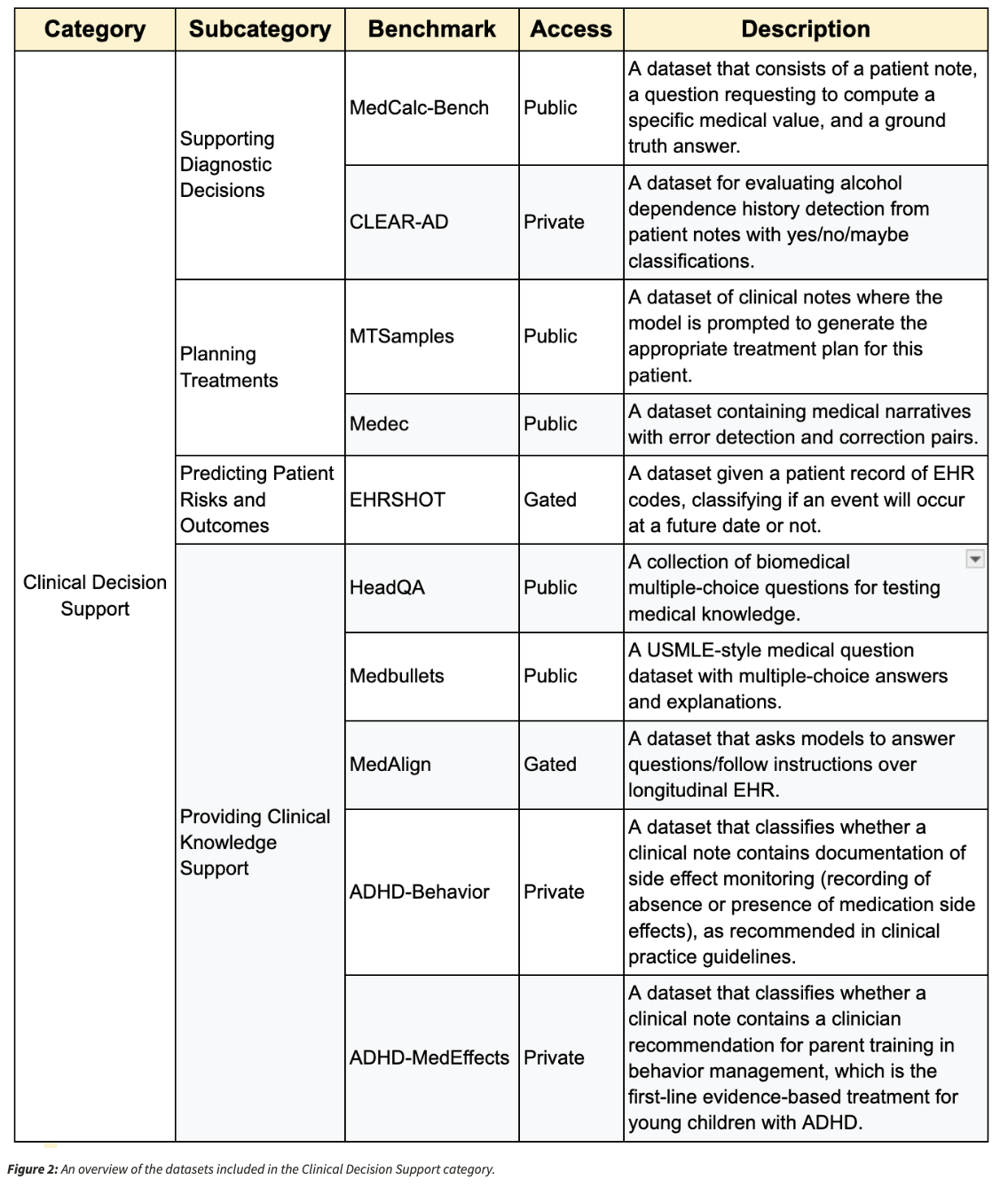
研究人員開發了Medhelm,這是一個詳盡的評估框架,旨在測試LLM,以防止實際醫療任務,多項式評估和專家修訂的基準測試,以解決這些差距。它以斯坦福大學對語言模型(Helm)的整體評估為基礎,並在五個主要領域進行了系統評估:
- 臨床決策支持
- 臨床筆記產生
- 病人的溝通和教育
- 醫學研究幫助
- 管理和工作流程
共有22個子類別和121項特定的醫療任務可確保對關鍵醫療保健應用的廣泛覆蓋。與較早的標準相比,MedHelm採用了實際的臨床數據,通過結構化和開放式任務評估模型,並應用了多方面的評分範例。整體覆蓋範圍使它不僅能夠衡量知識的回憶,而且能夠臨床適用性,推理精度和一般的日常實用性。
廣泛的數據集基礎架構為基準測試過程的基礎,其中包括31個數據集。該系列包括11個新開發的醫療數據集以及20個從既有的臨床記錄中獲得的。數據集涵蓋了各種醫療領域,從而確保評估準確地代表了現實世界中的醫療挑戰,而不是人為的測試場景。
數據集轉化為標準化參考的是一個系統的過程,其中涉及:
- 上下文定義:具體數據段該模型必須分析(例如,臨床註釋)。
- 提示策略:一種預定義的指導指導模型行為(例如,“確定患者的血囊分數”)。
- 參考響應:經過比較的臨床驗證輸出(例如,分類標籤,數值或基於文本的診斷)。
- 評分指標:用於文本相似性評估的精確匹配,分類準確性,BLEU,ROUGE和BERTSCORE的組合。
這種方法的一個例子是在Medcalc基座中,該方法測試了模型能夠執行臨床上重要的數值計算。每個數據輸入都包含患者的臨床病史,診斷性問題以及專家驗證的解決方案,從而對醫學推理和精度進行了嚴格的測試。
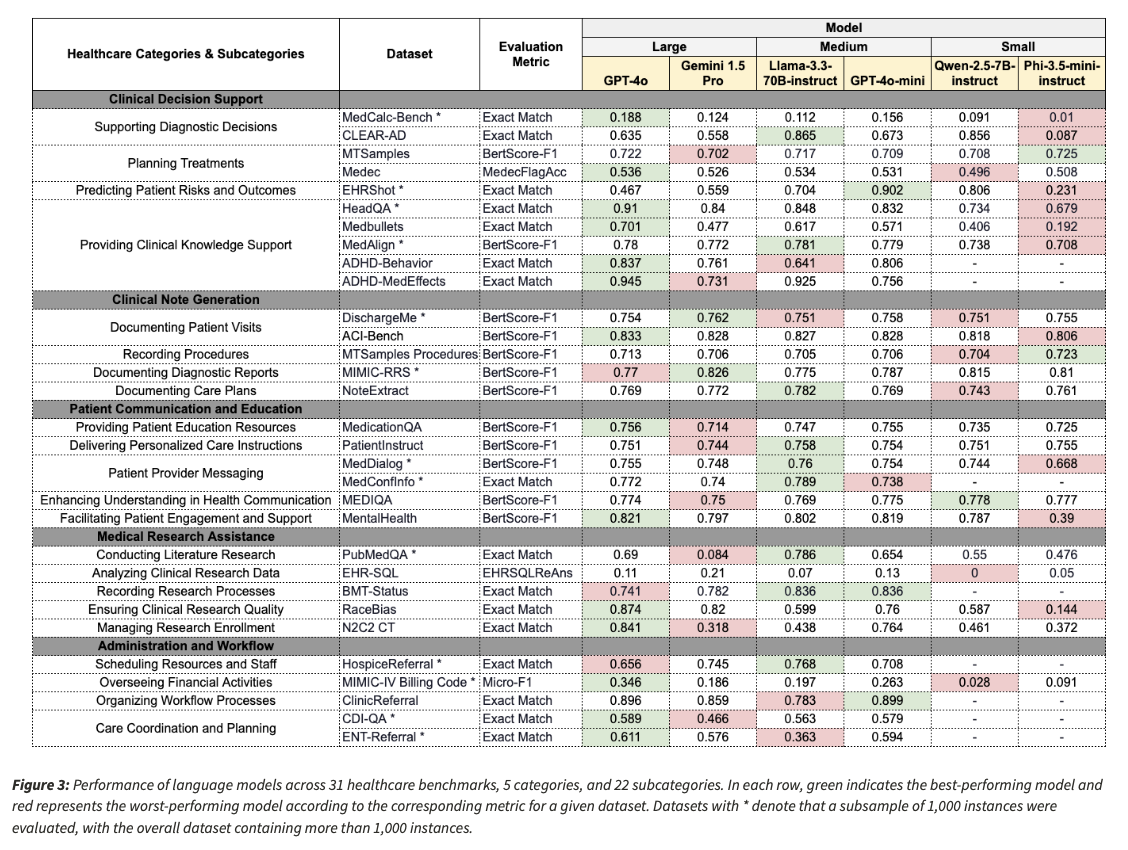
在六個不同尺寸的LLM上進行的評估揭示了基於任務複雜性的獨特優勢和劣勢。 GPT-4O和Gemini 1.5 Pro等大型模型在醫療推理和計算任務中表現出色,並且在臨床風險估計和偏置識別等任務中表現出了提高的準確性。諸如Llama-3.3-70B教學之類的中型模型在預測性醫療保健任務中競爭性地執行,例如醫院再入院風險預測。諸如PHI-3.5-MINI-Instruct和Qwen-2.5-7b-Instruct等小型模型在領域密集型知識測試中表現不佳,尤其是在心理健康諮詢和先進的醫學診斷方面。
除了準確性之外,對結構化問題的響應依從性也有所不同。有些模型不會回答醫學上敏感的問題,也不會以所需的格式回答,而以其整體表現為代價。該測試還發現了當前自動指標的缺點,因為常規的NLP評分機制傾向於忽略實際的臨床準確性。在大多數基準測試中,在使用BertScore-F1作為度量標準時,模型之間的性能差異仍然可以忽略不計,這表明當前的自動化評估程序可能無法完全捕獲臨床可用性。結果強調了更嚴格的評估程序的必要性,該程序包括基於事實的評分和明確的臨床醫生反饋,以確保評估方面的可靠性。
隨著臨床指導的多項式評估框架的出現,Medhelm提供了一種整體且值得信賴的方法,可以評估醫療保健領域中的語言模型。它的方法可以確保LLM可以根據實際的臨床任務,有組織的推理測試和各種數據集進行評估,而不是人工測試或截斷基準。它的主要貢獻是:
- 121項現實醫療任務的結構性分類學,改善了臨床環境中AI評估的範圍。
- 使用實際患者數據來增強模型評估超出理論知識測試。
- 嚴格評估六個最先進的LLM,確定需要改進的優勢和領域。
- 呼籲改進評估方法,強調基於事實的評分,可操作性調整和直接臨床醫生驗證。
隨後的研究工作將通過引入更專業的數據集,簡化評估流程以及實施醫療保健專業人員的直接反饋來集中於MEDHELM的改進。克服人工智能評估的重大局限性,該框架為大型語言模型與當代醫療保健系統的安全,有效和臨床相關的整合奠定了堅實的基礎。
查看 完整的排行榜,詳細信息和GitHub頁面。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題
Aswin AK是Marktechpost的諮詢實習生。他正在印度科技學院哈拉格布爾(Kharagpur)攻讀雙重學位。他對數據科學和機器學習充滿熱情,為解決現實生活中的跨域挑戰帶來了強大的學術背景和動手經驗。
🚨推薦開源AI平台:“ Intellagent是一個開源的多代理框架,可評估複雜的對話AI系統”(已晉升)


