


通過將復雜的問題分解為順序子步驟,諸如《經營鏈》(COT)提示之類的方法可以增強推理。最近的進步,例如類似O1的思維模式,引入了功能,包括反複試驗,回溯,校正和迭代,以提高難題的模型績效。但是,這些改進具有大量的計算成本。由於變壓器體系結構的局限性,增加的代幣產生創造了明顯的內存開銷,因為註意機制複雜性隨上下文長度二次增長,而KV緩存存儲的存儲時間是線性增加的。例如,當Qwen32b的上下文長度達到10,000個令牌時,KV緩存會消耗與整個模型相當的內存。
當前加速LLM推斷的方法分為三個主要類別:量化模型,生成更少的令牌和減少KV緩存。量化模型涉及參數和KV緩存量化技術。在減少KV緩存類別中,在離散空間中基於修剪的選擇以及在連續空間中合併的壓縮作為關鍵策略。基於修剪的策略實施特定的驅逐政策,以在推論過程中僅保留重要的令牌。基於合併的策略會引入錨定令牌,以壓縮歷史上重要的信息。這兩種方法之間的區別在於,基於修剪的方法是無訓練的,但需要為每個生成的令牌應用驅逐政策,基於合併的方法需要模型培訓。
誇江大學,螞蟻小組和青江大學的研究人員 – 螞蟻小組知識圖聯合實驗室已提議LightThinker,使LLMS能夠在動態推理過程中壓縮中間思想。受到人類認知的啟發,LightThinker將冗長的推理步驟壓縮為緊湊的表示並丟棄原始推理鏈,從而大大減少了在上下文窗口中存儲的令牌數量。研究人員還介紹了依賴性(DEP)度量,以通過衡量在發電期間對歷史令牌的依賴來量化壓縮效果。此外,LightThinker在保持競爭精度的同時減少了峰值記憶使用和推理時間,為提高複雜推理任務中LLM效率的有希望的方向提供了方向。
使用QWEN2.5-7B和LLAMA3.1-8B模型評估LightThinker方法。研究人員使用定制 – stratos-17k數據集進行了完整的參數教學調整,並將結果模型指定為香草。實施了五個比較基線:兩種無訓練的加速方法(H2O和SEPLLM),一種基於培訓的方法(ANLLM)以及應用於指令和R1-Distill模型的COT提示。評估發生在四個數據集(GSM8K,MMLU,GPQA和BBH),測量有效性和效率(通過推理時間,峰值令牌計數和依賴性指標)。該實現具有兩種壓縮方法:令牌級壓縮(將每6個令牌轉換為2)和思想級壓縮(以“ \ n \ n”為定界符進行分割思想)。
所有數據集上兩個模型的四個指標的評估結果揭示了幾個重要的發現。與所有數據集的COT相比,Distill-R1的表現始終不足,其性能差距歸因於貪婪解碼引起的重複問題。 H2O有效地保留了模型性能,同時還可以減少內存使用情況,從而驗證其貪婪的驅逐政策對長文生成。但是,H2O大大增加了推理時間(QWEN為51%,而Llama為72%),這是由於其令牌驅逐政策為每個產生的令牌創造了開銷。此外,LightThinker與H2O的性能匹配相似的壓縮率,同時減少了推理時間,QWEN減少了52%,而Llama則減少了41%。
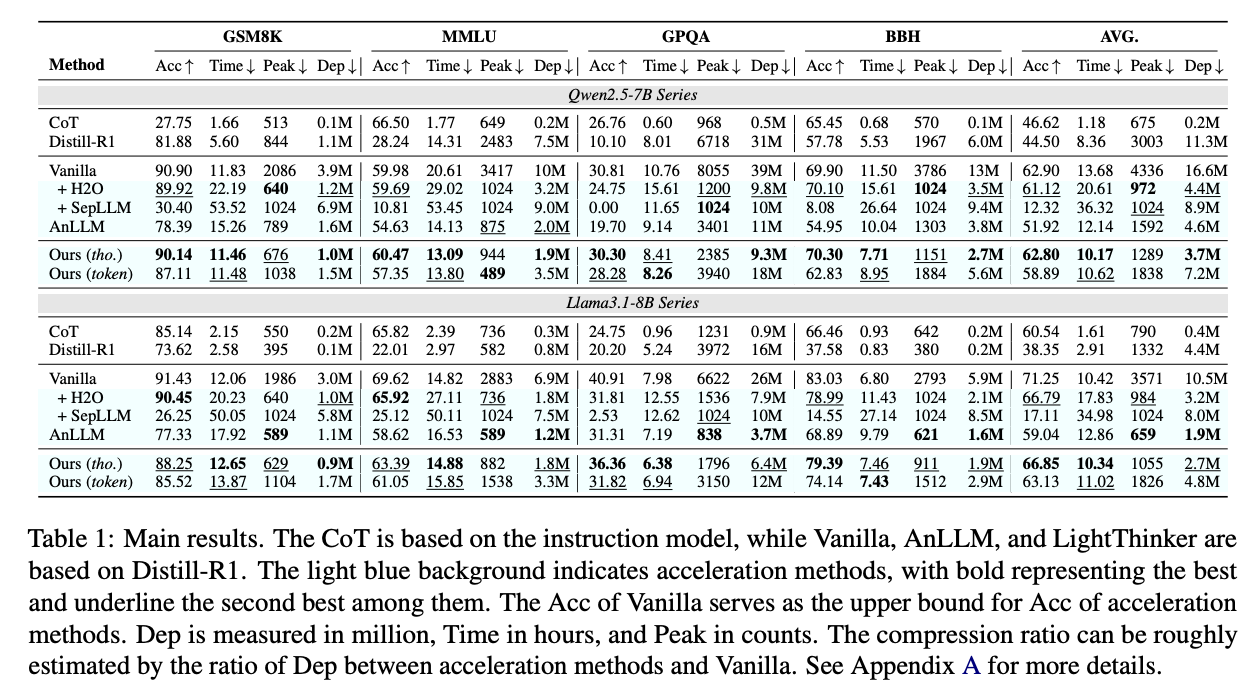
在本文中,研究人員介紹了LightThinker,這是一種通過在發電過程中中間思想的動態壓縮來提高複雜推理任務中LLM效率的新方法。通過訓練模型學習最佳的時機和方法,以壓縮詳細表示的冗長推理步驟,LightThinker大大降低了內存開銷和計算成本,同時保持競爭精度。但是,仍然存在一些局限性:尚未探索與參數有效的微調方法(如Lora或Qlora)的兼容性,較大的訓練數據集的潛在優勢是未知的,並且在訓練下進行臨時預測的小型數據集訓練時,在Llama系列模型上,性能降級在較高的效果上是值得注意的。
查看 紙。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題

Sajjad Ansari是來自IIT Kharagpur的最後一年的本科生。作為技術愛好者,他深入研究了AI的實際應用,重點是理解AI技術及其現實世界的影響。他旨在以清晰易於的方式表達複雜的AI概念。
🚨推薦開源AI平台:“ Intellagent是一個開源的多代理框架,可評估複雜的對話AI系統”(已晉升)


