


LLM ने मजबूत तर्क और Znowledge क्षमताओं को दिखाया है, हालांकि, जब उनके आंतरिक अभ्यावेदन में विशिष्ट विवरणों की कमी होती है, तो उन्हें अक्सर बाहरी JN ज्ञान वृद्धि की आवश्यकता होती है। नई जानकारी को शामिल करने का एक तरीका फाइन-ट्यूनिंग की निगरानी करना है, जहां मॉडल को अपने वजन को अपडेट करने के लिए अतिरिक्त डेटासेट पर प्रशिक्षित किया जाता है। हालांकि, यह दृष्टिकोण अक्षम है क्योंकि जब भी एक नया जुनावलेज पेश किया जाता है, तो उसे पुनर्व्यवस्थित करने की आवश्यकता होती है और सामान्य कार्यों पर मॉडल के प्रभाव को कम करके भयावह के बारे में भूल सकता है। इन सीमाओं को दूर करने के लिए, वैकल्पिक तकनीकों को मॉडल के वजन को बनाए रखने वाली वैकल्पिक तकनीकें लोकप्रियता प्राप्त हुई हैं। आरएजी एक दृष्टिकोण है जो असंरचित पाठ से सापेक्ष जे को पता चलता है और मॉडल के माध्यम से पास होने से पहले इसे इनपुट क्वेरी से जोड़ता है। गतिशील रूप से जानकारी प्राप्त करने से, आरएजी एक छोटे से संदर्भ आकार को बनाए रखते हुए एलएलएम को बड़े जे ज्ञान आधार को निष्पादित करने में सक्षम बनाता है। हालांकि, जीपीटी -4 और मिथुन जैसे लंबे संदर्भ मॉडल उभरे हैं, शोधकर्ताओं ने -कॉनटेक्स्ट एजुकेशन का आविष्कार किया है, जहां बाहरी जुनोवलेज को सीधे मॉडल के इनपुट में प्रदान किया जाता है। यह रिकवरी री की आवश्यकता को समाप्त करता है, लेकिन गणना की चुनौतियों के साथ आता है, क्योंकि लंबे संदर्भों में प्रक्रिया को काफी अधिक स्मृति और समय की आवश्यकता होती है।
बाहरी Joweltge को अधिक प्रभावी ढंग से एकीकृत करने के लिए LLMS की क्षमता को बढ़ाने के लिए कई उन्नत तकनीकों को विकसित किया गया है। संरचित ध्यान के तरीके संदर्भ को स्वतंत्र वर्गों में विभाजित करके स्मृति दक्षता में सुधार करते हैं, स्व-दवा को कम करते हैं। की-वैल्यू (केवी) कैशिंग विभिन्न स्तरों पर पूर्वनिर्धारित एम्बेडिंग को संग्रहीत करके प्रतिक्रिया पीढ़ी को सबसे अच्छा करता है, जिससे मॉडल को पुनर्गणना के बिना प्रासंगिक जानकारी को याद रखने की अनुमति मिलती है। यह संदर्भ लंबाई की लंबाई तक चतुर्भुज की जटिलता को कम करता है। पारंपरिक के विपरीत, कैशिंग कैसे, जो इनपुट को बदलता है, को पूर्ण वसूली की आवश्यकता होती है, जिससे नए तरीकों को चयनात्मक अपडेट का चयन करने की अनुमति मिलती है, जिससे बाहरी लचीला एकीकरण होता है।
जोन्स हॉपकिंस और माइक्रोस विश्वविद्यालय के शोधकर्ताओं ने Junoweltge के Aadhaar ऑगमेंटेड लैंग्वेज मॉडल (KBLAM) का प्रस्ताव रखा, जो LLMS को बाहरी j ज्ञान को एकीकृत करने की एक विधि है। KBLAM संरचित J ज्ञान Aadhaar (KB) को ट्रिपल के एक प्रमुख-मूल्य वेक्टर जोड़ी में बदल देता है, समान रूप से उन्हें LLM की ध्यान परतों में एम्बेडेड करता है। चीर के विपरीत, यह बाहरी रिट्रीवर्स को हटा देता है, और इन-संदर्भ सीखने के विपरीत, यह कैबेल आकार के साथ रैखिक रूप से तराजू है। KBLAM रिकवरी के बिना कुशल गतिशील अपडेट को सक्षम करता है और व्याख्या को बढ़ाता है। सिंथेटिक डेटा पर इंस्ट्रक्शन ट्यूनिंग का उपयोग करके प्रशिक्षित, जवाब देने से इनकार करना, भ्रम को कम करना और प्रासंगिक Junoweltge अनुपस्थित होने पर जवाब देने से इनकार करके स्केलेबिलिटी बढ़ाना।
KBLAM KB को दो चरणों से एकीकृत करके LLMS को बढ़ाता है। सबसे पहले, प्रत्येक सीबी ट्रिपल को लगातार एक पूर्व-सजा लाइन एनकोडर और रैखिक एडेप्टर का उपयोग करके कुंजी-मूल्य एम्बेडिंग के रूप में जाना जाता है, जिसे JNowledge टोकन के रूप में जाना जाता है। इन टोकन को तब आयताकार ध्यान संरचना द्वारा ध्यान के प्रत्येक स्तर में शामिल किया जाता है, जिससे एलएलएम के मुख्य आयामों को बदले बिना कुशल वसूली की अनुमति मिलती है। यह विधि स्केलेबिलिटी सुनिश्चित करती है, स्थिति पूर्वाग्रह को कम करती है, और तर्क क्षमताओं को बनाए रखती है। इसके अलावा, ट्यूनिंग निर्देश, यादगार को रोकने के लिए एक कृत्रिम कैब का उपयोग करते हुए, Junoweltge LLM को बदलने के बिना सबसे अच्छा टोकन प्रक्षेपण है। यह दृष्टिकोण मॉडल की मूल क्षमताओं को बनाए रखते हुए बड़े KBS को प्रभावी ढंग से एकीकृत करता है।
KBLAM का अनुभवजन्य मूल्यांकन J Eneltge के पुनर्प्राप्ति और तर्क मॉडल के रूप में इसकी प्रभावशीलता को दर्शाता है। निर्देश को ट्यून करने के बाद, इसका ध्यान मैट्रिक्स व्याख्या पैटर्न को दर्शाता है, जिससे सटीक वसूली की अनुमति मिलती है। KBLAM इन-कंटेंटेक्स लर्निंग के साथ तुलनात्मक संचालन प्राप्त करता है जब यह स्मृति की खपत को कम करता है और 10k ट्रिपल तक स्केलेबिलिटी बनाए रखता है। जब कोई रिश्तेदार Junoweltge नहीं होता है, तो यह जवाब देने से भी इनकार कर सकता है, जिसमें “ओवर-रिफ्यूज़ल” बाद में इन-संपर्क सीखने की तुलना में होता है। मॉडल को इंस्ट्रक्शन-ट्यून लामा 3-8 बी पर प्रशिक्षित किया जाता है और इष्टतम को ADMW का उपयोग करके ptimized किया जाता है। कृत्रिम और एनरोन डेटासेट का मूल्यांकन KBLAM की मजबूत वसूली सटीकता, कुशल Junowledge एकीकरण और अवसाद में कमी को कम करने की क्षमता की पुष्टि करता है।
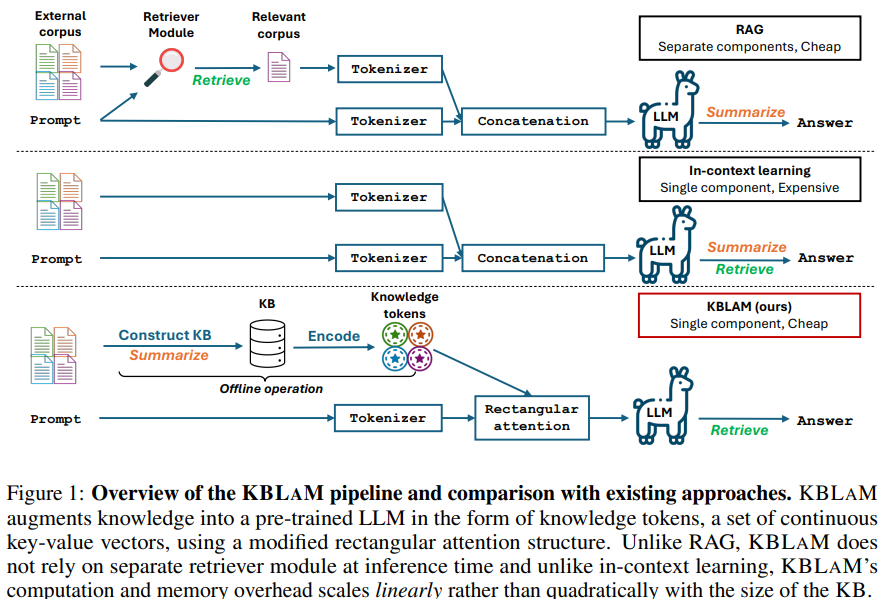
अंत में, KBLAM बाहरी KBs के साथ LLM को बढ़ाने के लिए एक दृष्टिकोण है। यह KB प्रविष्टियों को रैखिक एडेप्टर के साथ पूर्व-प्रशिक्षित लाइन एनकोडर का उपयोग करके एक निरंतर कुंजी-मूल्य वेक्टर जोड़ी के रूप में एन्कोड करता है और उन्हें एक विशेष ध्यान तंत्र के माध्यम से एलएलएम में एकीकृत करता है। रिकवरी-डिसेबल्ड पे-जनरेशन के विपरीत, KBLAM बाहरी रिकवरी मॉड्यूल को समाप्त करता है, और इन-महाद्वीप सीखने के विपरीत, यह KB आकार के साथ रैखिक तराजू है। यह एकल 100 GPU पर 8K संदर्भ विंडो के भीतर 8B LLM में 10k ट्रिपल के कुशल एकीकरण को सक्षम करता है। प्रयोग व्याख्या को सक्षम करते हुए और गतिशील Junowledge अपडेट को सक्षम करते हुए प्रश्न-उत्तर कार्यों में अपनी प्रभावशीलता दिखाते हैं।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।


