


在大型語言模型(LLMS)中,處理擴展輸入序列需要大量的計算和內存資源,從而導致推理較慢和硬件成本較高。注意機制是一種核心成分,進一步加劇了這些挑戰,因為其二次復雜性相對於序列長度。同樣,使用鍵值(KV)緩存維護先前的上下文會導致高內存開銷,從而限制可擴展性。
LLM的關鍵局限性是他們無法比訓練有素的上下文窗口處理序列更長的時間。由於記憶管理效率低下和注意力計算成本不斷增加,大多數模型在面對擴展輸入時的性能下降。現有的解決方案通常依賴於微調,這是資源密集型的,需要高質量的長篇小說數據集。如果沒有有效的方法進行上下文擴展方法,則諸如文檔摘要,檢索功能的生成和長期文本生成之類的任務仍受到限制。
已經提出了幾種方法來解決長篇文化處理的問題。 FlashAttention2(FA2)通過最大程度地減少注意力計算過程中的冗餘操作來優化內存消耗,但不能解決計算效率低下。一些模型在靜態或動態上採用選擇性令牌注意,以減少處理開銷。已經引入了KV緩存驅逐策略,以選擇性地刪除較舊的代幣,但它們可能會永久丟棄重要的上下文信息。髖關節注意是另一種試圖卸載的方法,很少會將令牌用於外部記憶。但是,它缺乏有效的緩存管理,從而增加了延遲。儘管有這些進展,但沒有有效地解決所有三個主要挑戰:
- 長篇文化概括
- 有效的內存管理
- 計算效率
Kaist和Deepauto.ai的研究人員介紹了 無限,一個高級框架,可在減輕內存瓶頸的同時提供有效的長篇小說推理。該模型通過層次令牌修剪算法實現了這一目標,該算法會動態刪除相關的上下文令牌。這種模塊化修剪策略有選擇地保留對注意力計算的最大貢獻的令牌,從而大大降低了處理開銷。該框架還結合了自適應繩索(旋轉位置嵌入)調整,從而使模型可以概括為更長的序列,而無需其他訓練。此外,InfInehip採用了一種新型的KV緩存卸載機構,在確保有效檢索的同時,將頻率較低的代幣轉移到主機記憶中。這些技術使該模型能夠在48GB GPU上處理高達300萬個令牌,從而使其成為最可擴展的長篇文化推理方法。
無限制的核心創新是其多階段修剪機制,它一致地改善了整個多個階段的上下文選擇。令牌首先分為固定長度,並根據其註意力計算的貢獻進行處理。 TOP-K選擇方法可確保只保留最關鍵的令牌,而其他標記則被刪除。與其他分層修剪模型不同,該方法隨後是無限制的,完全平行,這在計算上有效。 KV緩存管理系統通過在保持檢索靈活性的同時動態卸載較不重要的上下文令牌來優化內存利用率。該模型還利用了不同註意力層的多種繩索插值方法,從而促進了對長序列的平滑適應。
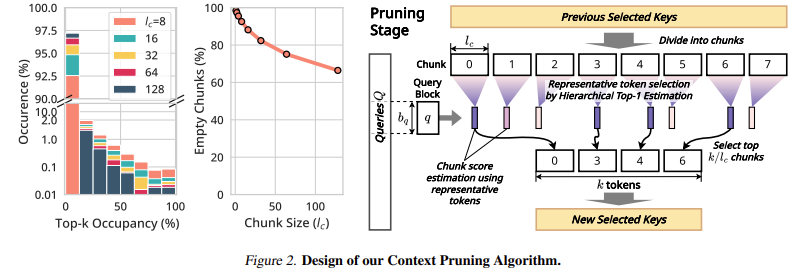
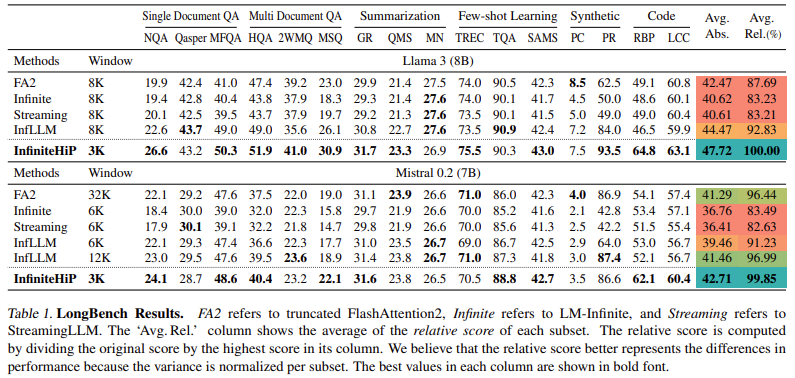
與沒有額外培訓的傳統方法相比,該模型的注意力解碼為100萬個環境中的注意力解碼增長了18.95倍。 KV緩存卸載技術可將GPU內存消耗降低多達96%,使其對於大規模應用程序實用。在基準評估(例如Longbench和∞bench)中,無限態度始終超過最先進的方法,比INFLLM高9.99%。同樣,消費者GPU(RTX 4090)和企業級GPU(L40S)上的解碼吞吐量增加了3.2×。
總之,研究團隊成功地解決了與無限態的長期替代推論的主要瓶頸。該框架通過整合層次令牌修剪,KV緩存卸載和繩索概括來增強LLM功能。這一突破使預訓練的模型能夠處理擴展序列而不會失去上下文或增加計算成本。該方法可擴展,硬件有效,適用於需要長期保留的各種AI應用程序。
查看 紙,源代碼和現場演示。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 75K+ ml子雷迪特。
🚨 推薦的開源AI平台:’Intellagent是一個開源多代理框架,可評估複雜的對話性AI系統‘ (晉升)
Asif Razzaq是Marktechpost Media Inc.的首席執行官。作為一位有遠見的企業家和工程師,ASIF致力於利用人工智能的潛力來實現社會利益。他最近的努力是推出了人工智能媒體平台Marktechpost,該平台的深入覆蓋了機器學習和深度學習新聞,既在技術上都可以聽起來,既可以通過技術上的聲音,又可以被廣泛的受眾理解。該平台每月有超過200萬個觀點,說明了其在受眾中的受歡迎程度。
✅(推薦)加入我們的電報頻道


