


Эта статья была только что принята в CVPR 2025. Короче говоря,, Касс является элегантным решением контекста на уровне объекта в сегментации открытого мира. Они превосходят несколько подходов без обучения и даже превосходят некоторые методы, которые полагаются на дополнительное обучение. Прибыль особенно примечательна в сложных настройках, где объекты имеют сложные подразделения или классы, имеют высокое визуальное сходство. Результаты показывают, что CASS последовательно предсказывает правильные метки до уровня пикселей, подчеркивая его утонченное осознание уровня объекта.
Хотите знать, как они это сделали? Читать ниже… кодовая ссылка доступна в конце.
Дистилляционные спектральные графики для контекста на уровне объектов: новый скачок в свободном обучении семантической сегментации с открытым вокабуляцией
Семантическая сегментация с открытой вокабуляцией (OVS) встряхивает ландшафт компьютерного зрения, позволяя моделям сегментировать объекты на основе любой Пользовательская подсказка-без привязанности к фиксированному набору категорий. Представьте, что вы говорите ИИ, чтобы выбрать каждую «космическую иглу» в городском пейзаже или обнаружить и сегментировать неясный объект, который вы только что придумали. Традиционные сегментационные трубопроводы, обычно ограниченные конечным набором учебных классов, не могут обрабатывать такие запросы без дополнительного создания или переподготовки. Входить Касс (контекстная семантическая сегментация)смелый новый подход, который использует мощные крупномасштабные, предварительно обученные модели для достижения высококачественной, объектной сегментации полностью без дополнительного обучения.
Рост без тренировок OVS
Традиционные подходы для семантической сегментации требуют обширных маркированных наборов данных. В то время как они преуспевают в известных классах, они часто борются или переполняют, когда сталкиваются с новыми классами, которых не было во время тренировки. Напротив, методы OVSS без тренировки-часто приводимы в действие крупномасштабных моделей на языке зрения, таких как CLIP, способны сегментировать на основе новых текстовых подсказок нулевым выстрелом. Это естественно соответствует гибкости, требуемой реальными приложениями, где нецелесообразно или чрезвычайно дорого предвидеть каждый новый объект, который может появиться. И потому что они без тренировкиЭти методы не требуют дальнейших аннотаций или сбора данных каждый раз, когда изменяется вариант использования … что делает это очень масштабируемым для решений на уровне производства.
Несмотря на эти сильные стороны, существующие методы без тренировки сталкиваются с фундаментальным препятствием: когерентность на уровне объекта. Они часто прижимают широкое выравнивание между пятнами изображения и подсказками для текста (например, «автомобиль» или «собака»), но не могут объединить весь объект, например, группировка колеса, крышу и окна грузовика под одной когерентной маской. Без явного способа кодирования взаимодействий на уровне объектов важные детали в конечном итоге фрагментированы, ограничивая общее качество сегментации.
CASS: контекст на уровне объекта для последовательной сегментации
Чтобы решить этот недостаток, авторы из Университета Йонсеи и UC Merced представляют CASS, систему, которая изгоняет богатые знания на уровне объекта из моделей Vision Foundation (VFMS) и выравнивает его с текстовыми вставками CLIP.
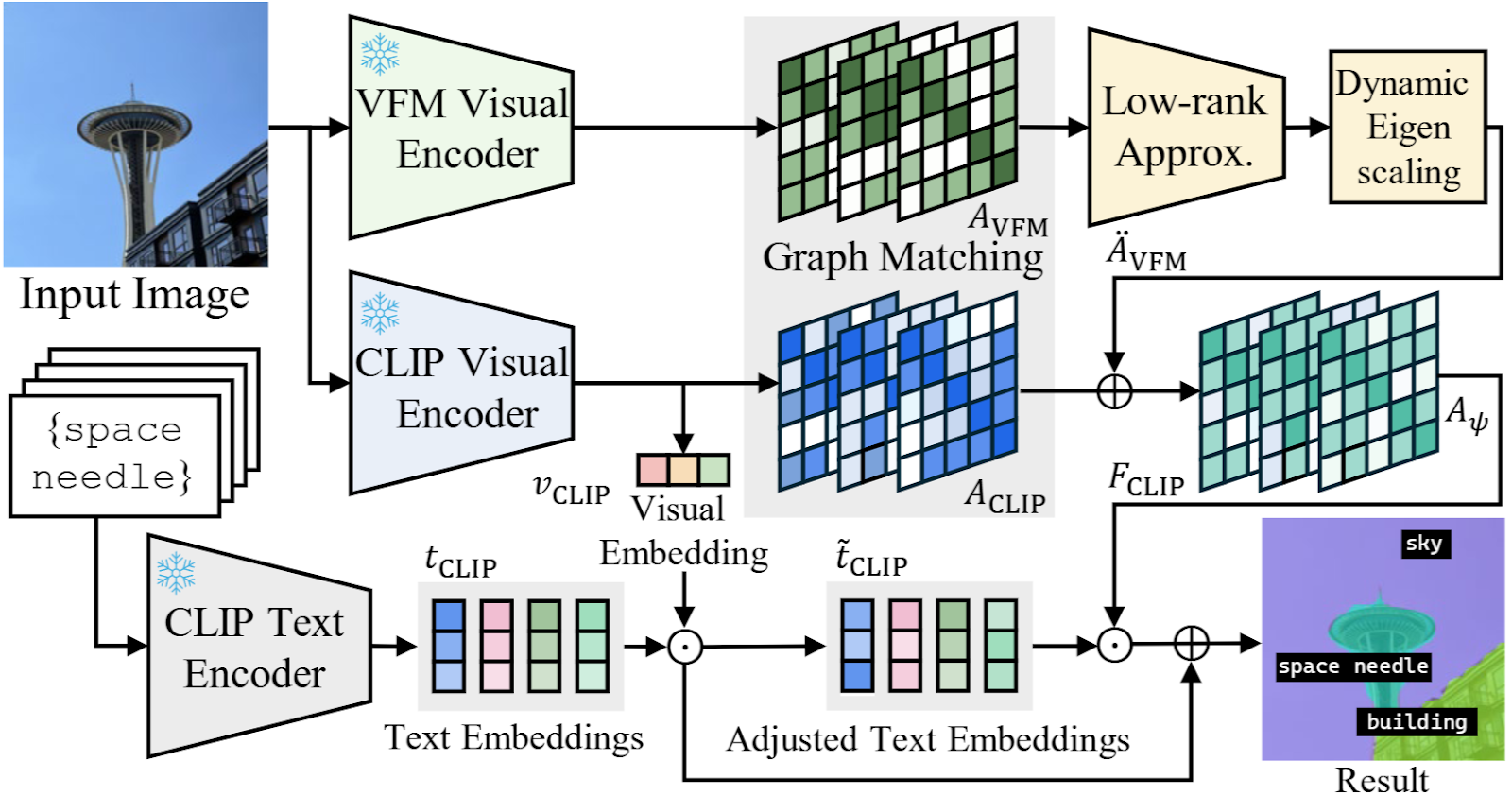
Два основных понимания способствует этому подходу:
- Дистилляция контекста на уровне спектрального объекта
В то время как Clip превосходит сопоставление текстовых подсказок с глобальными функциями изображения, он не отражает мелкозернистый, объектно-ориентированный контекст. С другой стороны, VFM, такие как Dino делать Узнайте сложные отношения на уровне патча, но не имеют прямого выравнивания текста.
CASS мостыет эти сильные стороны, рассматривая как клип, так и механизмы внимания VFM как графики и соответствующий Их внимание направляется через спектральное разложение. Другими словами, каждая голова внимания исследуется с помощью собственных значений, которые отражают, как патчи коррелируют друг с другом. Соединение дополнительная Головы-те, которые фокусируются на различной структуре-закладывают эффективную передачу контекста на уровне объекта из VFM в клип.
Чтобы избежать шума, авторы применяют Низкое приближение На графике внимания VFM, после чего следует Динамическое масштабирование собственного значенияПолем Результатом является дистиллированное представление, которое подчеркивает границы основных объектов при фильтрации не относящихся к делу подробностей – складывая клип, чтобы наконец «увидеть» все части грузовика (или любого объекта) в качестве одного объекта.
- Присутствие объекта до семантической уточнения
OVS означает, что пользователь может запросить любой быстро, но это может привести к путанице между семантически похожими категориями. Например, такие подсказки, как «автобус» против «грузовика», против «RV», могут вызвать частичное смешивание, если все в некоторой степени вероятно.
Касс справляется с этим, используя возможности классификации с нулевым выстрелом CLIP. Он вычисляет присутствие объектаоценивая, какова вероятность появления каждого класса на изображении в целом. Затем он использует это ранее двумя способами:
Уточнивание текста встроения: он семантически схожие подсказки и определяет, какие этикетки, скорее всего, в изображении, направляя выбранные текстовые встраивания ближе к действительный объекты
Сходство объектно-ориентированного патча: Наконец, CASS объединяет оценки сходства патч-текста с этими вероятностями присутствия, чтобы получить более четкие и более точные прогнозы.
Взятые вместе, эти стратегии предлагают надежное решение для истинной сегментации открытого вокабулятора. Независимо от того, насколько новым или необычным, CASS эффективно отражает как глобальную семантику и Тонкие детали, которые группируют части объекта.
Результаты впечатляют, см. Ниже, правый столбец – это CASS, вы можете четко увидеть сегментацию уровня объекта .. намного лучше, чем клип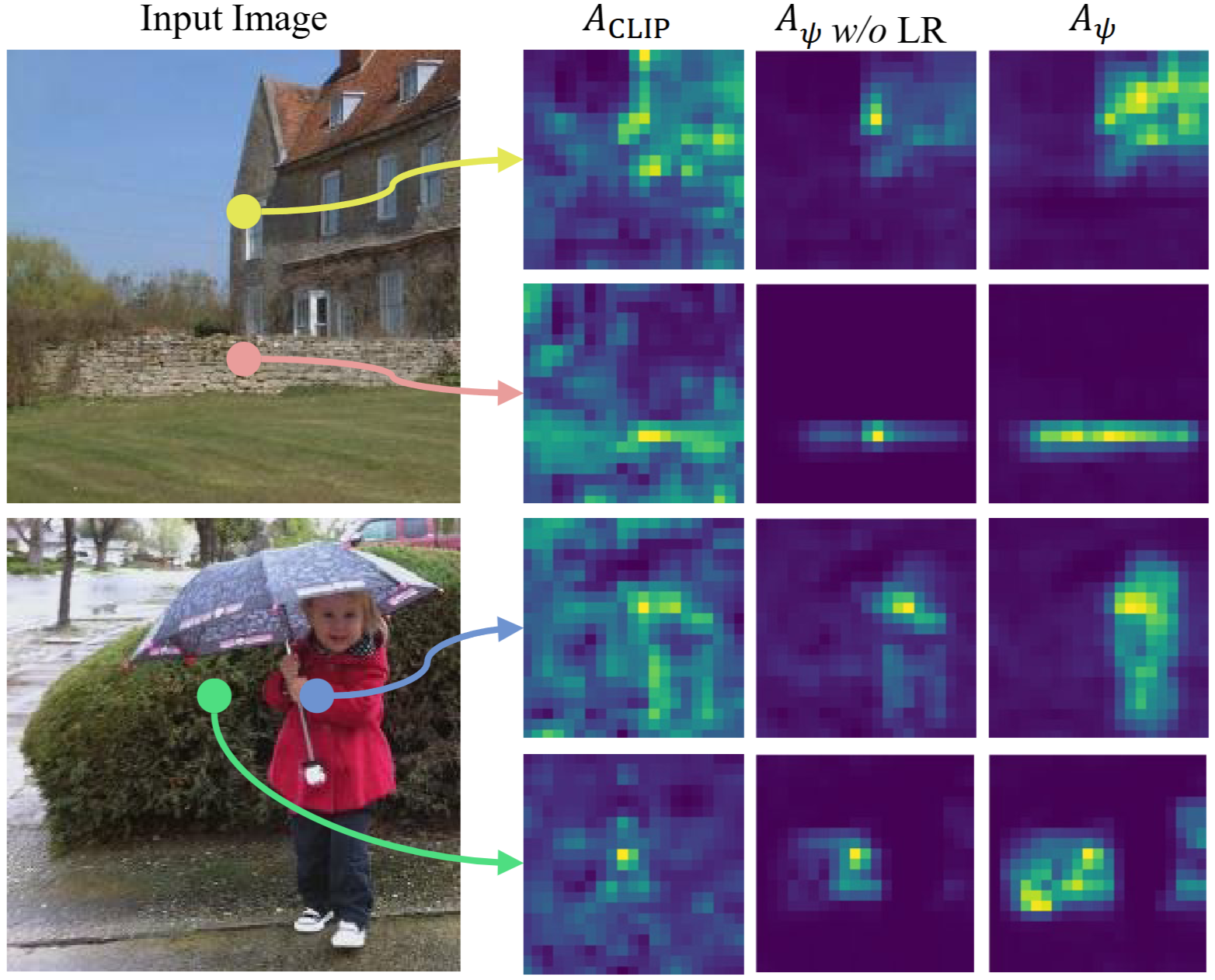
Под капотом: соответствующие головки внимания с помощью спектрального анализа
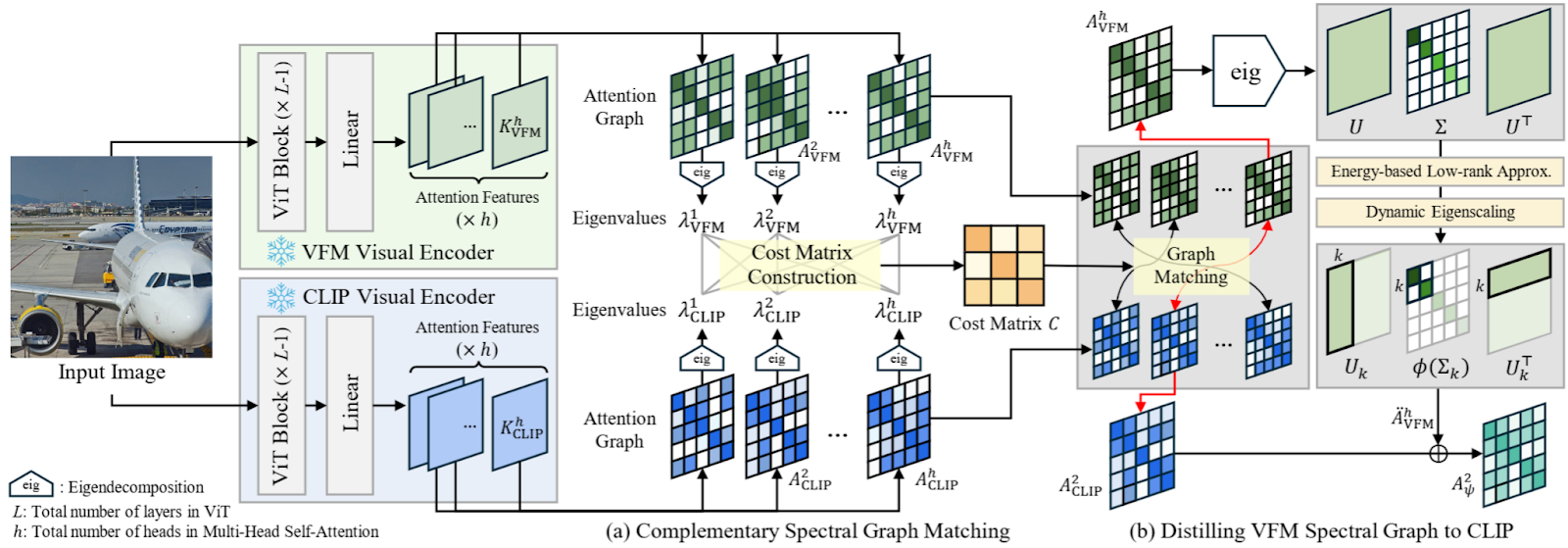
Одним из самых инновационных моментов CASS является то, как он соответствует головкам внимания клипа и VFM. Каждая голова внимания ведет себя по -разному; Некоторые могут принять участие в сигналах цвета/текстуры, в то время как другие блокируют форму или положение. Таким образом, авторы выполняют разложение собственных значений на каждой карте внимания, чтобы раскрыть свою уникальную «подпись».
- Матрица стоимости формируется путем сравнения этих подписей с использованием расстояния Вассерштейна, методика, которая измеряет расстояние между распределениями таким образом, чтобы улавливать общую форму.
- Матрица подается в алгоритм подходящего венгры, который сочетает головы, которые имеют контрастные структурные распределения.
- Соответствующие головки внимания VFM имеют низкодовольные аппроксимированные и масштабируемые, чтобы подчеркнуть границы объектов.
- Наконец, эти изысканные головы дистиллированный В внимание Клипа, увеличивая его способность рассматривать каждый объект как единое целое.
Качественно, вы можете думать об этом процессе как о выборочной инъекции когерентности на уровне объектов: после слияния клип теперь «знает» колесо плюс шасси плюс окно равно один грузовикПолем
Почему обучение без вопросов
- Обобщение: Поскольку CASS не нуждается в дополнительном обучении или создании, он гораздо лучше обобщает на выездные изображения и непредвиденные классы.
- Немедленное развертывание: Промышленные или роботизированные системы извлекают выгоду из мгновенной адаптивности – для каждого нового сценария не требуется дорогостоящего курирования наборов данных.
- Эффективность: С меньшим количеством движущихся частей и без аннотационных накладных расходов, трубопровод удивительно эффективен для реального использования.
В конце концов … для любого обучения решения на уровне производственного уровня бесплатно является ключом к обращению с длинными вариантами использования хвостаПолем
Эмпирические результаты
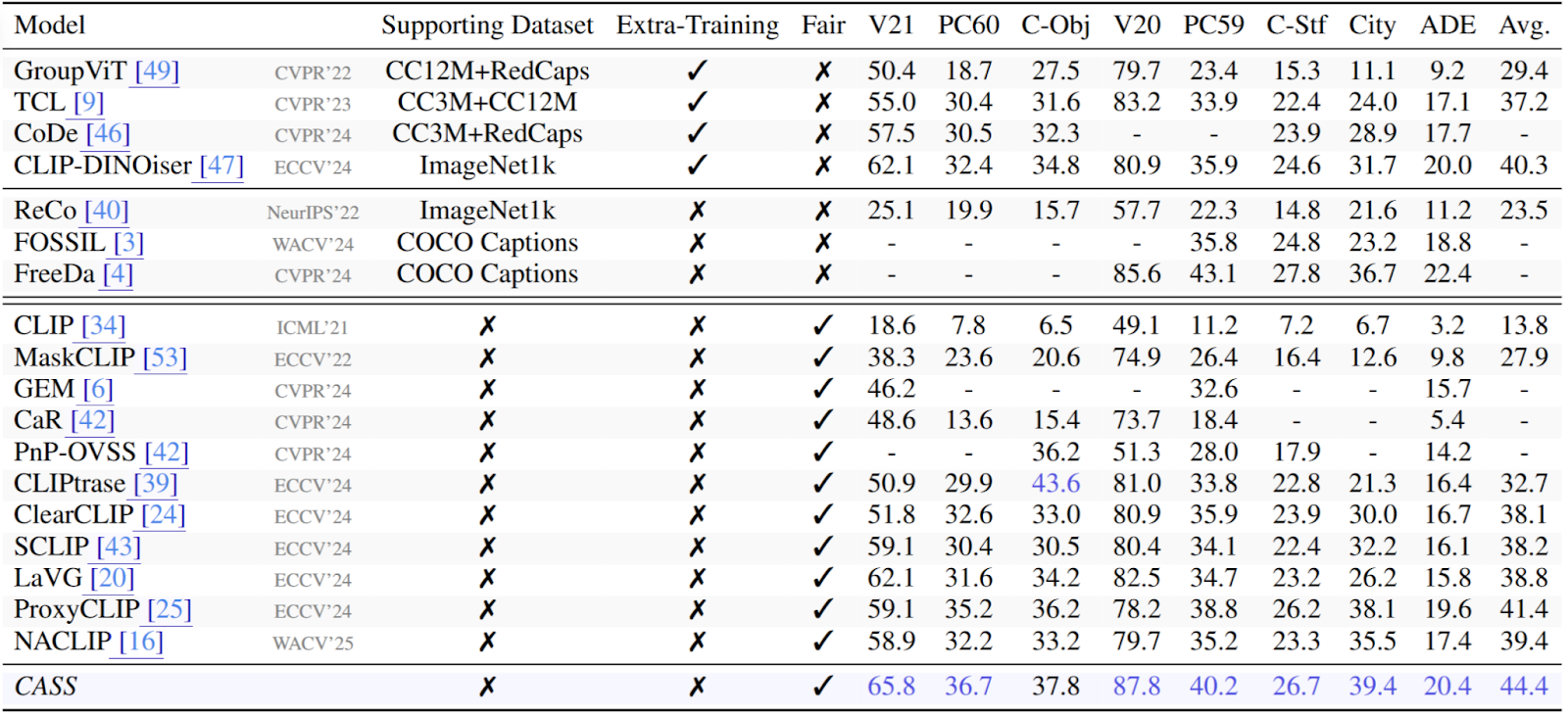
Касс проходит тщательное тестирование на восьми наборах данных, включая Pascal VOC, Coco и ADE20K, которые в совокупности охватывают более 150 категорий объектов. Появляются две выдающиеся показатели:
- Среднее пересечение над Союзом (MIO): CASS превосходит несколько подходов без обучения и даже превосходит некоторые методы, которые зависят от дополнительных тренировок. Прибыль особенно примечательна в сложных настройках, где объекты имеют сложные подразделения или классы, имеют высокое визуальное сходство.
- Точность пикселя (PACC): Результаты показывают, что CASS последовательно предсказывает правильные метки до уровня пикселей, подчеркивая его утонченное осознание уровня объекта.
Разблокировка истинной сегментации открытого вокабуляции
Выпуск CASS отмечает прыжок вперед для без тренировки OVS. Распределив спектральную информацию в клип и с помощью тонкого настройки текстовых подсказок с предыдущим присутствием объекта, она достигает очень последовательной сегментации, которая может объединить разбросанные части объекта-что-то, что много предыдущих методов изо всех сил пытались сделать. Развернуто в робототехнике, автономных транспортных средствах или за его пределами, эта способность распознавать и сегмент любой Объект Имена пользователей чрезвычайно мощный и откровенно требуемый.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI

Жан-Марк является успешным руководителем AI Business. Он возглавляет и ускоряет рост решений по производству искусственного интеллекта и основал компанию Computer Vision в 2006 году. Он является признанным докладчиком на конференциях по искусству и имеет степень магистра делового администрирования в Стэнфорде.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)

