

मानव प्रतिक्रिया (RLHF) से सुदृढीकरण शिक्षा मानव मूल्यों और वरीयताओं के साथ LLM के आयोजन के लिए महत्वपूर्ण है। डीपीओ गैर -आरएल विकल्पों को पेश करने के बावजूद, उद्योग के प्रमुख मॉडल जैसे कि CHATGPT/GPT -4, क्लाउड और GEMINI ऑप्टिमाइज़ेशन के लिए PPO जैसे RL एल्गोरिदम पर निर्भर करते हैं। हाल के शोध एल्गोरिथम अपडेट पर केंद्रित हैं, जिसमें गणना की लागत को कम करने के लिए महत्वपूर्ण मॉडल को समाप्त करना, पीपीओ नमूने के दौरान शोर के नमूनों को फ़िल्टर करना और पुरस्कार हैकिंग समस्याओं को कम करने के लिए पुरस्कार मॉडल बढ़ाना शामिल है। हालांकि, केवल कुछ अध्ययन RLHF डेटा निर्माण (यानी, प्रशिक्षण संकेत) के आधार पर इसके प्रदर्शन को बढ़ाने पर ध्यान केंद्रित करते हैं और यह प्रशिक्षण संकेत देता है।
RLHF पुरस्कार की सफलता मॉडल की गुणवत्ता पर बहुत अधिक निर्भर करती है, जो तीन चुनौतियों का सामना करती है: प्रशिक्षण डेटासेट और खराब सामान्यीकरण क्षमता में मानव विकल्पों, गलत और अस्पष्ट विकल्पों का प्रतिनिधित्व करने में गलत तरीके से परिभाषित पुरस्कार मॉडलिंग। इन मुद्दों पर विचार करने के लिए, GNRM को जमीनी चाँद के उत्तरों के खिलाफ मॉडल की भविष्यवाणियों को मान्य करने के लिए पेश किया गया था, जो हैकिंग को पुरस्कृत करने के लिए अच्छा प्रतिरोध दिखा रहा था और Dipcikv3 जैसे उन्नत LLM को अपनाया गया था। थ्योरी डेटा चयन जैसे तरीके जो प्रशिक्षण और रणनीतिक चयन विधियों के दौरान उदाहरणों को चुनौती देने वाले उदाहरणों को फ़िल्टर करते हैं, कम डेटा के साथ तुलनीय संचालन प्राप्त करने के लिए प्रमुख प्रशिक्षण संकेतों की पहचान करते हैं। प्रदर्शन स्केल विश्लेषण से पता चलता है कि RLHF उपन्यास के इनपुट पर SFT की तुलना में सबसे अच्छा सामान्यीकरण दिखाता है, लेकिन आउटपुट भिन्नता को काफी कम कर देता है।
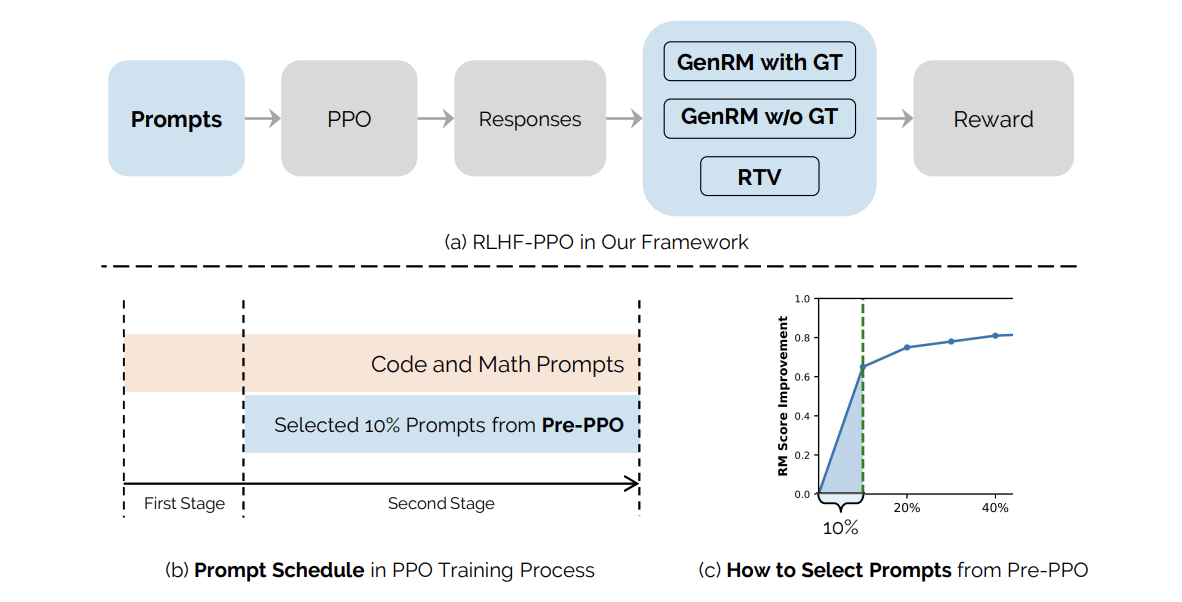
बिडेंस बीज के शोधकर्ता आरएलएचएफ अनुसंधान की महत्वपूर्ण दूरी को हटा देते हैं जहां प्रॉम्प्ट-डेटा निर्माण और इसके स्तनधारियों की भूमिका पर कम ध्यान दिया गया है। वे डेटा-आधारित बाधाओं का पता लगाते हैं जो RLHF प्रदर्शन स्केलिंग को सीमित करते हैं, पुरस्कार हैकिंग पर ध्यान केंद्रित करते हैं, और प्रतिक्रिया भिन्नता चुनौतियों को कम करते हैं। एक हाइब्रिड पुरस्कार प्रणाली को लॉजिक फ़ंक्शन वर्क वेरिफायर (आरटीवी) और प्राइज मॉडल (GNRM) के संयोजन द्वारा दर्शाया जाता है जो हैकिंग के लिए अधिक प्रतिरोध दिखाता है और ग्राउंड-ट्रूथ सॉल्यूशंस के खिलाफ उत्तरों का अधिक सटीक मूल्यांकन सक्षम करता है। इसके अलावा, प्री-पीपीओ। उपन्यास प्रॉम्प्ट-चॉइस विधि को स्वाभाविक रूप से चुनौतीपूर्ण प्रशिक्षण की पहचान करने के लिए पेश किया गया है, जो हैकिंग को पुरस्कृत करने के लिए कम अतिसंवेदनशील है।
प्रायोगिक सेटअप विभिन्न पैमानों के दो पूर्व-प्रशिक्षित भाषा मॉडल को नियुक्त करता है: 25B आयामों के साथ एक छोटा मॉडल और 150B आयामों के साथ एक बड़ा मॉडल। प्रशिक्षण डेटासेट में विभिन्न डोमेन के एक मिलियन संकेत शामिल हैं, जिनमें गणित, कोडिंग, निर्देश-निर्लज्ज, रचनात्मक लेखन और तार्किक तर्क शामिल हैं। इसके अलावा, शोधकर्ताओं ने कई कौशल क्षेत्रों को कवर करने वाली एक विस्तृत मूल्यांकन संरचना बनाई: तार्किक तर्क, निर्देश-अवसादग्रस्त, एसटीईएम फ़ंक्शन, कोडिंग, प्राकृतिक भाषा प्रक्रिया, jnowledge, संदर्भ समझ और फैलाव का सामान्यीकरण। मूल्यांकन ढांचे में ओवरलैपिंग प्रॉम्प्ट (V10 और V 2.0) के साथ दो संस्करण शामिल हैं, हालांकि V 2.0 अधिक चुनौतीपूर्ण संकेत दिखाता है।
प्रायोगिक परिणाम बताते हैं कि पूर्व-पीपीओ को प्रयोगात्मक गणितीय और कोडिंग कार्यों के साथ पूर्व-पीपीओ को जोड़ने वाला प्रस्तावित दृष्टिकोण लगातार बेसलाइन विधि को मॉडल आकार और मूल्यांकन डेटासेट में वहन करता है। जब टेस्टेट V10 का उपयोग करके 100-चरण अंतराल पर मूल्यांकन किया जाता है, तो दृष्टिकोण बेसलाइन पर +1.1 का सुधार दिखाता है। जब अधिक चुनौतीपूर्ण परीक्षण V 2.0 पर परीक्षण किया जाता है, तो प्रदर्शन में सुधार +1.4 तक बढ़ जाता है। सबसे उल्लेखनीय लाभ गणित-गहन और कोडिंग कार्यों में दिखाई देते हैं, स्टेम में +3.9 अंक और कोडिंग में +3.2 अंक के सुधार के साथ। इन अपडेट को प्रारंभिक RLHF प्रशिक्षण चरणों के दौरान गणितीय तर्क और कोडिंग कार्यों की रणनीतिक प्राथमिकता के लिए जिम्मेदार ठहराया जाता है।
अंत में, यह पेपर RLHF डेटा स्केलिंग के लिए महत्वपूर्ण बाधाओं को संबोधित करता है, विशेष रूप से इनाम हैकिंग और प्रतिक्रिया विविधताओं की महत्वपूर्ण चुनौतियों की पहचान करता है। शोधकर्ताओं ने इस मुद्दे को हल करने के लिए रणनीतिक शीघ्र निर्माण और प्रारंभिक -प्रशिक्षण प्रशिक्षण प्राथमिकता दिखाते हुए एक संयुक्त दृष्टिकोण का प्रस्ताव दिया। उपन्यास प्री-पीपीओ। प्रॉम्प्ट चयन आरटीवी और जीएनआरएम विधि का उपयोग करता है जो पुरस्कार हैकिंग से लड़ने के लिए रणनीति के साथ -साथ चुनौतीपूर्ण प्रशिक्षण संकेतों की पहचान करता है और पसंद करता है। विश्लेषण से पता चलता है कि आरटीवी पर्यवेक्षण पुरस्कार हैकिंग के सबसे मजबूत प्रतिरोध को दर्शाता है, इसके बाद ग्राउंड ट्रुथ लेबल और फिर बीटी पुरस्कार मॉडल के साथ जीएनआरएम। अनुसंधान RLHF izing izing ptize और हैकिंग और मॉडल कॉन्फ़िगरेशन को पुरस्कृत करने के लिए अधिक सिद्धांत विधियों को विकसित करने के लिए नींव स्थापित करता है।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।
अब (अब रजिस्टर करें) ओपन सोर्स एआई पर मिनिकॉन वर्चुअल कॉन्फ्रेंस: फ्री पंजीकरण + उपस्थिति का प्रमाण पत्र

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।


