
एएचबी कॉफी कॉर्नर: रिलीज की दुनिया में खराब अभ्यास
ऐहब कॉफी कॉर्नर छोटी बातचीत पर एआई विशेषज्ञों के संगीत को पकड़ता है। इस महीने हम प्रकाशन के क्षेत्र में […]

ऐहब कॉफी कॉर्नर छोटी बातचीत पर एआई विशेषज्ञों के संगीत को पकड़ता है। इस महीने हम प्रकाशन के क्षेत्र में […]

От создания сложного кода до революции процесса найма, генеративный искусственный интеллект изменяет отрасли промышленности быстрее, чем когда -либо прежде –

Join us on a thrilling journey in our latest episode of “As the AI World Turns,” as we explore DeepSeek’s
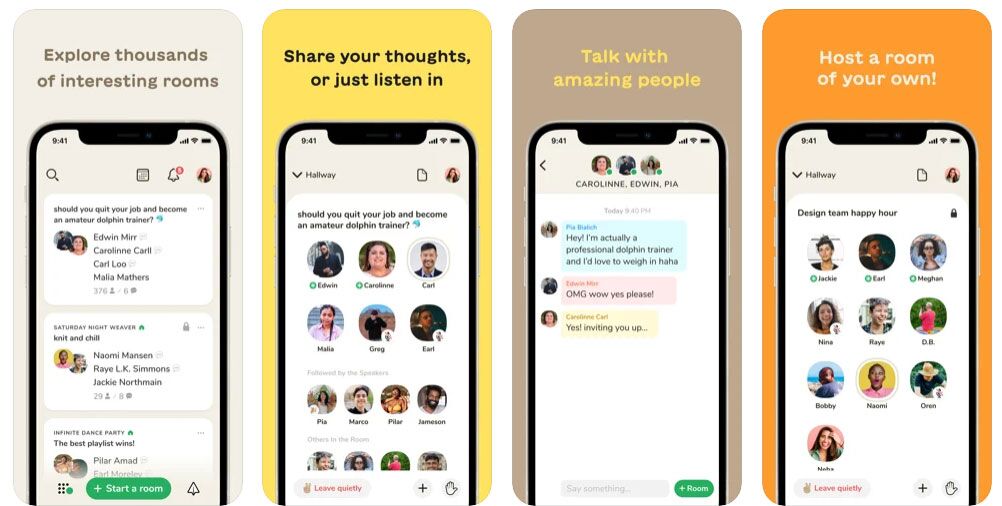
क्लब हाउस की तरह एक सामाजिक ऑडियो डियो ऐप बनाने में कितना खर्च आएगा? इस कोविड महामारी में, बाहर जाना

TransMLA:將基於GQA的模型轉換為基於MLA的模型 作為生產力工具,大型語言模型(LLMS)具有重要的重要性,開源模型越來越多地匹配其封閉源對應物的性能。這些模型通過下一代幣預測運行,當每個令牌及其前身之間計算注意力時,在計算注意力時會按順序進行預測。鍵值(KV)對被緩存,以防止冗餘計算並優化此過程。但是,緩存的內存需求不斷增長,構成了實質性局限性,在諸如Llama-65B之類的模型中尤其明顯,該模型需要超過86GB的GPU存儲器才能存儲具有8位鍵值量化的512K代幣,甚至超過H100,甚至超過H100 -80GB。 現有的方法已經出現,以應對LLMS中KV緩存的內存足跡挑戰,每種都有其自身的優勢和缺點。線性注意方法等線性變壓器,RWKV和MAMBA具有序列長度的線性縮放。動態的令牌修剪方法,例如lazyllm,a2SF和snapkv刪除了較少重要的令牌,而較小的頭尺寸降低技術(如slicegpt)和剪切的專注於減少注意力頭。跨層共享KV表示的方法,包括Yono和Minicache,以及GPTQ和KVQUANT等量化技術,試圖優化內存使用情況。但是,這些方法始終面臨計算效率和模型性能之間的權衡,通常會犧牲基本信息或註意力模式。 北京北京大學和小米公司的研究人員提出了TransMLA,這是一種培訓後的方法,將廣泛使用的基於GQA的預訓練的模型轉換為基於MLA的模型。他們的研究提供了理論上的證據,表明多層關注(MLA)與集體疑問(GQA)相比具有卓越的表現力(GQA),同時保持相同的KV緩存開銷。該團隊已成功將幾種基於GQA的模型轉換為包括Llama-3,QWEN-2.5,MISTRAL,MIXTRAL,GEMMA-2和PHI-4的模型。這種轉變旨在通過提供資源有效的遷移策略來改善模型性能的同時降低計算成本和環境影響,從而徹底改變主流LLM注意力。 使用QWEN2.5框架顯示了從GQA到MLA模型的轉換。在原始的QWEN2.5-7B型號中,每一層包含28個查詢頭和4個鍵/值頭,單個頭尺寸為128,KV緩存尺寸為1024。向MLA的轉換涉及調整兩個權重矩陣的輸出尺寸到512在將KV高速緩存維度保持在1024時。關鍵創新在於TransMLA方法,該方法將重量矩陣尺寸從512到3584,使所有28個查詢頭能夠與不同的查詢相互作用。這種轉換顯著增強了模型的表現力,同時保持KV高速緩存尺寸恆定,並且僅增加QK和VO對的參數增加12.5%。 TransMLA模型的性能評估顯示出比原始基於GQA的體系結構的顯著改善。使用Smoltalk指令微調數據集,TransMLA模型實現了較低的訓練損失,表明數據擬合功能增強。在7B和14B模型配置的數學和代碼任務中,性能改進大部分都可以看到。該研究通過受控實驗研究了這些改進的來源。當使用身份映射初始化而沒有正交分解的GSM8K數據集進行簡單維度擴展進行測試時,改進是最小的(0.15%),這表明大量性能的增長來自擴大的KV尺寸和正交分解的結合。 總之,研究人員通過引入TransMLA來提高LLM體系結構的顯著進步,TransMLA是一種將使用的基於GQA的預訓練模型轉換為基於MLA的模型的方法。理論證明和經驗驗證以增強的性能特徵建立了成功的轉型。這項工作通過全面的理論和實驗比較彌合了現有研究中GQA和MLA體系結構之間的關鍵差距。此外,未來的發展可以專注於將這種轉換方法擴展到諸如駱駝,Qwen和Mistral等主要大型模型,並通過DeepSeek R1蒸餾技術進行了其他優化,以提高模型性能。 查看 紙和github頁面。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 75K+ ml子雷迪特。 🚨 推薦的開源AI平台:’Intellagent是一個開源多代理框架,可評估複雜的對話性AI系統‘ (晉升)

Каждый год лаборатория Беркли исследований искусственного интеллекта (BAIR) выпускает некоторые из самых талантливых и инновационных умов в искусственном интеллекте и

Квантование является важным методом глубокого обучения для снижения вычислительных затрат и повышения эффективности модели. Крупномасштабные языковые модели требуют значительной мощности

CrowdStrike触发了AI Charlotte的检测,每周节省40多个小时的SOC命令,并提供了超过98%的准确性。阅读更多 Source link

माइक्रोस सामग्री नवाचार के लिए मैटरजेन लॉन्च करता है Microsoft ने सामग्री विजिल के क्षेत्र में बोल्ड जंप पेश किया

由Microsoft和Nvidia提出 AI以惊人的速度和规模为企业提供了切实的结果,这意味着新问题变成了我们如何利用这种潜力?但是,创建可靠的AI策略不仅是使用新技术。 我们正在谈论刺激一种在创新方面优先考虑的文化,确保安全规模,为开发人员提供取得成功的工具,并平衡先进的创新,安全的部署和扩大开发人员的权利和能力。组织可以使用各种模型,提供高质量的部署并利用战略合作伙伴关系的力量,创建人工智能解决方案,以增加业务的实际价值。 微软是3月17日在NVIDIA GTC AI AI会议上的精英赞助商,该公司的领导者将展示Microsoft Azure AI Force,AI通过平台AI,允许任何规模的企业快速,安全,负责任地引入创新。 NBA选择了NVIDIA加速的Azure OpenAI服务,将OpenAI模型包括在其应用程序中,加速了新创新功能的市场时间。通过个性化的本地化想法,帮助球迷们以自己想要的方式与联盟交流,NBA在粉丝优秀体验的前沿提供了支持。 宝马为数据录像机(MDR)移动数据创建了一个解决方案,将IoT放置在每个汽车开发人员中,以将数据传输到蜂窝连接到Azure Cloud Platform,Azure AI Solutions促进数据分析。系统涵盖的数据数据加倍,数据的传递和分析速度更快10倍。 基于纽约Origen的软件开发人员使用Microsoft Azure AI基础架构支持的AI专有模型彻底改变了能源行业。使用Azure