

Google Deepmind has unveiled an evolutionary coding agent, alfeive OLVE, designed to autonomously find novel algorithms and enemy solutions. Presented in paper -titled paper “Alfavolve: Coding Agent for Vijay. Ananic and Algorithmic Search“ This research represents the basic steps towards artificial general intelligence (AGI) and artificial superintendent (ASI). Instead of relying on stable fine-tuning or human-labeled datasets, the alphavolve takes a completely different way-which focuses on autonomous creativity, algorithmic innovation and constant self-improvement.
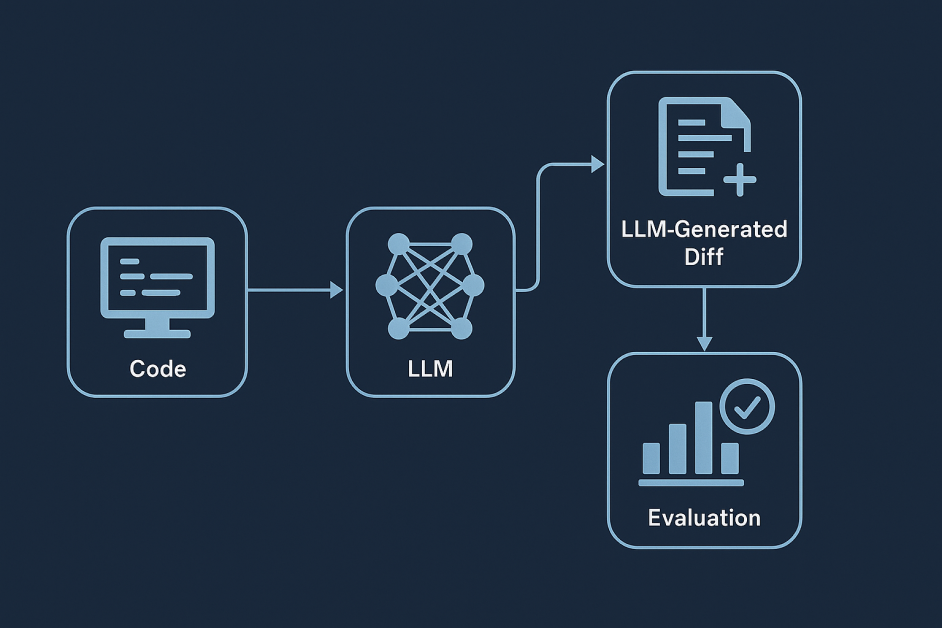
Alphave Olve One is a self-contained evolutionary pipeline in the heart of the heart, powered by a large language MODELS Dello (LLMS). This pipeline just does not generate the output – it transforms, evaluates, selected, and improves the code up to the pay -generations. The alfavolve starts with the initial program and repeats it by carefully introducing structured changes.
These changes take the form of LLM-generated defaus-cod changes indicated by the language model based on examples and clear instructions. In Software Fatware Engineering ‘defeus’ refers to the difference between two versions of the file, usually highlighting or replacing lines, and adding new lines. In the alphaive OLVE, the LLM produces this difference by analyzing the current program and proposing smaller edits – adding the function, ptomizing the loop, or replacing the hyperperameter – which includes the performance matrix and previous successful edits.
The test of each modified program is then done using automatic evaluators corresponding to the function. The most effective candidates are stored, referred to, and regenerated as inspiration for future repetitions. Over time, this evolutionary loop leads to the emergence of more and more sophisticated algorithms – often surpassing people designed by human experts.
Understand the widen BEHINDINGS behind the alfevolve
At its origin, the alphavolve is created on the principles of evolutionary calculation – subfield of artificial intelligence inspired by biological evolution. Starts with the basic implementation of the system code, which it behaves as an early “organism”. Through the Payenations, the alphavolve improves this code-evaluates the health of each variety using a well-defined scoring function-and a well-defined scoring function. The best performing types survive and serve as the next pay -generation samples.
This evolution is compiled by a loop:
- Prompt Sample: Alphaive OLVE LT Construction Prompts by selecting and embedding the previous successful code samples, display matrix and work-specific instructions.
- Code transformation and proposal: Systems uses a mixture of powerful LLMS – Jimney 2.0 Flash and Pro of, producing certain changes in the form of specific changes in current codbase.
- Evaluation Method: Automatic evaluation work assesses by implementing the performance of each candidate and returning to the scalar scores.
- Database and controller: The distributed controller orchestrates this loop, storing results in evolutionary database and balancing exploration with absorption by mechanisms like MAP-Elebites.
The rich, automatic evolutionary process of this feedback is radically different from standard fine-tuning techniques. It emphasizes the novel, high-performance and sometimes resistant solutions to alphave OLVE-Machine Learning can achieve the boundary of what can automatically achieve.
Alphavolve comparing with RLHF
To appreciate the innovation of Alfevov, it is crucial to compare it with reinforcement from human feedback (RLHF), which is used to finish large language models.
In the RLHF, human choices are used to train the prize model, which guides LLM’s learning process through reinforcement learning algorithms such as Proximal Policy Optim Ptimization (PPO). RLHF improves the configuration and utility of models, but it requires widespread human involvement to create feedback data and is usually operated in a stable, one-time fine-tuning regime.
Alfavolve, on the contrary:
- Machine-repeatedly removes human response from the loop in favor of the evaluators.
- Evolution supports continuous education by choice.
- Search more comprehensive solution spaces due to Stokstic change and asynchronous implementation.
- Can produce solutions that are not just aligned, but Novel And Vijay. Mannikally significant.
Where rlhf fine-tunes behavior, alphavolve Come to know And Refusal. This difference is important when considering the way of the future towards AGI: the alphavolve does not just make better predictions – it finds new ways of truth.
Applications and progress
1. Algorithmic discovery and mathematical progress
Alfavol has shown its ability to find groundbreaking discovery in major algorithmic problems. Most notably, he finds a novel algorithm to multiply two 4 × 4 complex-worth matrices using only 48 scalar multiplicks .Yo-Jayo-Jo-Jo Stressen’s 49 multiplication result and 56-year-old theoretical roof. Alphaivol achieved this through these advanced tensor decomposition techniques that developed on many repetitions, and forwarded many sophisticated approaches.
Next with the matrix multiplication, the alphaivol contributed significantly to mathematical research. It was evaluated on more than 50 open problems in areas such as Kambinatrix, number theory and geometry. She matched the most well -known results in about 75% of cases and exceeded it in about 20%. This success includes improvements to the minimum overlap problem of Aderis, a dancer solution of kisses number problem in 11 parameters, and more efficient geometric packing configurations. These results show its ability to act as an autonomous mathematical researcher – repeating, repeating, and developing more best solutions without human intervention.
2. Optim Ptimization in Google’s Compute Stack
Alfavallel has also given a tangible performance improvement in Google’s infrastructure:
- In Statistical schedule.
- For Gemini’s training kernelAlphavole formed a better tiling strategy for matrix multiplication, with 23% kernel speedup and 1% overall reduction in training time.
- In TPU Circuit designIt recognizes the ease of arithmetic logic at the RTL (Register-Transfer Level), which is verified by engineers and the next pay-Generation TPU. Included in chips.
- It also ptimizes Optim Compilation-Generated Flash Attachment Code By editing XLA intermediate representations, cutting the forecast time on GPU by 32%.
Together, these results validate the ability of alfives OLVE to work at multiple abstract levels-from factual math to low-level hardware Optim ptimization benefits.
- Evolutionary Programming: AI instance using inheritance to improve transformation, choice and repetitive solutions.
- Code superptimization: Automatic invention for the most efficient implementation of the function – often offers amazing, competitive improvements.
- Meta Prompt Evolution: The alphavolve just does not develop the code; It also develops how LLMS instructions communicate-enables self-refinement of-coding process.
- Discretion loss: Regularization promotes the output to adjust the word with critical, semi-intensive or integer values for mathematical and symbolic clarity.
- Dissatisfaction Loss: A method of providing random injections, promoting research and avoiding local minima in intermediate solutions.
- Maps Missing Algorithm: A type of quality-divority algorithm that retains a varied population of high-performing solutions in the parameters of the facility-enables innovation.
Notifying for AGI and ASI
Alphavolve is more than Optim ptimizer – it is a glimpse of the future where intelligent agents can show creative autonomy. The system’s ability to create intangible problems and solve their own approaches to a significant step toward artificial general intelligence. This goes beyond the forecast of the data: it includes the structured logic, the design of the strategy and the response – the hallmarks of intelligent behavior.
Repeatedly indicates the evolution of how machines learn the ability to generate its ability and produce purification. Unlike models that require extensive inspection training, the alpheivolve improves itself through an experiment and loop of evaluation. This dynamic form of intelligence allows it to navigate to complex problem spaces, discard weak solutions, and enhance strong people without direct human observation.
Alfiovov function as both theorist and practical, by implementing and validating its own ideas. It simulates the autonomous verb. The process of performing predetermined tasks and moving into the area of search. Each proposed improvement is tested, benchmarked and re-integrated-allows continuous purification on the basis of actual results rather than the objective objectives.
Perhaps most significantly, the alphavolve is an initial example of repeated self-improvement-where the AI system not only learns but enhances itself. In some cases, the alphaivol improved the training structure supporting its own foundation models. Although still bound by current architects, this capacity determines an example. With more problems formed in an evaluated environment, the alphavolve can be increasingly sophisticated and self-Optim ptimized behavior-the basic feature of artificial superintulance (ASI).
Limitations and future ways
The current limit of Alfevov is its dependence on automatic evaluation tasks. This limits its utility to problems that can be formal from mathematical or algorithm. It cannot yet act meaningfully in domains that require human understanding, subjective judgment or physical experiment.
However, future directions include:
- Integration of hybrid evaluation: combining symbolic logic with human choices and natural language critics.
- Simulation enables the atmosphere to deploy.
- The base of the output developed in the base LLMS, creates more capable and sample-efficient foundation models.
This route points to more and more agency systems capable of solving autonomous, high-drug problems.
End
Alfavolve is a profound step – not only in AI tools but also in our understanding of machine intelligence. By merging the evolutionary search with LLM logic and response, those machines can automatically find that they can automatically detect. It is an initial but significant indication that self-improvement systems capable of real-wide thought are no longer theoretical.
Looking forward, architectures underpining the alphavolve themselves can often be applied to themselves: developing its own evaluators, improving change logic, improving scoring tasks, and ptimizing underlying training pipelines for models dependent on it. This repeated Optim ptimization loop represents the technical method of bootstrap towards AGI, where the system not only meets tasks but also improves the very structural facility that enables its education and logic.
Over time, such as more complex and abstract domains, alfeivaovels scales – and reduce human intervention in the process – it can display accelerating intelligence gains. This self-priced cycle of repetitive improvement, not only for external problems but also on its own algorithmic structure, is the main theoretical component of AGI and all the benefits that can provide to the society. Along with its creativity, autonomy, and a combination of repetition, the alphaive Olve can be remembered not only as the product of the dipmind, but in the first true meaning as a normal and self-developed artificial mind blueprint.

