

सुदृढीकरण लर्निंग (आरएल) प्रशिक्षण के लिए एक प्रमुख घटक है जो एक बड़े -लैंग्वेज मॉडल डेल्स (एलएलएम) को शामिल करने के लिए तर्क, विशेष रूप से गणितीय समस्याओं को शामिल करने के लिए शामिल है। प्रशिक्षण के दौरान एक महत्वपूर्ण विकलांगता है, जिसमें ऐसी स्थिति भी शामिल है जहां कई सवालों का जवाब हमेशा दिया जाता है या अनसुलझा होता है। सफलता दर में बदलाव की कमी अक्षम शिक्षा के परिणामों के लिए दोषी ठहराना है क्योंकि एक ग्रेड एलआईडी सिग्नल प्राप्त नहीं करने वाले प्रश्न मॉडल के प्रदर्शन को बेहतर बनाने की अनुमति नहीं देते हैं। पारंपरिक आरएल-आधारित फाइन-ट्यूनिंग रणनीतियाँ महंगी गणना लागत के लिए अतिसंवेदनशील होती हैं, ऊर्जा की खपत को बढ़ाती हैं और संसाधनों के अक्षम उपयोग को बढ़ाती हैं। प्रशिक्षण दक्षता में सुधार करना और भाषा के मॉडल को उन समस्याओं से सुधारना आवश्यक है जो उनके तर्क में सुधार करते हैं।
लार्ज -लैंगुएज मॉडल (एलएलएम) की मानक प्रशिक्षण पद्धति नीति ग्रेड सॉल्ट तकनीकों का उपयोग करती है, जैसे कि समीपस्थ नीति ऑप्टिम प्टमाइजेशन (पीपीओ), जिसमें मॉडल प्रत्येक क्वेरी के साथ जुड़े होते हैं और सफलता या विफलता के संकेतों के आधार पर सुधार लागू होते हैं। हालांकि, इस दृष्टिकोण की सबसे बड़ी कमियां यह हैं कि अधिकांश प्रशिक्षण उदाहरण चरम सीमाओं के समूह हैं – हमेशा सही या हमेशा गलत। जब उदाहरण हमेशा ठीक से हल किया जाता है, तो लगातार प्रयास अधिक सीखने की जानकारी प्रदान नहीं करते हैं। । यह, एक असंभव क्वेरी सुधार के लिए प्रतिक्रिया नहीं करता है। नतीजतन, मूल्यवान गणना संसाधन बेकार प्रशिक्षण दृश्यों पर बर्बाद हो जाते हैं। विभिन्न पाठ्यक्रम तकनीकों, जैसे कि अस्वास्थ्यकर पर्यावरण डिजाइन (यूईडीएस) ने प्रशिक्षण की कठिनाई को नियंत्रित करने की कोशिश की है। ये तकनीक, हालांकि, पछतावा-आधारित पसंद जैसे हेरिस्टिक्स पर निर्भर करती हैं, जो कि सबसे अच्छी समस्या कठिनाई की उम्मीद करने के लिए बहुत अपर्याप्त है और एलएलएम प्रशिक्षण से संबंधित तर्क कार्यों को सामान्य करने में विफल है।
इस अक्षमता को दूर करने के लिए, एक उपन्यास प्रशिक्षण नीति का सुझाव दिया गया है और प्रस्तावित किया गया है जो सफलता दर के उच्च विविधताओं पर केंद्रित है, इस प्रकार मॉडल को उन सवालों पर ध्यान केंद्रित करने के लिए मजबूर करता है जो बहुत आसान और बहुत कठिन नहीं हैं। उन मुद्दों की पहचान और चुनकर जो मॉडल डेल ने अनियमित रूप से प्रदर्शित किए, दृष्टिकोण विचारों पर प्रशिक्षण प्रशिक्षण जो सबसे अधिक जानकारीपूर्ण शिक्षा संकेत प्रदान करते हैं। पिछली नीतियों से अलग है कि ट्रेन बैच यादृच्छिक नमूनों का उपयोग करता है, यह व्यवस्थित चयन विधि उन समस्याओं को समाप्त करके अद्यतन दक्षता को बढ़ाती है जो महत्वपूर्ण सुधार की अनुमति नहीं देती हैं। यह प्रक्रिया प्रशिक्षण के दौरान अपना जाती है, लगातार मॉडल के उतार -चढ़ाव वाले पावर ट्रैक को बनाने के लिए प्रश्न के चयन को बढ़ाती है। मध्यम कठिनाई पैटर्न को लक्षित करते हुए, दृष्टिकोण उपन्यास कार्यों में बेहतर शिक्षा और बेहतर सामान्यीकरण को सक्षम बनाता है।

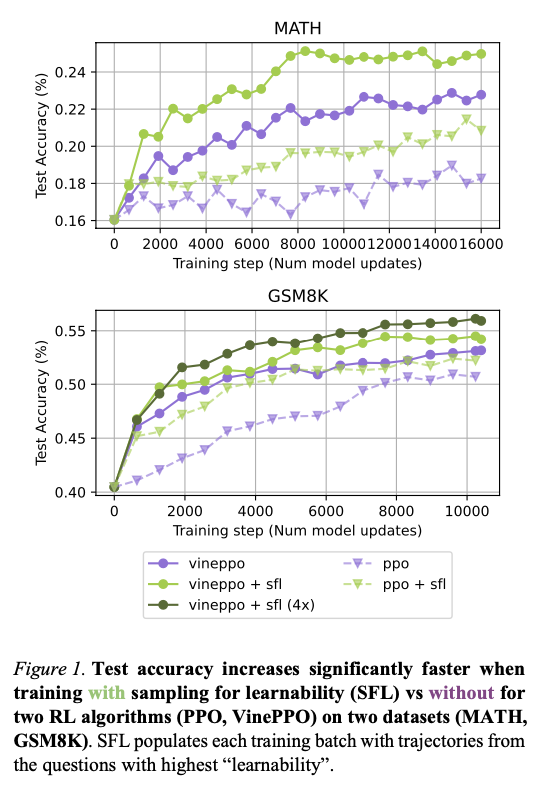
संरचित चयन प्रक्रिया एक बहु-चरण पाइपलाइन के माध्यम से काम करती है जो प्रत्येक प्रशिक्षण पुनरावृत्ति पर उम्मीदवार के सवालों की पहचान के साथ शुरू होती है। प्रत्येक समस्या के लिए सफलता की संभावना का मूल्यांकन करने के लिए कई रोलआउट का उत्पादन किया जाता है, और इस सफलता की गणना दरों में भिन्नता कार्य 𝑝 (1 – 𝑝) का उपयोग करके की जाती है, जहां विलेय एक सच्चे समाधान की संभावना का प्रतिनिधित्व करता है। मध्यम सफलता की संभावनाओं के साथ सबसे अधिक सीखा प्रश्न प्राथमिकता और गतिशील बफर में संग्रहीत हैं। फिर यह बफर उच्च-टोन समस्याओं और डेटासेट से अतिरिक्त यादृच्छिक नमूना उदाहरणों का एक संयोजन बनाता है। इस सावधानी से गठित बैच का उपयोग नीति के ग्रेड लॉर्ड की गणना करने और मॉडल मापदंडों को अपडेट करने के लिए किया जाता है। इस रणनीति की प्रभावशीलता को दो गणितीय तर्क डेटासेट पर दो सुदृढीकरण एल्गोरिदम, PPO और WINPPOS को लागू करके अनुमोदित किया गया है: गणित, 12,000 प्रतियोगिता-स्तरीय समस्याओं के साथ, और GSM8K, जिसमें 8,000-ग्रेड स्कूल-स्तरीय प्रश्न हैं। मूल प्रशिक्षण वितरण से परे सामान्यीकरण क्षमताओं को प्रमाणित करने के लिए कोलेजमथ और ओलंपिडबेंच डेटासेट पर अतिरिक्त परीक्षण किए जाते हैं। संपूर्ण संरचना vinappo को सरल ऑप्टिमाइज़ेशन के साथ जोड़ती है जैसे कि ग्रैड कलर संचय, मल्टी-रोलआउट अनुमान और स्केलेबल प्रदर्शन प्रदान करने के लिए Dippid शून्य।

शिक्षा आधारित विकल्प की विधि मॉडल प्रशिक्षण की गति और दक्षता दोनों में बहुत सुधार करती है। इस पाठ्यक्रम के साथ सटीक मॉडल उतने ही सटीक हैं जितना कि मॉडल को पारंपरिक तरीकों के साथ लगभग चार गुना कम प्रशिक्षण चरणों में प्रशिक्षित किया जाता है, जिसमें रूपांतरण दरों में महत्वपूर्ण सुधार होता है। GSM8K और गणित पर बेहतर परीक्षण सटीकता के साथ, कई डेटासेट द्वारा प्रदर्शन में लगातार सुधार होता है। संरचित पाठ्यक्रम भी वितरण के बाहर के कार्यों में सामान्य करता है, जिसमें कोलेजमथ और ओलंपबेड जैसे डेटासेट में अधिक सामान्यीकरण होता है। प्रशिक्षण बैच रचना शून्य सीखने के संकेत के साथ प्रश्नों को हटाकर, अधिक कुशल प्रशिक्षण के लिए अग्रणी है। दृष्टिकोण भी गणनात्मक रूप से लाभकारी प्रतीत होता है, क्योंकि नमूना वेतन पीढ़ी को निरर्थक मॉडल अपडेट के बिना प्रभावी रूप से बढ़ाया जा सकता है। तेजी से रूपांतरण, बेहतर सामान्यीकरण और कम गणना ओवरहेड का संयोजन इस अनुकूली शिक्षा प्रक्रिया को सुदृढीकरण शिक्षा-आधारित एलएलएम-ट्यूनिंग के लिए एक मूल्यवान और कुशल उपकरण बनाता है।

लक्ष्य प्रश्न चुनने के लिए उच्च-टोन सीखने के अवसर के लिए एक उदाहरण, सुदृढीकरण शिक्षा के आधार पर भाषा मॉडल के ठीक-ट्यूनिंग में गवाह की अयोग्यता को प्रभावी ढंग से संबोधित करता है। उन समस्याओं पर ध्यान केंद्रित करना जो सबसे अधिक जानकारीपूर्ण प्रशिक्षण संकेतों का उत्पादन करती हैं, सीखने की दक्षता को अधिकतम करती हैं, नए टेम्प्लेट के साथ तेजी से सुधार और बेहतर अनुकूलनशीलता प्राप्त करती हैं। बड़े -स्केल प्रयोगों ने प्रशिक्षण की गति को बढ़ाने के लिए रणनीति को बेहतर ढंग से मान्य किया, एक से अधिक डेटासेट में परीक्षण की सटीकता और सामान्यीकरण। ये निष्कर्ष मॉडल प्रशिक्षण शोधन सुधार और कम्प्यूटेशनल संसाधन ऑप्टिमाइज़ेशन में एक संरचित नमूना चयन के वादे को उजागर करते हैं। रणनीतियों पर भविष्य का अध्ययन इसके अन्य सुदृढीकरण शिक्षा कार्यों के लिए लागू हो सकता है, जैसे कि इनाम मॉडल इष्टतम ptimization, चयन-आधारित फाइन-ट्यूनिंग और सामान्य निर्णय लेने वाले कार्यों को एआई में।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
Aswin AK MaviyechPost में एक परामर्श इंटर्न है। उन्हें खड़गपुर में भारतीय प्रौद्योगिकी में दोहरी डिग्री मिल रही है। यह डेटा अभिव्यक्तियों और पंखों और मशीन लर्निंग के बारे में उत्साही है, एक मजबूत शैक्षणिक पृष्ठभूमि और वास्तविक जीवन क्रॉस-डॉमन चुनौतियों को हल करने में अनुभव लाता है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (बी एड)


