


बड़ी भाषा मॉडल ने महत्वपूर्ण समस्याओं को हल करने के लिए क्षमताओं और गणितीय और तार्किक तर्क को दिखाया है। इन मॉडलों को जटिल तर्क कार्यों पर लागू किया गया है, जिसमें अंतर्राष्ट्रीय गणितीय ओलंपियाड (IMO) कॉम्बिनेटिक्स समस्याएं, अमूर्त और लॉजिक कॉर्पस (ARC) पहेलियाँ और मानवता की अंतिम परीक्षा (HLE) शामिल हैं। सुधार के बावजूद, मौजूदा एआई मॉडल अक्सर उच्च-स्तरीय समस्याओं को हल करने के साथ संघर्ष करते हैं, जिसमें अमूर्त तर्क, औपचारिक फुटपाथ परीक्षण और अनुकूलनशीलता की आवश्यकता होती है। एआई-आधारित समस्या को हल करने की बढ़ती मांग के कारण, शोधकर्ताओं ने उपन्यास पूर्वानुमान तकनीकें विकसित की हैं जो सटीकता और विश्वसनीयता बढ़ाने के लिए कई तरीकों और मॉडलों को जोड़ती हैं।
एआई लॉजिक के साथ चुनौती समाधान की शुद्धता के परीक्षण में है, विशेष रूप से गणितीय समस्याओं के लिए कई चरणों और तार्किक कटौती की आवश्यकता होती है। पारंपरिक मॉडल डेलो सीधे अंकगणित में अच्छा प्रदर्शन करते हैं, लेकिन जब अमूर्त अवधारणाएं, औपचारिक अग्रणी साक्ष्य और उच्च-आयामी तर्क। प्रभावी एआई प्रणाली को स्थापित गणितीय सिद्धांतों का पालन करते समय वैध समाधानों का उत्पादन करना चाहिए। वर्तमान सीमाओं ने शोधकर्ताओं को उन्नत अनुमान तकनीकों का पता लगाने के लिए प्रोत्साहित किया है जो सत्यापन में सुधार करते हैं और समस्या की विश्वसनीयता बढ़ाते हैं।
गणितीय तर्क चुनौतियों को खत्म करने के लिए कई तकनीकों को लागू किया गया है। शून्य-शॉट टोटल लर्निंग मॉडल को पिछले एक्सपोज़र के बिना समस्याओं को हल करने में सक्षम बनाता है, जबकि सर्वश्रेष्ठ-एफ-एन नमूने कई उत्पन्न उत्तरों से सबसे सटीक समाधान चुनते हैं। मोंटे कार्लो ट्री सर्च (MCT) सिमुलेशन संभावित समाधानों का आविष्कार करता है, और Z3 जैसे सैद्धांतिक-रोविंग सॉफ्टवेयर FTware लॉजिकल स्टेटमेंट का परीक्षण करने में मदद करता है। उनकी उपयोगिता के बावजूद, इन तरीकों को अक्सर संरचित परीक्षणों की आवश्यकता होने पर जटिल समस्याओं का सामना करने पर ताकत की कमी होती है। इसने एक अधिक व्यापक संरचना का विकास किया है जो कई अनुमान रणनीतियों को एकीकृत करता है।
बोस्टन विश्वविद्यालय, Google, कोलंबिया विश्वविद्यालय, एमआईटी, इंट्यूट और स्टैनफोर्ड के शोधकर्ताओं की एक टीम ने एक अभिनव दृष्टिकोण पेश किया जो स्वचालित जांच के साथ विभिन्न अनुमान तकनीकों को जोड़ती है। अनुसंधान तर्क प्रदर्शन को बढ़ाने के लिए परीक्षण-समय सिमुलेशन, सुदृढीकरण शिक्षा और मेटा-लर्निंग को एकीकृत करता है। डेलो और समस्या को सुलझाने के तरीकों के कई मॉडलों को लाभान्वित करके, दृष्टिकोण यह सुनिश्चित करता है कि एआई सिस्टम एक ही तकनीक पर निर्भर नहीं करते हैं, इस प्रकार सटीकता और अनुकूलन क्षमता बढ़ाते हैं। संरचित एजेंट सिस्टम की समस्या में सुधार करने और कार्य जटिलता के आधार पर अनुमान रणनीति को समायोजित करने के लिए ग्राफ को नियुक्त करता है।
विधि स्वचालित जांच के माध्यम से गणितीय और तार्किक समस्याओं के समाधान के परीक्षण के आसपास घूमती है। IMO समस्याओं के लिए, शोधकर्ताओं ने LIP, Z3, मोंटे कार्लो ट्री सर्च और प्लान सर्च सहित आठ अलग-अलग तरीकों को लागू किया, ताकि एक दुबला aoremic प्रचार वातावरण में औपचारिक-आधारित निष्कर्षों में अंग्रेजी-आधारित समाधानों का अनुवाद किया जा सके। यह शुद्धता की गहन जांच के लिए अनुमति देता है। आर्क पज़ल्स को सिंक्रनाइज़ कोड सॉल्यूशंस का उपयोग करके संबोधित किया जाता है, जो प्रशिक्षण उदाहरणों के खिलाफ यूनिट परीक्षण द्वारा मान्य हैं। एच.एल. सुदृढीकरण शिक्षा और परीक्षण-समय मेटा-लर्निंग प्रदर्शनी के आधार पर एजेंटों के ग्राफ प्रतिनिधित्व को समायोजित करके अनुमान प्रक्रिया में सुधार करता है।
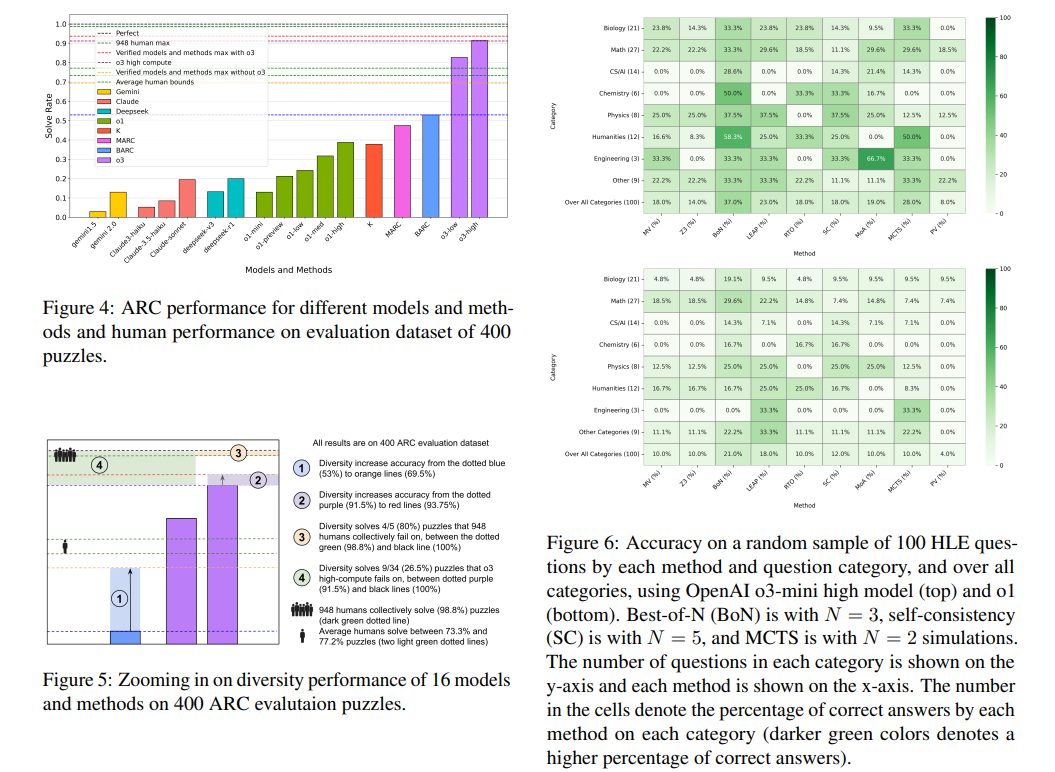
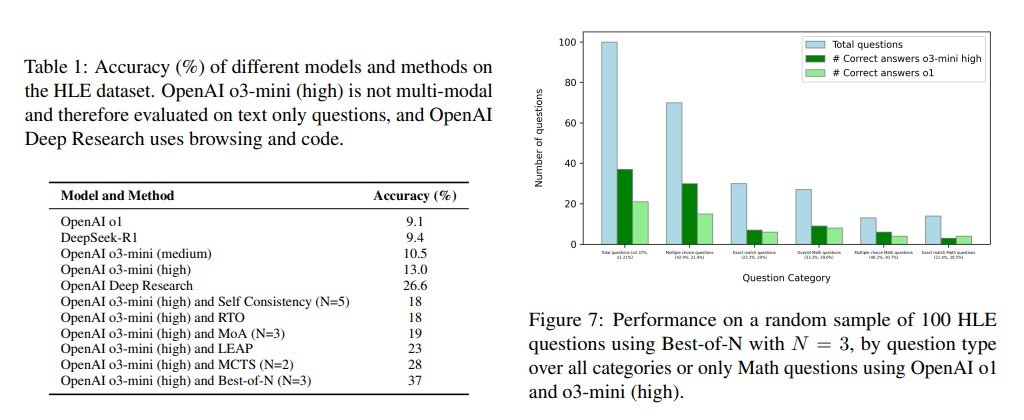
इस दृष्टिकोण के प्रभाव ने कई तर्क कार्यों में महत्वपूर्ण सुधार दिखाए हैं। IMO कॉम्बीनेटरिक्स समस्याओं के लिए, सटीकता 33.3% से बढ़कर 33.3% हो गई ।8 77..8%, जो गणितीय प्रमाण उत्पादन के लिए AI क्षमताओं में महत्वपूर्ण छलांग दिखाती है। एच.एल.ई. प्रश्नों के संदर्भ में, सटीकता 8% से बढ़कर 37% हो गई है, जो कई शाखाओं में समस्या को हल करने के लिए अनुकूलनशीलता दिखाती है। उनकी जटिलता के लिए जानी जाने वाली आर्क पहेलियाँ, 948 मानव प्रतिभागियों द्वारा प्रयास की गई पिछली अनसुलझे समस्याओं के लिए 80% सफलता दर देखी। इसके बाद, मॉडल डेल ने सफलतापूर्वक 26.5% आर्क पहेली को हल किया जो ओ 3 ओपन ओ 3 उच्च-कम्प्यूट मॉडल को संबोधित करने में विफल रहा। अनुसंधान कई मॉडल डेलो को जोड़ने की प्रभावशीलता पर प्रकाश डालता है, जो दर्शाता है कि एकीकृत तरीके जटिल लॉजिक कार्यों में एकल-मेथ्रो दृष्टिकोणों को पूरा करते हैं।
यह अध्ययन स्वचालित सत्यापन प्रणालियों के साथ विभिन्न अनुमान रणनीतियों को विलय करके एआई-संचालित तर्क में एक परिवर्तनकारी प्रगति प्रस्तुत करता है। सुदृढीकरण शिक्षा के माध्यम से कई AI तकनीकों और ptimizing लॉजिक पथों का लाभ देकर, अनुसंधान जटिल समस्याओं को हल करने के लिए चुनौतियों के लिए एक स्केलेबल समाधान प्रदान करता है। परिणामों से पता चला है कि भविष्य में अधिक परिष्कृत लॉजिक मॉडल को फ़र्श करके संरचित निष्कर्षों के समेकन द्वारा एआई प्रणाली के कामकाज को काफी बढ़ाया जा सकता है। यह कार्य गणितीय समस्याओं और तार्किक सत्यापन को हल करने में एआई के व्यापक अनुप्रयोग में योगदान देता है, जो मौलिक चुनौतियों को समाप्त करता है जो उन्नत तर्क कार्यों में एआई की प्रभावशीलता को सीमित करता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
निखिल मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह खड़गपुर में भारतीय संगठन की प्रौद्योगिकी में सामग्री में दोहरी डिग्री प्राप्त कर रहा है। निखिल एआई/एमएल उत्साही है जो हमेशा बायोमेट्रियल और बायोमेडिकल विगल्स जैसे क्षेत्रों में आवेदन पर शोध करता है। भौतिक अभिव्यक्ति में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति और योगदान की संभावना की तलाश कर रहा है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)


