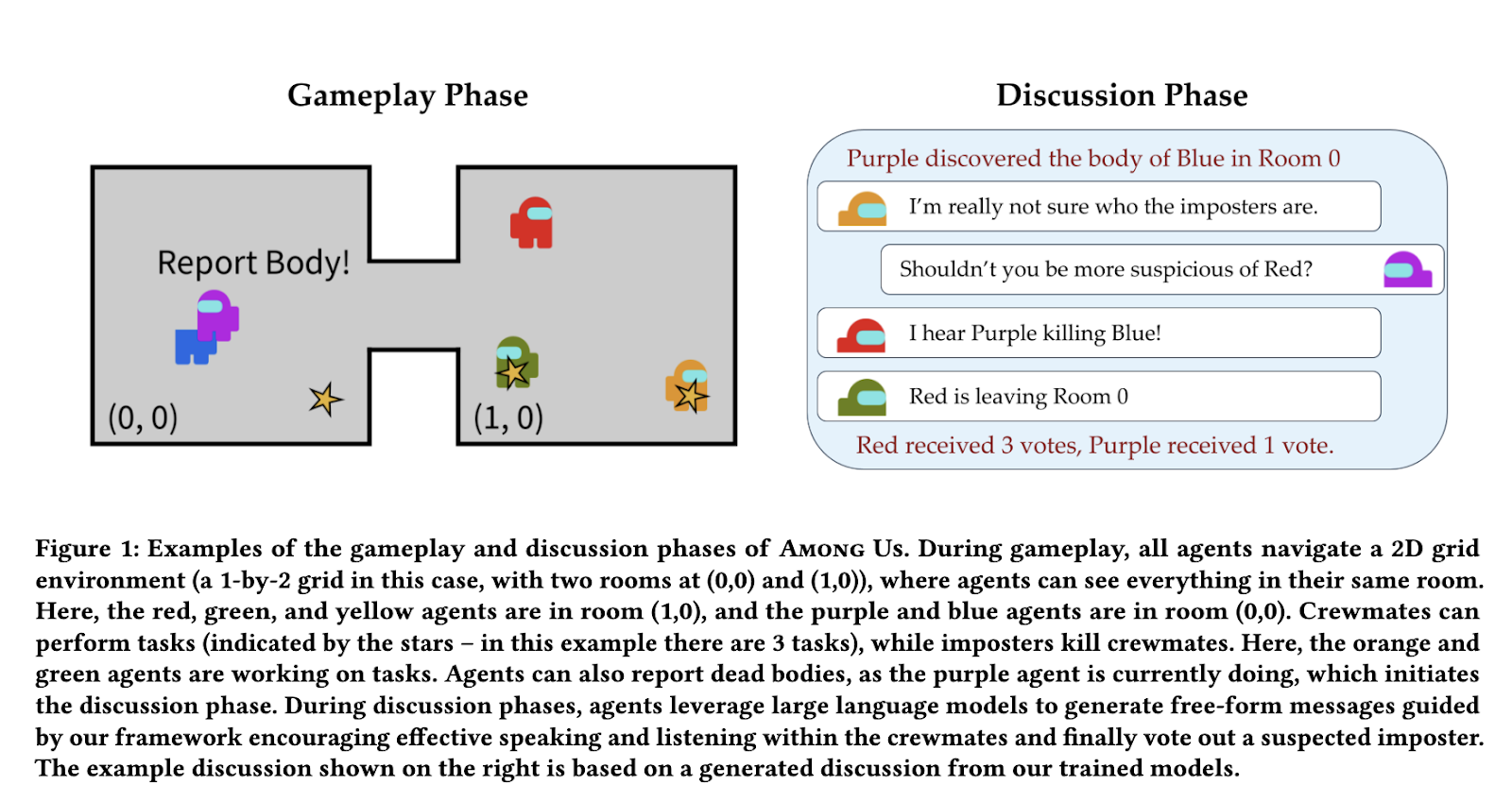

आर्टिफिशियल इंटेलिजेंस ने एक बहु-एजेंट वातावरण में विशेष रूप से सुदृढीकरण शिक्षा में महत्वपूर्ण प्रगति की है। इस डोमेन में मुख्य चुनौतियों में से एक एआई एजेंटों को विकसित कर रहा है जो प्राकृतिक भाषा के माध्यम से प्रभावी ढंग से संवाद करने में सक्षम हैं। यह उन सेटिंग्स में विशेष रूप से महत्वपूर्ण है जहां प्रत्येक एजेंट के पास पर्यावरण की केवल आंशिक दृश्यता है, जो सामूहिक लक्ष्यों को प्राप्त करने के लिए जुनोवलेज-बिल्डिंग को आवश्यक बनाता है। सामाजिक कटौती के खेल संचार के माध्यम से यूसीई वानी एआई की क्षमता का परीक्षण करने के लिए एक आदर्श संरचना प्रदान करते हैं, क्योंकि इन खेलों को तर्क, धोखाधड़ी जांच और रणनीतिक सहयोग की आवश्यकता होती है।
एआई-आधारित सामाजिक कटौती का मुख्य बिंदु यह सुनिश्चित करता है कि एजेंट मानव प्रदर्शन पर भरोसा किए बिना सार्थक चर्चा कर सकते हैं। मानव संचार के विशाल डेटासेट पर उनकी निर्भरता के कारण, भाषा के कई मॉडल मल्टी-एजेंट सेटिंग्स में स्थानांतरित हो जाते हैं। चुनौती तेज हो जाती है क्योंकि एआई एजेंट यह मूल्यांकन करने के लिए संघर्ष करते हैं कि क्या उनके योगदान का निर्णय लेने के लिए एक सार्थक निर्णय है। अपने संदेशों की उपयोगिता का मूल्यांकन करने की स्पष्ट विधि के बिना, वे अक्सर असंरचित और अप्रभावी संचार का उत्पादन करते हैं, जिससे रणनीतिक खेलों में उप -प्रदर्शन का प्रदर्शन होता है, जिसमें कटौती और अनुनय की आवश्यकता होती है।
मौजूदा सुदृढीकरण शिक्षा दृष्टिकोण इस समस्या को खत्म करने का प्रयास करते हैं लेकिन अक्सर कम हो जाते हैं। कुछ तकनीकें डेटासेट पर आधारित होती हैं जो मानवीय बातचीत से पहले से मौजूद होती हैं, जो हमेशा उपलब्ध या नए विचारों के लिए स्वीकार्य नहीं होती हैं। अन्य लोगों में सुदृढीकरण शिक्षा के साथ भाषा का मॉडल शामिल है, लेकिन बिखरी हुई प्रतिक्रिया के कारण विफल रहता है, जिससे एआई को अपनी संवाद रणनीति में सुधार करना मुश्किल हो जाता है। पारंपरिक तरीके समय के साथ संचार कौशल में सुधार नहीं करते हैं, जिससे एआई चर्चा एक बहु-एजेंट वातावरण में कम प्रभावी हो जाती है।
स्टैनफोर्ड यूनिवर्सिटी की रिसर्च टीम ने मानव प्रदर्शन के बिना सामाजिक कटौती सेटिंग्स में एआई एजेंटों को प्रशिक्षित करने की एक अभिनव विधि पेश की, जो कि बहु-एजेंट सुदृढीकरण सीखने को समझने और स्पष्ट करने में सक्षम एआई को विकसित करने के लिए लाभ प्राप्त करता है। अनुसंधान हमारे बीच *खेल पर केंद्रित है, जहां crumats को मौखिक चर्चाओं के माध्यम से imposter की पहचान करनी चाहिए। शोधकर्ताओं ने एक प्रशिक्षण विधि तैयार की है जो संचार और बोलने में बोलने में साझा करती है, एआई को स्वतंत्र रूप से ze को दोनों कौशल को जोड़ने की अनुमति देता है। यह विधि संरचित पुरस्कार प्रणाली को एकीकृत करती है जो एजेंटों को उनकी चर्चा तकनीकों में सुधार करने में सक्षम बनाती है।
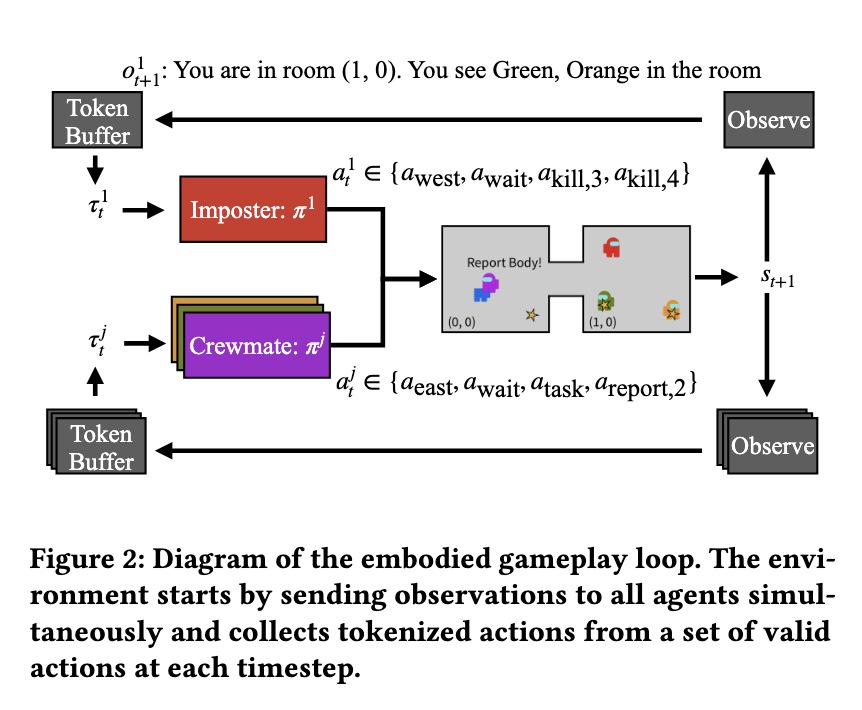
विधि एक GA ENSE रिवार्ड सिग्नल का प्रतिनिधित्व करती है जो संचार में सुधार करने के लिए एक निश्चित प्रतिक्रिया प्रदान करती है। एआई एजेंटों ने पिछली चर्चाओं के आधार पर पर्यावरणीय विवरण की भविष्यवाणी करके अपनी सुनवाई की क्षमता बढ़ाई। इसी समय, उनके बोलने की महारत सुदृढीकरण शिक्षा के माध्यम से सुधार करती है, जहां संदेशों का मूल्यांकन अन्य एजेंटों के विश्वासों पर उनके प्रभाव के आधार पर किया जाता है। यह संरचनात्मक दृष्टिकोण यह सुनिश्चित करता है कि एआई-जनित संदेश तार्किक, प्रेरक और संचार के लिए प्रासंगिक हैं। अनुसंधान टीम ने RWKV को नियोजित किया, जो एक आवर्तक तंत्रिका नेटवर्क मॉडल है, जो उनके प्रशिक्षण की नींव के रूप में, इसे लंबे समय से चर्चा और गतिशील गेमप्ले वातावरण के लिए ptomized किया।
प्रायोगिक परिणामों से पता चला कि इस प्रशिक्षण दृष्टिकोण ने पारंपरिक सुदृढीकरण सीखने की तकनीकों की तुलना में एआई संचालन में काफी सुधार किया है। प्रशिक्षित एआई ने मानव खिलाड़ियों के समान व्यवहार का प्रदर्शन किया, जिसमें संदिग्ध आरोप, साक्ष्य प्रस्तुति और अवलोकन कार्यों के आधार पर तर्क शामिल हैं। अध्ययनों से पता चला है कि इस संरचित चर्चा सीखने के ढांचे का उपयोग करते हुए, एआई मॉडल ने एक संरचित संवाद फ्रेमवर्क के बिना सुदृढीकरण सीखने के मॉडल की 28% जीत दर में से लगभग 56% की जीत दर हासिल की है। इसके अलावा, एआई ने इस पद्धति का उपयोग करके प्रशिक्षित किया, आकार में चार गुना बड़े मॉडल, प्रस्तावित प्रशिक्षण रणनीति की कार्यक्षमता को रेखांकित करते हैं। चर्चा के व्यवहार का विश्लेषण करते हुए, अनुसंधान टीम ने देखा कि एआई बेसलाइन सुदृढीकरण शिक्षा के दृष्टिकोण के रूप में दो बार सफलता की दर पर प्रतिरूपकों की सटीक रूप से पहचान कर सकता है।
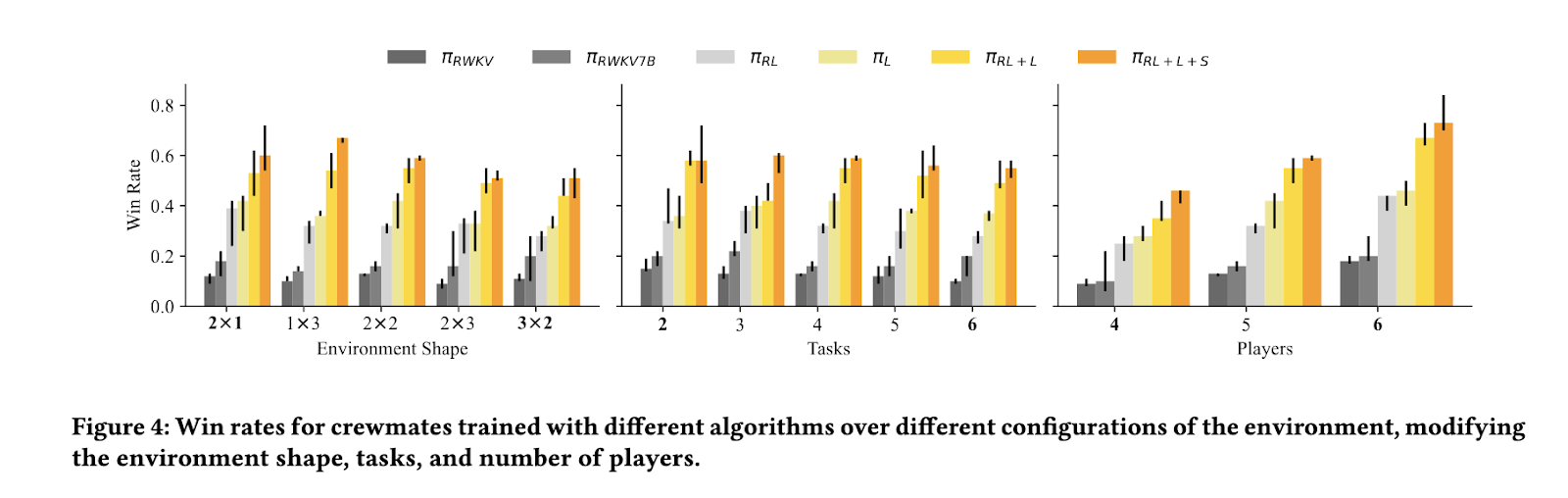
आगे के विश्लेषण से पता चलता है कि इस ढांचे के तहत प्रशिक्षित एआई मॉडल प्रभावी रूप से एंटी -स्ट्रेट के लिए अनुकूल हैं। Imposters ने अपराध को स्थानांतरित करके चर्चा में हेरफेर करने की कोशिश की, शुरू में AI crumats को भ्रमित किया। हालांकि, एआई एजेंटों ने वास्तविक आरोपों और दोहराव प्रशिक्षण के माध्यम से भ्रामक बयानों के बीच अंतर करना सीखा। शोधकर्ताओं ने पाया कि एआई-जनित संदेश जिन्हें स्पष्ट रूप से संदिग्ध नामित किया गया है, ने समूह के फैसलों को प्रभावित किया। यह उभरता हुआ व्यवहार बारीकी से उपलब्ध है। यह दर्शाता है कि एआई गतिशील रूप से बहस की रणनीति के अनुकूल हो सकता है।
यह शोध एआई-संचालित सामाजिक कटौती में महत्वपूर्ण प्रगति को चिह्नित करता है। मल्टी-एजेंट सेटिंग्स में संचार की चुनौतियों को संबोधित करते हुए, अध्ययन व्यापक मानव प्रदर्शन पर भरोसा किए बिना एक सार्थक बहस में संलग्न होने के लिए एआई एजेंटों को प्रशिक्षित करने के लिए एक संरचित और प्रभावी संरचना प्रदान करता है। प्रस्तावित विधि एआई निर्णय लेने में अधिक है, जो पर्यावरण में अधिक प्रेरक और तार्किक तर्क की अनुमति देता है जिसे सहयोग और धोखा जांच की आवश्यकता होती है। यह शोध व्यापक अनुप्रयोगों के लिए संभावनाओं को खोलता है, जिसमें एआई सहायकों, वार्ता और वास्तविक दुनिया के विचार शामिल हैं जो जटिल चर्चाओं का विश्लेषण करने में सक्षम हैं।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
निखिल मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह खड़गपुर में भारतीय संगठन की प्रौद्योगिकी में सामग्री में दोहरी डिग्री प्राप्त कर रहा है। निखिल एआई/एमएल उत्साही है जो हमेशा बायोमेट्रियल और बायोमेडिकल विगल्स जैसे क्षेत्रों में आवेदन पर शोध करता है। भौतिक अभिव्यक्ति में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति और योगदान की संभावना की तलाश कर रहा है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)