


Си Ян
Биомедицинский домен представляет собой сложную сеть взаимосвязанных знаний, охватывающих генетику, заболевания, лекарства и биологические процессы. В то время как графики знаний (KGS) преуспевают в организации и связывании этой информации, их сложность часто затрудняет запрос пользователей. В идеале пользователи должны иметь возможность задавать вопросы на естественном языке и получать точные ответы непосредственно от KG, без необходимости специализированного опыта запроса. Тем не менее, позволяет глубокому обучению системы запросить KGS с использованием естественного языка, остается серьезной проблемой. Существующие наборы данных о биомедицинском графике знаний (Biokgqa) малы и ограничены по объему, обычно содержащие только несколько сотен вопросов, отвечающих (QA). Эта нехватка данных препятствует разработке надежных и масштабируемых систем QA, которые необходимы для критических приложений, таких как поддержка клинических решений, персонализированная медицина и обнаружение лекарств.
PrimeKGQA решает эти проблемы с новым, масштабируемым подходом к генерации наборов данных, используя силу крупных языковых моделей (LLMS). Построенный на PrimeKG-графике знаний, ориентированного на точную медицину, который интегрирует данные из 20 наиболее цитируемых биомедицинских баз данных, охватывающих десять биологических шкал, включая гены, заболевания и лекарства-Primekgqa использует общую, масштабируемую и без обучения основы. Полем Используя несколько выстрелов с LLMS, структура преобразует подграфы KG (на основе сетевых мотивов, см. Рисунок 1) в запросы Sparql, которые впоследствии преобразуются в пары вопросов на естественном языке. Полученный набор данных PrimeKGQA охватывает широкий спектр биомедицинских концепций и сложностей рассуждений, начиная от простых фактических запросов и заканчивая сложными путями рассуждений с несколькими ходами, обеспечивая комплексный ресурс для продвижения биомедицинских систем-ответов.
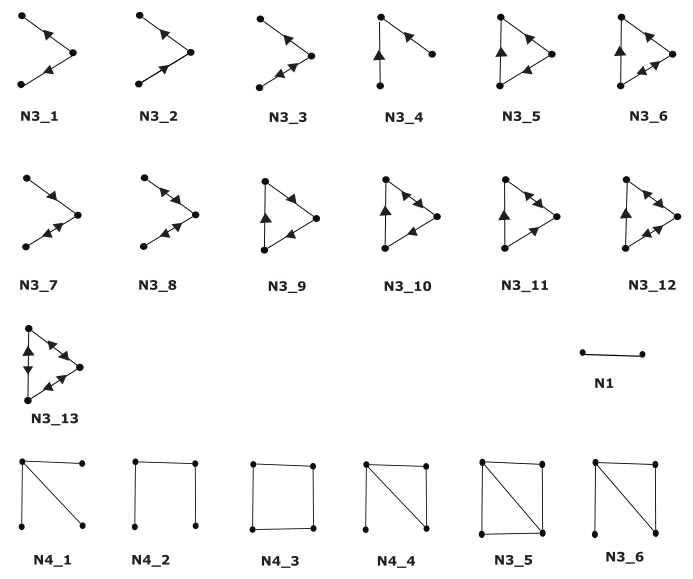 Рисунок 1: Все типы сетевых мотивов для графиков с номерами узлов от двух до четырех. N3_1 означает «Узел № 3 подграфа типа 1». Обратите внимание, что для 3-узловых-субграфов мы отказываемся от N3_5, N3_6, N3_9, N3_10, N3_11, N3_12 и N3_13.
Рисунок 1: Все типы сетевых мотивов для графиков с номерами узлов от двух до четырех. N3_1 означает «Узел № 3 подграфа типа 1». Обратите внимание, что для 3-узловых-субграфов мы отказываемся от N3_5, N3_6, N3_9, N3_10, N3_11, N3_12 и N3_13.
Primekgqa выделяется не только за его размер, но и за его полную. С 83 999 пар QA, он в 1000 раз больше, чем следующий крупнейший набор данных Biokgqa. Набор данных включает вопросы, сгенерированные от подграфов от 2 до 4 узлов, предлагая сбалансированное сочетание простых и сложных аргументирующих задач. Вопросы оцениваются по лингвистической правильности, семантической верности и грамматической точности, обеспечивая сильное согласование с биомедицинскими фактами кг, которые он представляет.
Создание Primekgqa следует за инновационным трубопроводом. 1. Отбор проб подграфа: подграф из PrimeKG извлекаются на основе сетевых мотивов, от простых 2-узловых структур до более сложных 4-узловых конфигураций. 2. Проверка Sparql: запросы sparql используются для проверки ответов, извлеченных из подграфов, обеспечивая правильность ответа. 3. Генерация вопросов: предварительно обученные языковые модели, такие как GPT3, Mistral и Llama, предлагается генерировать вопросы естественного языка на основе структур подграфов и подтвержденных ответов. Подробный трубопровод можно найти на рисунке 2.
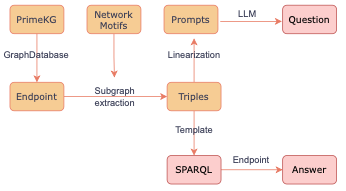 Рисунок 2. Наш трубопровод для автоматической генерации Primekgqa. Розовые блоки – это композиционные элементы набора данных, то есть естественный вопрос, sparql, правильный ответ из кг.
Рисунок 2. Наш трубопровод для автоматической генерации Primekgqa. Розовые блоки – это композиционные элементы набора данных, то есть естественный вопрос, sparql, правильный ответ из кг.
Известно, что данные, сгенерированные LLM, страдают от галлюцинации, которая в нашей задаче оценивается в трех измерениях: грамматичность, согласованность (соответствуют ли вопрос и ответ) и покрытие (выравнивается ли вопрос и запрос sparql). Чтобы оценить это, мы используем как автоматическую, так и ручную оценку. Установленные тесты, такие как Bleu, Rouge и Meteor, используются для измерения лингвистического качества, в то время как метрики на основе LLM, такие как Bertscore, обеспечивают семантическое выравнивание. Кроме того, доменные эксперты оценивают образцы по грамматичности, последовательности и охвату, обеспечивая человеку общее качество набора данных.
В то время как Primekgqa устанавливает новый эталон для наборов данных Biokgqa, работа далеко не завершена. По-прежнему есть возможности для улучшения, например, после редактирования и исправления проблемных вопросов. Кроме того, в этом наборе данных еще не было проверено. Будущая работа будет сосредоточена: усовершенствование процесса генерации вопросов для захвата более тонких и исследовательских запросов и использования Primekgqa для сравнения существующих систем QA для оценки их эффективности в реальных биомедицинских задачах.
Хотите исследовать Primekgqa для себя? Набор данных и модели доступны на GitHub.
Прочитайте работу в полном объеме
Соединение пробела: генерирование комплексного набора данных о биомедицинском графике знаний, Си Ян, Патрик Вестфаль, Ян Селигер и Рикардо УсбекEcai 2024.
Это исследование было представлено в ECAI 2024.
Теги: Deep Dive, Ecai, Ecai2024

Си Ян – аспирант в Университете Гамбурга
Си Ян – аспирант в Университете Гамбурга


