

एक नया अध्ययन LMU म्यूनिख, मशीन लर्निंग के लिए म्यूनिख केंद्र, और एडोब शोधकर्ताओं को कमजोरियों से अवगत कराया गया है। एआई भाषा मॉडल: वे लंबे दस्तावेजों को समझने के लिए संघर्ष करते हैं जो आपको आश्चर्यचकित कर सकते हैं। अनुसंधान टीम के निष्कर्ष बताते हैं कि जब बहुत उन्नत एआई मॉडल को जानकारी को जोड़ने में कठिनाई होती है जब वे सरल शब्द मिलान पर भरोसा नहीं कर सकते हैं।
एआई के पढ़ने के कौशल के साथ छिपी एक समस्या
एक लंबे शोध पत्र में विशिष्ट विवरण खोजने की कोशिश कर रहा है। आप इसके माध्यम से योजना बना सकते हैं, विभिन्न वर्गों के बीच मानसिक संबंध बना सकते हैं ताकि आप एक साथ जानकारी प्राप्त कर सकें। कई एआई मॉडल, यह पता चला है, इस तरह से काम नहीं करता है। इसके बजाय, वे हमेशा एक विशिष्ट शब्द मैच खोजने पर निर्भर करते हैं, जो आपके कंप्यूटर पर CTRL+F का उपयोग करने के समान है।
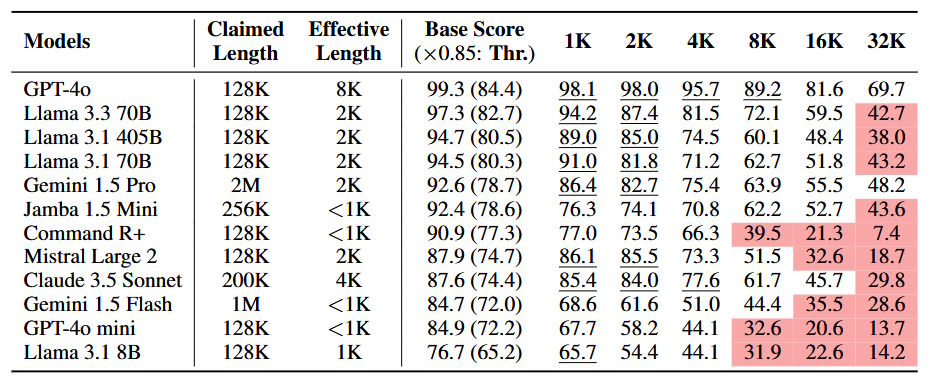
अनुसंधान टीम ने विभिन्न एआई मॉडल डेलो का परीक्षण करने के लिए नोलिमा (शाब्दिक रूप से मिलान नहीं) नामक एक नया बेंचमार्क विकसित किया। परिणाम बताते हैं कि जब एआई मॉडल 2,000 शब्दों से अधिक समय तक ग्रंथों से निपटते हैं, तो उनका प्रदर्शन नाटकीय रूप से गिरता है। लघु पुस्तक की लंबाई के बारे में – जब तक वे 32,000 शब्दों तक पहुंचते हैं – अधिकांश मॉडल अपनी सामान्य क्षमता के आधे पर प्रदर्शित होते हैं। इसमें प्रमुख मॉडल के परीक्षण शामिल हैं जीपीटी, मिथुन 1.5 प्रोऔर लालमा 3.3 70 बी।
रोगी रिकॉर्ड का विश्लेषण करने के लिए AI का उपयोग करके एक चिकित्सा शोधकर्ता या केस दस्तावेजों की समीक्षा करने के लिए AI का उपयोग करके एक कानूनी टीम पर विचार करें। यदि AI महत्वपूर्ण कनेक्शन याद करता है क्योंकि संबंधित जानकारी खोज क्वेरी की तुलना में अलग -अलग शब्दों का उपयोग करती है, तो परिणाम महत्वपूर्ण हो सकते हैं।
क्यों एक शब्द मिलान पर्याप्त नहीं है
वर्तमान एआई मॉडल ध्यान की विधि के रूप में जानी जाने वाली चीज़ का उपयोग करके पाठ को संसाधित करते हैं। यह प्रणाली शब्दों और विचारों के बीच संबंध को समझने के लिए पाठ के विभिन्न हिस्सों पर ध्यान केंद्रित करने में मदद करती है। छोटे ग्रंथों के साथ काम करते समय, यह अच्छी तरह से काम करता है। हालांकि, शोध से पता चलता है कि ग्रंथ लंबे समय तक इस तंत्र से भरे हुए हैं, खासकर जब यह एक निश्चित शब्द मैच पर भरोसा नहीं कर सकता है।
नोलिमा टेस्ट ने एआई मॉडल सवाल पूछकर सीमा की घोषणा की है, जहां मैचिंग शब्दों को खोजने के बजाय एक समझ देने के लिए उत्तर की आवश्यकता है। परिणाम कह रहे थे। जब मॉडल डेलो ने छोटे ग्रंथों के साथ अच्छा प्रदर्शन किया, तो पाठ की लंबाई बढ़ने पर इन कनेक्शनों को काफी कम करने की उनकी क्षमता। लंबे दस्तावेजों से निपटने के दौरान 50% सटीकता से नीचे तर्क के लिए डिज़ाइन किए गए विशेष मॉडल।
मिलान शब्द के बिना, एआई मॉडल डेलो ने इसके लिए संघर्ष किया:
- संबंधित अवधारणाएं जो विभिन्न शब्दावली का उपयोग करती हैं
- मल्टी-स्टेप लॉजिक पथ का पालन करें
- संदर्भ के बाद कुंजी प्रकट होने पर प्रासंगिक जानकारी का पता लगाएं
- अप्रासंगिक भागों में भ्रामक शब्द मैचों को अनदेखा करें
संख्याएँ कहानी बताती हैं
शोध के निष्कर्षों ने एक तस्वीर चित्रित की कि कैसे एआई मॉडल लंबे ग्रंथों को संभालते हैं। GPT-4 ने लगभग 8,000 टोकन (लगभग 6,000 शब्दों) तक की प्रभावशीलता को बनाए रखकर सबसे मजबूत प्रदर्शन दिखाया। हालांकि, इस शीर्ष घंटे ने लंबे ग्रंथों के साथ एक महत्वपूर्ण कमी भी दिखाई। मिथुन 1.5 प्रो और लालामा 3.3 70 बी सहित अधिकांश अन्य मॉडल, 2,000 और 8,000 टोकन के बीच तेज प्रदर्शन में कमी का अनुभव करते हैं।
जब कार्यों को कई तर्क चरणों की आवश्यकता होती है, तो प्रदर्शनी में कमी अधिक स्पष्ट हो गई। उदाहरण के लिए, यदि किसी मॉडल को दो तार्किक कनेक्शन बनाने की आवश्यकता थी – जैसे कि एक चरित्र लैंडमार्क के करीब रहता था, और यह लैंडमार्क एक निश्चित शहर में था – सफलता की दर में काफी गिरावट आई। अनुसंधान दिखाता है चेन थिंकिंग।
ये निष्कर्ष विशेष रूप से उल्लेखनीय हैं कि वे लंबे संदर्भों का प्रबंधन करने के लिए एआई मॉडल की क्षमता के बारे में दावों को चुनौती देते हैं। जबकि कई मॉडल व्यापक संदर्भ खिड़कियों के लिए समर्थन की घोषणा करते हैं, नोलिमा बेंचमार्क से पता चलता है कि इस सैद्धांतिक सीमा तक पहुंचने से पहले प्रभावी समझ बेहतर है।
स्रोत: Moderesi et al।
जब ऐ एक पेड़ के लिए जंगल को याद करता है
इन सीमाओं पर हम इस बात पर गंभीर प्रभाव डालते हैं कि हम वास्तविक दुनिया के अनुप्रयोगों में एआई का उपयोग कैसे करते हैं। केस लॉ द्वारा आविष्कार किए गए कानूनी एआई प्रणाली पर विचार करें। वे केवल संबंधित पैटर्न को याद कर सकते हैं क्योंकि वे खोज क्वेरी की तुलना में विभिन्न शब्दावली का उपयोग करते हैं। सिस्टम बल्कि कम संबंधित मामलों पर ध्यान केंद्रित कर सकता है जो खोज शब्दों के साथ अधिक शब्दों को साझा करने के लिए होते हैं।
खोज और दस्तावेज़ विश्लेषण पर प्रभाव विशेष रूप से प्रासंगिक है। वर्तमान AI -Powered खोज प्रणाली अक्सर नाम की तकनीक पर निर्भर करती है पुनर्वास-पीढ़ी (चीर)। यहां तक कि जब ये सिस्टम सफलतापूर्वक सही जानकारी के साथ एक दस्तावेज़ प्राप्त करते हैं, तो AI अपनी प्रासंगिकता की पहचान करने में विफल हो सकता है यदि शब्द क्वेरी से अलग हैं। इसके बजाय, एआई कम संबंधित दस्तावेजों को गुरुत्वाकर्षण कर सकता है जो खोज शब्दों के साथ सतह-स्तर की समानताएं साझा करते हैं।
एआई उपयोगकर्ताओं के लिए, ये निष्कर्ष कई महत्वपूर्ण विचारों का सुझाव देते हैं:
पहलालघु प्रश्न और दस्तावेज अधिक विश्वसनीय परिणाम देंगे। लंबे ग्रंथों के साथ काम करते समय, उन्हें एक छोटे, केंद्रित खंड में तोड़ना एआई संचालन को बनाए रखने में मदद कर सकता है।
दूसराएआई को एक लंबे दस्तावेज़ के विभिन्न हिस्सों में संबंध बनाने के लिए पूछते समय उपयोगकर्ताओं को विशेष रूप से सावधान रहना चाहिए। अनुसंधान से पता चलता है कि एआई मॉडल सबसे अधिक संघर्षशील हैं जब विभिन्न विभागों से एक साथ जानकारी की आवश्यकता होती है, खासकर जब कनेक्शन साझा शब्दावली द्वारा स्पष्ट नहीं होता है।
अंत मेंये सीमाएं मानव अवलोकन के निरंतर महत्व को उजागर करती हैं। जबकि AI पाठ की प्रक्रिया और विश्लेषण के लिए एक शक्तिशाली उपकरण हो सकता है, यह लंबे या जटिल दस्तावेजों में महत्वपूर्ण कनेक्शनों की पहचान करने के एकमात्र साधन के रूप में निर्भर नहीं होना चाहिए।
निष्कर्ष एक अनुस्मारक के रूप में काम करते हैं कि एआई प्रौद्योगिकी में तेजी से प्रगति के बावजूद, ये सिस्टम अभी भी मनुष्यों से बहुत अलग जानकारी संसाधित करते हैं। इन सीमाओं को समझना AI उपकरणों का प्रभावी ढंग से उपयोग करने और मानव निर्णय की आवश्यकता कब है, यह जानने के लिए महत्वपूर्ण है।
आगे क्या आता है
वर्तमान एआई मॉडल की सीमाओं को समझने के लिए लंबे ग्रंथों की सीमाओं को समझना एआई विकास के भविष्य के बारे में महत्वपूर्ण सवालों को खोलता है। नोलिमा बेंचमार्क से पता चला है कि एआई पाठ प्रसंस्करण के लिए हमारे वर्तमान दृष्टिकोणों को महत्वपूर्ण शुद्धि की आवश्यकता हो सकती है, विशेष रूप से मॉडल कैसे लंबी -लंबी जानकारी को संभालते हैं।
वर्तमान समाधान केवल आंशिक सफलता दिखाते हैं। चेन-एफ-थिंकिंग प्रॉम्प्टिंग, जो एआई मॉडल को कदम में अपने तर्क को तोड़ने के लिए प्रोत्साहित करता है, कुछ हद तक प्रदर्शन में सुधार करने में मदद करता है। उदाहरण के लिए, इस तकनीक का उपयोग करते समय, लालमा 3.3 70 बी ने लंबे संदर्भों को संभालने की बेहतर क्षमता दिखाई। हालांकि, यह दृष्टिकोण अभी भी कम है जब 16,000 टोकन से परे ग्रंथों से निपटने के लिए, यह सुझाव देते हुए कि हमें अधिक बुनियादी समाधानों की आवश्यकता है।
ध्यान तंत्र, जो पाठ को संसाधित करने वाले वर्तमान एआई मॉडल के पीछे बनाता है, पर पुनर्विचार करने की आवश्यकता है। एक भीड़ भरे कमरे में संवाद करने की कोशिश करने जैसे विचार – बातचीत जितनी लंबी होगी, पहले बताए गए सभी महत्वपूर्ण मुद्दों को रखना मुश्किल हो जाता है। हमारे वर्तमान एआई मॉडल एक ही चुनौती का सामना करते हैं, लेकिन बहुत बड़े पैमाने पर।
भविष्य को देखते हुए, शोधकर्ता कई होनहार दिशाओं की तलाश कर रहे हैं। एक दृष्टिकोण में एआई के लिए नए तरीके विकसित करना और लंबे ग्रंथों में जानकारी को व्यवस्थित करने और पसंद करने के लिए, गहरे वांडा फंतासी कनेक्शन को समझने के लिए सरल शब्द मिलान के साथ। यह इस बात पर अधिक काम कर सकता है कि यह मनुष्य कैसे जानकारी के मानसिक नक्शे बनाता है, बस साझा शब्दावली के बजाय अर्थ के आधार पर विचारों को जोड़ता है।
विकास का एक अन्य क्षेत्र सुधार पर केंद्रित है कि एआई मॉडल एआई मॉडल को “सपर हॉप्स” नामक एआई मॉडल को कैसे संभालते हैं – विभिन्न जानकारी के टुकड़ों को जोड़ने के लिए आवश्यक तार्किक कदम। वर्तमान मॉडल इन कनेक्शनों के साथ संघर्ष करते हैं, विशेष रूप से लंबे ग्रंथों में, लेकिन नए आर्किटेक्ट इस दूरी को दूर करने में मदद कर सकते हैं।
आज एआई टूल के साथ काम करने वालों के लिए, ये निष्कर्ष कई व्यावहारिक दृष्टिकोणों का सुझाव देते हैं:
एआई के साथ काम करते समय एक सार्थक खंड में लंबे दस्तावेजों को तोड़ने के बारे में सोचें। यह तार्किक खंड बनाने में मदद करता है जो महत्वपूर्ण संदर्भ को संरक्षित करते हैं। उदाहरण के लिए, यदि किसी शोध का कागज द्वारा विश्लेषण किया जाता है, तो आप विधि और परिणाम अनुभागों को एक साथ रख सकते हैं क्योंकि इसमें अक्सर प्रासंगिक जानकारी होती है।
जब एआई को लंबे ग्रंथों का विश्लेषण करने के लिए कहा जाता है, तो उन कनेक्शनों के बारे में विशेष रहें जिन्हें आप बनाना चाहते हैं। व्यापक प्रश्न पूछने के बजाय, एआई को एक विशिष्ट संबंध के लिए गाइड करें जिसे आप खोज में रुचि रखते हैं। यह इन कनेक्शनों को स्वतंत्र रूप से बनाने के लिए मॉडल की वर्तमान सीमाओं की भरपाई करने में मदद करता है।
शायद सबसे महत्वपूर्ण बात, लंबे ग्रंथों के साथ एआई की क्षमताओं के बारे में वास्तविक अपेक्षाओं को बनाए रखें। जबकि ये उपकरण कई कार्यों के लिए असत्य रूप से सहायक हो सकते हैं, उन्हें जटिल दस्तावेजों के मानव विश्लेषण के लिए पूर्ण प्रतिस्थापन नहीं माना जाना चाहिए। संदर्भ बनाए रखने और लंबे ग्रंथों में फंतासी कनेक्शन बनाने की मानवीय क्षमता वर्तमान एआई क्षमताओं से बेहतर है।
इस क्षेत्र में एआई विकास का तरीका चुनौतीपूर्ण और रोमांचक दोनों है। जैसा कि हम इन सीमाओं को बेहतर ढंग से समझते हैं, हम एआई सिस्टम की ओर काम कर सकते हैं जो वास्तव में उन्हें संसाधित करने के बजाय लंबे ग्रंथों को समझते हैं। तब तक, एआई का उपयोग अपनी शक्ति की सराहना करते समय अपनी वर्तमान सीमाओं के साथ प्रभावी ढंग से काम करना है।


