


Квантование является важным методом глубокого обучения для снижения вычислительных затрат и повышения эффективности модели. Крупномасштабные языковые модели требуют значительной мощности обработки, что делает квантование необходимым для минимизации использования памяти и повышения скорости вывода. Конвертируя высокие веса в более низкие форматы, такие как int8, int4 или int2, квантование снижает требования к хранению. Тем не менее, стандартные методы часто снижают точность, особенно при низких точках, таких как int2. Исследователи должны поставить под угрозу точность для эффективности или поддерживать несколько моделей с различными уровнями квантования. Новые стратегии необходимы для сохранения качества модели при оптимизации вычислительной эффективности.
Фундаментальная проблема с квантованием заключается в том, чтобы точно справляться с точностью. Подходы, доступные до сих пор, либо обучают уникальные модели на точность, либо не используют преимущества иерархического характера типа целочисленного типа. Потеря о точности в квантовании, как и в случае с Int2, наиболее сложна, потому что ее память получает широко распространенное использование. LLM, такие как GEMMA-2 9B и MISTRAL 7B, очень интенсивно вычисляют, и метод, который позволяет одной модели работать на множественных уровнях точности, значительно повысит эффективность. Необходимость высокопроизводительного метода гибкого квантования побудила исследователей искать решения вне традиционных методов.
Существует несколько методов квантования, каждая балансируя точность и эффективность. Методы без обучения, такие как Minmax и GPTQ, используют статистическое масштабирование для картирования весов модели с более низкой шириной битов без модификации параметров, но они теряют точность при низких точности. Основанные на обучении методы, такие как обучение квантованию (QAT) и всемогущие оптимизированные параметры квантования с использованием градиентного происхождения. QAT обновляет параметры модели, чтобы снизить потерю посткватизации, в то время как всеобъемлющий учится масштабировать и сдвинуть параметры без изменения веса ядра. Тем не менее, оба метода по -прежнему требуют отдельных моделей для разных точностей, усложняющих развертывание.
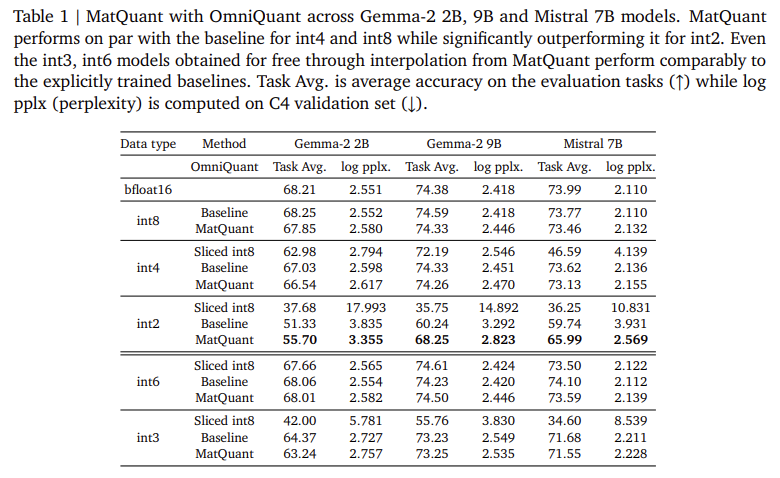
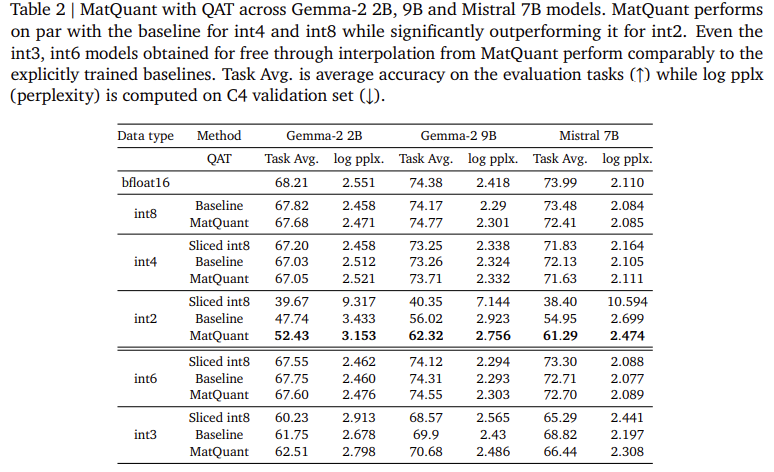
Исследователи в Google DeepMind представили Квантование Matryoshka (Matquant) Чтобы создать единственную модель, которая функционирует на многочисленных уровнях точности. В отличие от традиционных методов, которые обрабатывают каждую ширину битов отдельно, Matquant оптимизирует модель для Int8, Int4 и Int2, используя общее представление битов. Это позволяет развертываться модели в разных точностях без переподготовки, снижения затрат на вычислительные и хранения. Matquant извлекает более низкие модели из модели с высоким отрывом, сохраняя точность, используя иерархическую структуру типов целочисленных данных. Тестирование на моделях GEMMA-2 2B, GEMMA-2 9B и MISTRAL 7B показало, что Matquant повышает точность Int2 на 10% по сравнению с стандартными методами квантования, такими как QAT и Omniquant.
Matquant представляет веса модели на разных уровнях точности, используя общие наиболее значимые биты (MSB) и оптимизирует их совместно для поддержания точности. Процесс обучения включает в себя совместное обучение и совместную дистилляцию, гарантируя, что представление Int2 сохраняет критическую информацию, обычно теряющуюся при традиционной квантовании. Вместо того, чтобы отбросить более низкие структуры, Matquant интегрирует их в многомасштабную структуру оптимизации для эффективного сжатия без потери производительности.
Экспериментальные оценки Matquant демонстрируют его способность смягчить потерю точности от квантования. Исследователи проверили метод на основе трансформатора LLM, сосредоточившись на квантовании параметров сети подачи (FFN), что является ключевым фактором задержки вывода. Результаты показывают, что модели Matquant Int8 и Int4 достигают сопоставимой точности с независимыми обученными базовыми показателями, превосходя их в Precision Int2. На модели GEMMA-2 9B Matquant улучшил точность Int2 на 8,01%, в то время как модель Mistral 7B наблюдается на 6,35% улучшении по сравнению с традиционными методами квантования. Исследование также показало, что квантованное распределение веса Matquant повышает точность во всех битовых ширинах, в частности, приносят пользу моделям с более низким характером. Кроме того, Matquant обеспечивает бесшовную битовую интерполяцию и конфигурации по сложному миксу, позволяя гибко развертываться на основе аппаратных ограничений.
Несколько ключевых выводов возникают из исследования Matquant:
- Квантование многомасштабного: Matquant вводит новый подход к квантованию путем обучения одной модели, которая может работать на нескольких уровнях точности (например, Int8, Int4, Int2).
- Эксплуатация вложенной структуры битов: методика использует вложенную вложенную структуру в типах целочисленных данных, что позволяет получению меньших целых чисел битовой ширины из более крупных.
- Повышенная точность низкой конкретной оценки: Matquant значительно повышает точность квантованных моделей Int2, опережая традиционные методы квантования, такие как QAT, и всеобъемлющий до 8%.
- Универсальное применение: Matquant совместим с существующими методами квантования, основанными на обучении, такими как обучение, осведомленное о квантовании (QAT) и всеобщее.
- Продемонстрированная производительность: метод был успешно применен для квантования параметров FFN LLM, таких как GEMMA-2 2B, 9B и MISTRAL 7B, демонстрируя свою практическую полезность.
- Повышение эффективности: Matquant позволяет создавать модели, которые обеспечивают лучший компромисс между точностью и вычислительными затратами, что делает их идеальными для ограниченных ресурсов.
- Парето-оптимальные компромиссы: это обеспечивает бесшовную добычу интерполятивной битовой ширины, таких как Int6 и Int3, и признает плотную точность против стоимости парето-оптимального компромисса, обеспечивая слой с микс. различные точки.
В заключение, Matquant представляет решение для управления несколькими квантованными моделями, используя многомасштабный подход обучения, который использует вложенную структуру типов целочисленных данных. Это обеспечивает гибкий, высокопроизводительный вариант для низкоква на квантовании при эффективном выводе LLM. Это исследование демонстрирует, что одна модель может быть обучена работать на многочисленных уровнях точности без значительного снижения точности, особенно при очень низкой ширине битов, что отмечает важный прогресс в методах квантования модели.
Проверить бумага. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 75K+ ML SubredditПолем
🚨 Рекомендуемая платформа для ИИ с открытым исходным кодом: «Intellagent-это многоагентная среда с открытым исходным кодом для оценки сложной разговорной системы ИИ‘ (Продвигается)
ASIF Razzaq является генеральным директором Marktechpost Media Inc. как дальновидного предпринимателя и инженера, ASIF стремится использовать потенциал искусственного интеллекта для социального блага. Его последнее усилие-запуск медиа-платформы искусственного интеллекта, Marktechpost, которая выделяется благодаря глубокому освещению машинного обучения и новостей о глубоком обучении, которое является технически обоснованным и легко понятным для широкой аудитории. Платформа может похвастаться более 2 миллионами ежемесячных просмотров, иллюстрируя свою популярность среди зрителей.
✅ (рекомендуется) присоединиться к нашему каналу Telegram


