


Increasing need for scalable logic models in machine intelligence
Advanced logic models are at the boundary of machine intelligence, especially in domains such as mathematical problems and symbolic logic. These models are designed to perform multi-step calculations and logical deductions, often producing solutions that give mirrors to human logic processes. Reinforcement learning techniques are used to improve accuracy after printing; However, scaling these methods is a complex challenge when maintaining efficiency. As the demand for small, more resource-efficient models delo is increasing, which still shows high logic capabilities, researchers are now turning to strategies addressing data quality, research methods, and long-range generalization.
Challenges in reinforcement education for big logic architectures
The constant problem of learning reinforcement for large -scale logic models does not match the ability of the model and the difficulty of training data. When a model comes in contact with very simple tasks, its learning curve stabilizes. On the contrary, excessive difficult data can clash the model and receive a learning signal. This problem imbalance is especially pronounced when applying well -working recipes for large models for smaller models. Another point is that the lack of rollout variations and methods to effectively adapt to the output length during both training and inference, which leads to the logic capabilities of the model on the complex benchmark.
Limitations of approaches after training on advanced models
Previous approaches, such as dipscalers and GRPOs, show that reinforcement education can improve with 1.5 billion dimensions in the influence of small-way logic models. However, applying these similar recipes to more capable models, such as QWEN3-4B or Deepsk-R1-Distil-Quan-7B, results in marginal benefits or even display drops. One of the main limits is the stable nature of the data distribution and a limited variety of sample. Most of these approaches do not filter data based on model capacity, or do not adjust the length of the sample temperature or response over time. As a result, when used on more advanced architectures, they fail to effectively scale.
Introduction to Polaris: A corresponding recipe for Scalable RL in logic tasks
Researchers at the University of Hong Kong University, Bidens Sid and Fooden introduced Polaris, a training recipe, especially designed to scales reinforcement education for advanced logic tasks. Polaris consists of two preview models: Polaris -4B -Purawa and Polaris -7B -Purvalocan. Polaris-4B-alphabeton is nice from QWN3-4B, while Polaris-7B-3 is based on Deepsik-R1-Distil-Quan-7B. Researchers focused on creating a model-agnostic framework that changes the difficulty of data, promotes various research by controlled sample temperature, and expands the estimate capacity by extrapolation of length. These strategies were developed using open-sores datasets and training pipelines, and both models are Optim Ptimized to operate on Consumer-Grade Graphics Processing Units (GPUs).
Polaris innovation: Balance, controlled samples and difficulty with long context
Polaris applies multiple innovations. First, the training data is cured by eliminating problems that are either very easy or unsolable, creating a mirror J-shaped distribution. This ensures that the training data develops with the growing capabilities of the model. Second, researchers adjust the sample temperature in the training stage using 1.4, 1.45 and 1.4, 1.45 and 1.5 for Polaris -7B to maintain a rollout variety. Moreover, the method employs yarn-based extrapolation technology to extend the estimate reference length to 96K tokens without additional training. This addresses the inability of long-relaxation training by enabling the “train-short, test-long” approach. The model also operates techniques such as a rollout rescue mechanism and intra-batch informative substitute when the model is kept small on zero-pure B ches chess and rollout size.
Benchmark Results: Polaris leads a large commercial models delo
Polaris models receive sophisticated results in multiple mathematical benchmarks. The Polaris-4B-Pupils records 81.2% accuracy on AIM24 on AIM24, on AIM24.4 79.4%, CWN 3-32B on the same functions when using less than 2% of its dimensions. It makes 44.0% on Minerva Mathematics, 69.1% on Olympiad Bench and 94.8% on AMC 23. Polaris -7B -Pupilwalkon also scores 72.6% on AIM 24 and 52.6% on AIM 25. These results show a constant improvement in models such as cloud -4 -OPU and groc -3 -beta, installing Polaris as a competitive, lightweight model that eliminates the gap between small open models and professional 30B+ models.
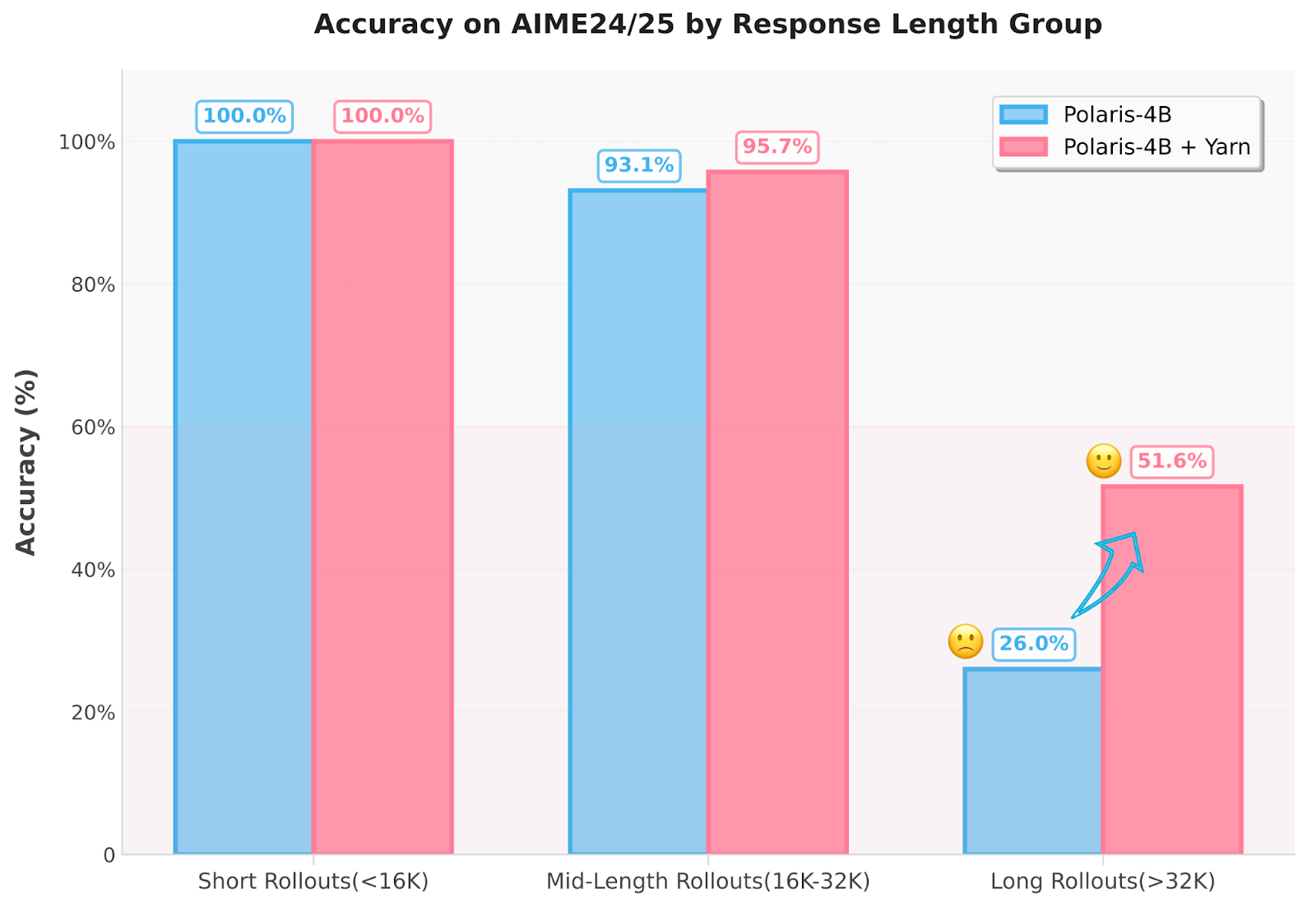
Conclusion: Efficient reinforcement education by smart post-training strategy
Researchers showed that the key to scaling logic models is not only a large model size but also intelligent control over data difficulties, sample variations and inferior length. Polaris provides a reproductive recipe that effectively tunes these elements, with smaller models hit the logic of wider commercial systems.
Check Model and code. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 100 k+ ml subredit And subscribe Our newsletter.
Nikhil is an intern consultant at MarketechPost. He is gaining a dual degree in materials in the technology of the Indian organization in Kharagpur. Nikhil AI/ML is enthusiastic that always researches application in areas such as biometrials and biomedical vigels. With a strong background in the physical expression, he is looking for new progress and chances of contributing.


