

Autonomous coding agents rise in system S. SOFTWARE FIRTWARE DEBING
Traction has been achieved with the emergence of larger language models (LLMS) with the use of AI in SOFTWARE FT WORE Development. These models are able to perform coding-related tasks. This shift has led to the formation of autonomous coding agents that traditionally help or even automate the tasks undertaken by human developers. These agents range from simple script authors to complex systems that are capable of navigating codbase and diagnosing errors. Recently, focusing on enabling these agents to manage more sophisticated challenges. It is especially associated with the wide and complex software ftware environment. These include foundational systems Software Ftware, where certain changes require not only the immediate code but also the architectural reference, inter -relevance and understanding of history of history. Thus, there is an increasing interest in building agents that can logically argue and synthesize improvements or changes with minimal human intervention.
Challenges to debugging large -scale systems code
Updating large -scale systems code presents a multifested challenge due to its underlying size, complexity, and history of history. These systems have thousands of mutually dependent files, such as operating palleting systems and networking stacks. They have been purified for decades by numerous contributors. This leads to a very Optim ptimise, low-level implementation where even minor changes can trigger cascading effects. In addition, traditional bug descriptions in this atmosphere often take the form of raw crash reports and stack traces, which are generally deprived of guidance of natural language signals. As a result, such code requires a DEEP Rand, a reference understanding to diagnose and repair issues. This requires not only the current logic of the code, but also the awareness of its past changes and global design barriers. Automating such a diagnosis and repair has been elusive, as it requires widespread reasoning that most coding agents are not equipped to do.
Limitations of existing coding agents for system-level crash
Popular coding agents, such as sw-agent and openhands, benefit from larger language models (LLMS) for automatic bug fixing. However, they focus mainly on small, application-level codebase. These agents generally depend on the descriptions of the infrastructure issues provided by humans to compress their search and propose solutions. Explore codbase using Syntax-based techniques such as SY Tucoderover. They are often limited to specific languages such as Python and avoids system-level complications. Moreover, any of these methods do not include code evolution insights from committed history, an important component when handling inheritance errors in large -scale codebase. While some code uses heristics for navigation or editing pay generalation, limiting their effectiveness in resolving their inability, complex, system-level crash in the codebase and resolving their inability to consider the history of history.
Code Researcher: A DEEP DEP Search Agent of Micros .Fft
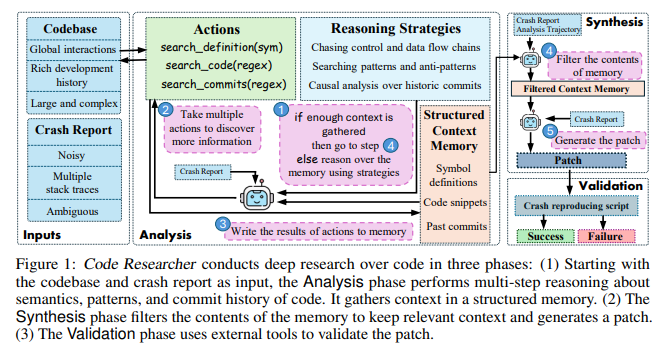
Researchers of Micros .Fft Research introduced CodeEspecially for DEEP DEPAGE ASSIVE ADVERSION Agent for Debugging of System-Series Code. Unlike previous equipment, this agent does not depend on the predefined Genowledge of the spoiled files and works in full unsistured mode. To assess its generalization, the Linux Colonel Crash Benchmark and Multimedia were tested on the Software Fatware Project. The code researcher was designed to operate a multi-phase strategy. First, it analyzes the crash reference using various research actions, such as the symbol definition lookups and pattern discovery. Second, it synthesizes patch solutions based on accumulated evidence. Finally, it validates these patches using automatic testing methods. The agent uses the tools to explore cementics, identify function flow, and analyze a committed history. This is an important innovation in these other systems previously absent. Through this structural process, the agent acts not only as bug fixtures, but also as an autonomous researcher. It collects data and creates hypotheses before interfering with codbase.
Three-Face Architecture: Analysis, Synthesis and Validation
Code researcher’s performance has been broken in three defined stages: analysis, synthesis and validity. In the phase of the analysis, the agent begins by processing the crash report and the repetitive logic steps. Each step includes tool invokations to find symbols, scan for code patterns using regular expressions, and to explore the history of historical accented messages and differences. For example, the agent can invent a word like ‘memory leak’ in the past commit to understand the code changes that can represent instability. The memory that makes it makes, records all questions and its results. When it determines that sufficiently relevant reference has been collected, it is infected to the phase of the synthesis. Here, it filters unrelated data and produces patches by identifying one or more potential defective snippets, even if it spreads to multiple files. In the final belief phase, these patches are tested against the original crash views to test their effectiveness. Only valid solutions are presented for use.

Benchmark exhibition on Linux Colonel and FFMPEG
According to the exhibition, the code researcher made a significant improvement on its predecessor. When a benchmark is done against the cabanchezies, a set of 279 Linux kernel crash produced by Seizkalar Fuusal, it solved 58% crash using GPT -4 on with a 5 -TRGENCE EXECUTION BUSINES. On the contrary, the sw-agent manages only 37.5% resolution rate. On average, code researcher invented 10 files per passage, which is significantly higher than the 1.33 files navigated by SWE-agent. In a subset of 90 cases where both agents modified all the well-known spoiled files, the code researcher resolved 61.1% of the crash against 37.8% by SWE-agent. Moreover, when the O1, the logic-centered model was used only in the patch generation step, the resolution rate was 58%. This strengthens the conclusion that the strong reference logic greatly boosts the debugging results. This approach was also tested on the open source multimedia project FFMPEG. It successfully produces crash-renting patches in 7 out of 10, showing its applicable beyond the kernel code.

The main technical remedy from the Code Researcher Study
- Sw-agent received 58% crash resolution against 37.5% on Linux Colonel Benchmark.
- Compared to 1.33 files by baseline methods, an average of 10 files per bug invent.
- The agent showed effectiveness even when the agent had to find spoiled files without previous guidance.
- The novel use of committed history analysis accelerates the contextual logic.
- Generalized in new domains like FFMPEG, resolving 7 out of 10 registered crash.
- Use of structured memory to maintain and filter reference for patch generation.
- Showed that even when further calculations are given, the DEEP Logy Logic Agents outperform traditional people.
- A valid patches with actual crash restoration product scripts ensure practical effectiveness.
Conclusion: A step towards the autonomous system debugging
In conclusion, this research presents attractive progress in automatic debugging for a large -scale system Software Ftware. By treating bug resolution as a research problem, the requirement of research, analysis and hypothesis testing, the code researcher exemplifies the fate of autonomous agents in the software ftware maintenance. It avoids the problems of the previous equipment by conducting an autonomously conducting a thorough examination of both the current code and its historical hypocritical evolution and synthesizing valid solutions. Significant improvements to the resolution rate, especially in unknown projects such as FFMPEG, show the strength and sculpture of the proposed method. It indicates that Software Ftware agents may be more than reactive respondents; They can act as a capable investigative assistants in making intelligent decisions in a very complex environment that Auto Tomation.
Check Paper. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 100 k+ ml subredit And subscribe Our newsletter.
Asif Razzaq is the CEO of MarketechPost Media Inc. as a visionary entrepreneur and engineer, Asif is committed to increasing the possibility of artificial intelligence for social good. Their most recent effort is the inauguration of the artificial intelligence media platform, MarktecPost, for its depth of machine learning and deep learning news for its depth of coverage .This is technically sound and easily understandable by a large audience. The platform has more than 2 million monthly views, showing its popularity among the audience.


