

Logic tasks are the basic aspect of artificial intelligence, including areas such as commonsense understanding, solving mathematical problems and symbolic logic. These tasks often include several steps of logical prediction, which tries to copy the larger language models delts (LLMS) by structured approaches such as chen-of-thinking (COT) prompting. However, as the LLM grows in size and complexity, they produce prolonged outputs in all functions, regardless of the difficulty, which leads to significant disqualification. The field is striving to adjust the depth of logic with computational costs, while models can adapt to their logic strategy to meet the unique needs of each problem.
The main point of current logic models is the inability to adapt to the logic process of various function complications. Most models, including well-known people like OpenAI’s O1 and Deepsik-R1, apply uniform strategies-in which all functions usually depend on a long cat. This causes “excessive” problems, where models produce unnecessarily verbose explanations for simple tasks. Not only this waste resources, but it also reduces the accuracy, as excessive logic can introduce irrelevant information. Approaches such as prompt-guide pay generation or token budget estimates have tried to reduce the issue. Nevertheless, these methods are limited by their dependence on predefined assumptions, which are not always reliable for various tasks.
Efforts to consider these issues include methods such as GRPO (group-related policy Optim ptimization), length-panel mechanisms and rule-based prompt controls. While the GRPO enables models to learn various logic strategies by rewarding correct answers, it leads to “format fall”, where models depend on the long bed, making more efficient formats such as short cats or direct answers. Length-panel techniques, such as ThinkPrune, are applied in methods such as control output lengths during training, or inferior, but often at the expense of low accuracy, especially in complex problem solving tasks. These solutions struggle to achieve constant trade-efferent Fid between the effectiveness and efficiency of logic, highlighting the need for an adaptive approach.
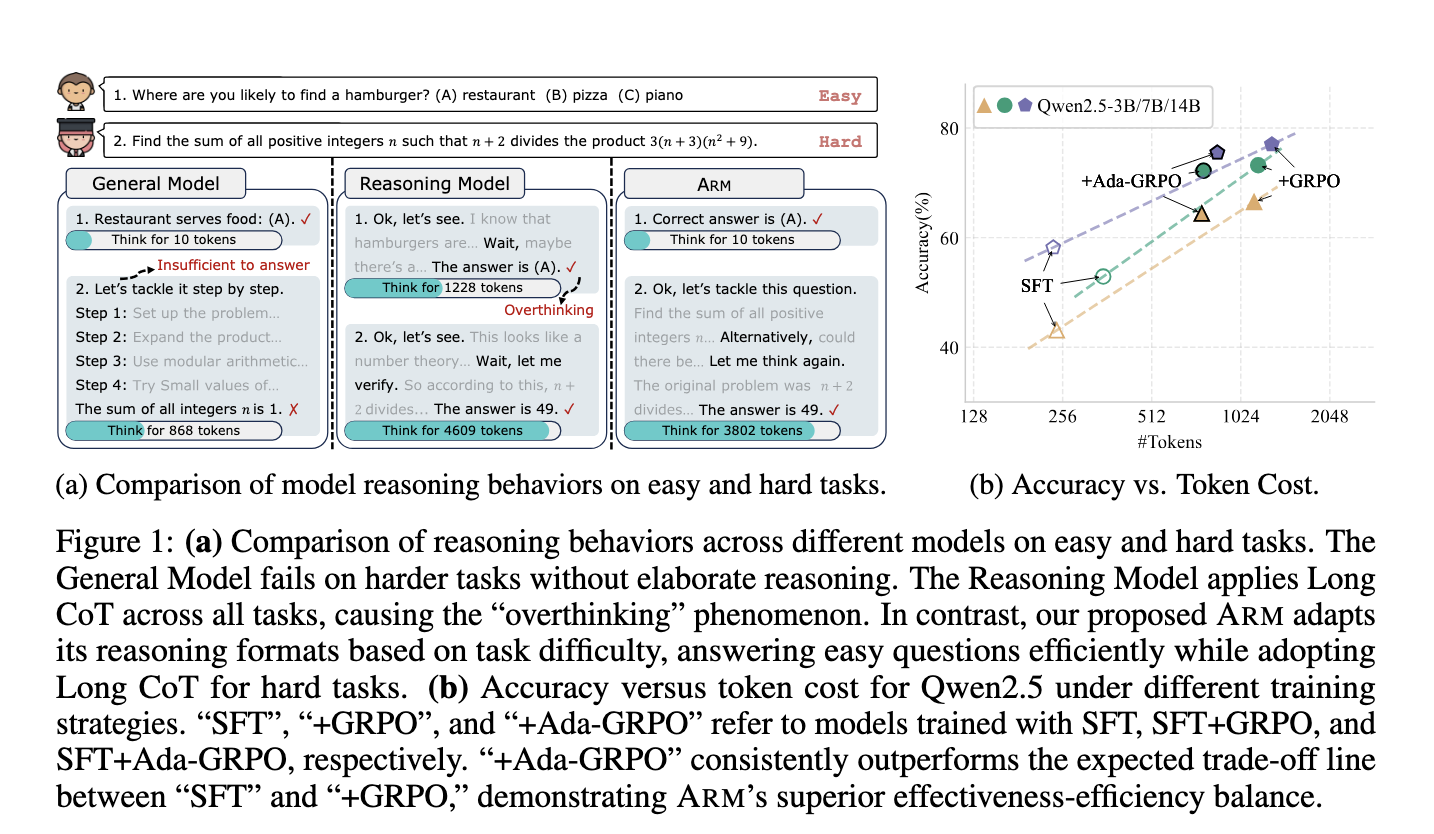
The team of researchers at Fooden University and Ohio State University introduced the adaptive logic model (ARM), which dynamicly adjusted logic formats based on the difficulty of the work. ARM supports four different logic styles: direct answer to simple tasks, short cats for brief logic, code for structured problem-resolving, and a long cat for DEEP Danda multi-step logic. It acts in default adaptive mode, automatically selects the correct format, and also provides instruction-guided and unanimous-guidance modes for clear control or consolidation. The key innovation lies in its training process, which uses ADA-GRPO, expanding GRPOs that introduce the format variation rewarding method. This prevents the dominance of long COT and ensures that ARM continues to explore and use simple logic formats when appropriate.
The ARM method is built on a two-phase structure. First, the model passes through the observed fine-tuning (SFT) with 10.8k questions, notes OT in four logic formats produced with tools like GPT-4O and Dippic-R1, obtained from datasets like Aqua-Rate. This phase teaches the model the structure of each logic format but does not stimulate adaptation. The second phase ADA-GRPO applies, where the model receives scaled rewards to use less frequently formats, such as a straight answer or short cat. A decaying factor ensures that this award gradually returns to accuracy with the progress of training, preventing long -term bias towards inefficient research. To achieve the balance of this structure, efficiency and performance, the task enables the Armen to dynamically match the logic strategy in the task and dynamically match.

The ARM showed impressive results in various benchmarks, including commonsense, mathematical and symbolic logic tasks. It reduces token consumption by an average of 30%, with a reduction of up to 70% for simple tasks, compared to models depending on the long COT. ARM received 2X training speedup on GRPO -based models, accelerating model development without sacrificing accuracy. For example, ARM -7B achieved 75.9% accuracy on challenging AIMI 25 work when using 32.5% less tokens. The ARM -14B achieved 86.6% accuracy on the OpenbookQA, with a decrease in token consumption of more than 30% compared to the QWEN2.5SFT+GRPO models. These numbers show the ability of the arm to maintain competitive operations while providing significant efficiency.
Overall, adaptive logic model work takes into account the constant inability of logic models by enabling the adaptive selection of logic formats based on difficulty. The introduction of ADA-GRPO and multi-format training structure ensures that models no longer ruin excessive resources. Instead, ARM provides a flexible and practical settlement for the cost of balanced accuracy and calculation in the work of logic, making it a promising approach to scalable and efficient large language models.
Check the paper, models on a hug face and project page. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 95K+ ML Subredit And subscribe Our newsletter.
Nikhil is an intern consultant at MarketechPost. He is gaining a dual degree in materials in the technology of the Indian organization in Kharagpur. Nikhil AI/ML is enthusiastic that always researches application in areas such as biometrials and biomedical vigels. With a strong background in the physical expression, he is looking for new progress and chances of contributing.



