

Real-world data is often limited by expensive, messy and privacy rules. Synthetic data provides a solution – and it is already widely used:
- LLMS train on AI-generated text
- Cheating systems imitate edge cases
- Vision models on counterfeit images are pretrain
SDV (Synthetic data on Ault Lt) is an open source Python library that produces actual tabular data using machine learning. It learns patterns from real data and creates high-quality artificial data for safe sharing, testing and model training.
In this tutorial, we will use SDV to produce a step through synthetic data step.
We will install the SDV Library first:
from sdv.io.local import CSVHandler
connector = CSVHandler()
FOLDER_NAME = '.' # If the data is in the same directory
data = connector.read(folder_name=FOLDER_NAME)
salesDf = data('data')
Next, we import the required module and connect to our local folder with dataset files. This reads CSV files from a clear folder and stores them as Panda Dataframes. In this case, we access the main dataset using the access Data (‘data’).
from sdv.metadata import Metadata
metadata = Metadata.load_from_json('metadata.json')Now we import metadata for our dataset. This metadata is stored in the JSON file and tells SDV how to interpret your data. It includes:
- It Table
- It Primary key
- It Base material From each Column Lum (eg, Classified, Statistics, Datatime, etc.)
- Alternative Column formats Like a dattime pattern or ID pattern
- Table Relationship (For multi-table setups)
Here is a sample metadata.Jesson format:
{
"METADATA_SPEC_VERSION": "V1",
"tables": {
"your_table_name": {
"primary_key": "your_primary_key_column",
"columns": {
"your_primary_key_column": { "sdtype": "id", "regex_format": "T(0-9){6}" },
"date_column": { "sdtype": "datetime", "datetime_format": "%d-%m-%Y" },
"category_column": { "sdtype": "categorical" },
"numeric_column": { "sdtype": "numerical" }
},
"column_relationships": ()
}
}
}from sdv.metadata import Metadata
metadata = Metadata.detect_from_dataframes(data)Alternatively, we can use the SDV library to automatically guess the metadata. However, the results may not always be accurate or perfect, so if there is any discrepancy you may need to review and update it.
from sdv.single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(data=salesDf)
synthetic_data = synthesizer.sample(num_rows=10000)
Since metadata and original dataset are ready, we can now use SDV to train the model and create artificial data. The model learns the composition and patterns in your real dataset and it uses Junowledge to create artificial records.
You can control how many rows generate using Num_rows Argument.
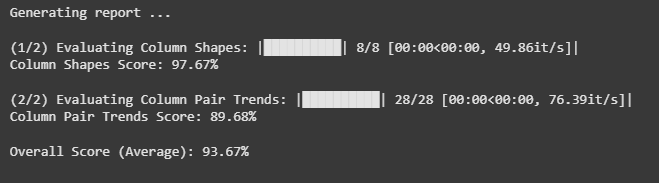
from sdv.evaluation.single_table import evaluate_quality
quality_report = evaluate_quality(
salesDf,
synthetic_data,
metadata)The SDV library also offers tools for evaluating the quality of your artificial data by comparing it to the original dataset. A nice place to start is by producing Quality
You can also imagine how synthetic data compares with real data using SDV’s built-in conspiracy tools. For example, imported get_column_plot Since sdv.evaluation.single_table To make a comparison plot for specific UMNS lum:
from sdv.evaluation.single_table import get_column_plot
fig = get_column_plot(
real_data=salesDf,
synthetic_data=synthetic_data,
column_name="Sales",
metadata=metadata
)
fig.show()
We can observe that the distribution of ‘Sales’ C Column Lum is very similar in real and artificial data. To explore more, we can use metplotlib to create more detailed comparisons – such as imagining average monthly sales trends in both datasets.
import pandas as pd
import matplotlib.pyplot as plt
# Ensure 'Date' columns are datetime
salesDf('Date') = pd.to_datetime(salesDf('Date'), format="%d-%m-%Y")
synthetic_data('Date') = pd.to_datetime(synthetic_data('Date'), format="%d-%m-%Y")
# Extract 'Month' as year-month string
salesDf('Month') = salesDf('Date').dt.to_period('M').astype(str)
synthetic_data('Month') = synthetic_data('Date').dt.to_period('M').astype(str)
# Group by 'Month' and calculate average sales
actual_avg_monthly = salesDf.groupby('Month')('Sales').mean().rename('Actual Average Sales')
synthetic_avg_monthly = synthetic_data.groupby('Month')('Sales').mean().rename('Synthetic Average Sales')
# Merge the two series into a DataFrame
avg_monthly_comparison = pd.concat((actual_avg_monthly, synthetic_avg_monthly), axis=1).fillna(0)
# Plot
plt.figure(figsize=(10, 6))
plt.plot(avg_monthly_comparison.index, avg_monthly_comparison('Actual Average Sales'), label="Actual Average Sales", marker="o")
plt.plot(avg_monthly_comparison.index, avg_monthly_comparison('Synthetic Average Sales'), label="Synthetic Average Sales", marker="o")
plt.title('Average Monthly Sales Comparison: Actual vs Synthetic')
plt.xlabel('Month')
plt.ylabel('Average Sales')
plt.xticks(rotation=45)
plt.grid(True)
plt.legend()
plt.ylim(bottom=0) # y-axis starts at 0
plt.tight_layout()
plt.show()
This chart also shows that the average monthly sales in both datasets are very similar, only with minimal differences.
In this tutorial, we showed how to prepare your data and metadata for artificial data generation using an SDV library. By training the model on your original dataset, SDVs can create high quality artificial data that gives closely mirrors to the patterns and distributions of real data. We also discovered how to evaluate and imagine artificial data, confirming that key matrixs such as sales distributions and monthly trends are compatible. Synthetic data provides a powerful way of eliminating privacy and availability challenges when enabling strong data analysis and machine learning workflow.
Check the notebook on the githb. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 95K+ ML Subredit And subscribe Our newsletter.

I am Jamia Milia Islamia, New Delhi Civil Engineering Graduate (2022) and I am more interested in their application in the data, especially the neural network and in various fields.



