

नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
Google शोधकर्ताओं के नए अध्ययन ने बड़े भाषा मॉडल (LLMS) में संवर्धित पीढ़ी (RAG) सिस्टम को समझने और सुधारने के लिए एक उपन्यास परिप्रेक्ष्य “पर्याप्त संदर्भ” पेश किया है।
यह दृष्टिकोण यह निर्धारित करना संभव बनाता है कि क्या एलएलएम के पास क्वेरी का सटीक उत्तर देने के लिए पर्याप्त जानकारी है, डेवलपर्स के लिए वास्तविक दुनिया के उद्यम अनुप्रयोगों को बनाने के लिए एक महत्वपूर्ण कारक जहां विश्वसनीयता और तथ्यात्मक शुद्धता सर्वोच्च हैं।
चीर की निरंतर चुनौतियां
RAG सिस्टम एक अधिक तथ्यात्मक और सत्यापित AI एप्लिकेशन बनाने के लिए नींव में से एक बन गया है। हालांकि, ये सिस्टम अवांछित लक्षणों को प्रदर्शित कर सकते हैं। वे आत्मविश्वास से गलत उत्तर प्रदान कर सकते हैं जब पुनर्स्थापना प्राप्त साक्ष्य के साथ प्रस्तुत की जाती है, संदर्भ में अप्रासंगिक जानकारी से विचलित हो जाती है, या लंबे पाठ स्निपेट के उत्तर ठीक से विफल होने में विफल होते हैं।
शोधकर्ताओं ने अपने पेपर में कहा है कि “आदर्श परिणाम यह है कि यदि प्रदान किए गए संदर्भ में मॉडल के पैरामीट्रिक jnowledge के साथ संयुक्त होने पर प्रश्न का उत्तर देने के लिए पर्याप्त जानकारी है, तो सही उत्तर का उत्पादन करें। अन्यथा, मॉडल को उत्तर देने और/या अधिक जानकारी के लिए पूछना चाहिए।”
इस आदर्श परिदृश्य को प्राप्त करने के लिए, बिल्डिंग मॉडल डेलो के मॉडल की आवश्यकता है जो यह निर्धारित कर सकता है कि प्रदान किया गया संदर्भ एक प्रश्न का सही जवाब दे सकता है और इसे चयनात्मक का उपयोग कर सकता है। इसे संबोधित करने के पिछले प्रयासों ने जांच की है कि एलएलएम कैसे अलग -अलग डिग्री के साथ व्यवहार करते हैं। हालांकि, Google पेपर का तर्क है कि “LLMS को यह समझ में आता है कि जब किसी क्वेरी का जवाब देने के लिए पर्याप्त जानकारी होती है, तो, हालांकि, पिछला काम इस पर विचार करने में विफल रहता है।”
पर्याप्त संदर्भ
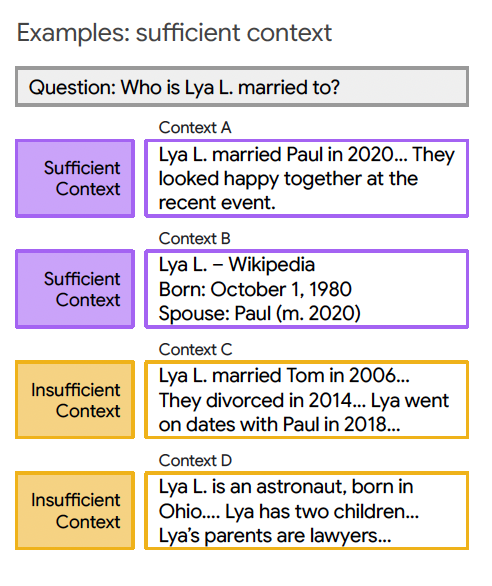
इससे निपटने के लिए, शोधकर्ताओं ने “पर्याप्त संदर्भ” की अवधारणा प्रस्तुत की। उच्च स्तर पर, इनपुट पैटर्न को इस आधार पर वर्गीकृत किया जाता है कि क्या क्वेरी का जवाब देने के लिए पर्याप्त जानकारी है। ये संदर्भ दो मामलों में विभाजित होते हैं:
पर्याप्त संदर्भ: संदर्भ में एक विशिष्ट उत्तर देने के लिए सभी आवश्यक जानकारी है।
अपर्याप्त संदर्भ: संदर्भ में आवश्यक जानकारी की कमी है। ऐसा इसलिए हो सकता है क्योंकि क्वेरी के लिए विशेष जस्ट जुनोलेज की आवश्यकता होती है, जो संदर्भ में मौजूद नहीं है, या जानकारी अपूर्ण, अपूर्ण या विरोधाभासी है।

यह पदनाम एक जमीनी-सत्य उत्तर की आवश्यकता के बिना प्रश्न के प्रश्न और संबंधित संदर्भ द्वारा निर्धारित किया जाता है। यह वास्तविक दुनिया के अनुप्रयोगों के लिए महत्वपूर्ण है, जहां अनुमान के दौरान जमीनी सत्य उत्तर आसानी से उपलब्ध नहीं हैं।
शोधकर्ताओं ने पर्याप्त या अपर्याप्त संदर्भ के पैटर्न के लेबलिंग को प्रमाणित करने के लिए एक एलएलएम -आधारित “अयस्क टोर्टर” विकसित किया। उन्होंने पाया कि Google का मिथुन 1.5 प्रो मॉडल, एक एकल उदाहरण (1-शॉट टी) के साथ, उच्च एफ 1 स्कोर और सटीकता को प्राप्त करते हुए, संदर्भ को पर्याप्त रूप से वर्गीकृत करने में सर्वश्रेष्ठ प्रदर्शन करता है।
पेपर नोट, “वास्तविक दुनिया के विचारों में, हम मॉडल के प्रभाव का मूल्यांकन करते समय उम्मीदवार के उत्तरों की उम्मीद नहीं कर सकते हैं। इसलिए, केवल क्वेरी और संदर्भ का उपयोग करके एक कार्य पद्धति का उपयोग करना वांछनीय है।”
चीर के साथ एलएलएम व्यवहार पर मुख्य निष्कर्ष
पर्याप्त संदर्भ के इन लेंसों के माध्यम से विभिन्न मॉडलों और डेटासेट का विश्लेषण करने से कई महत्वपूर्ण अंतर्दृष्टि का पता चला।
जैसा कि अपेक्षित था, मॉडल आमतौर पर उच्च सटीकता प्राप्त करते हैं जब संदर्भ पर्याप्त होता है। हालांकि, यहां तक कि पर्याप्त संदर्भ में, मॉडल ने भ्रम की तुलना में अधिक बार भ्रम की तुलना में। जब संदर्भ अपर्याप्त होता है, तो स्थिति अधिक जटिल हो जाती है, जिसमें मॉडल दोनों उपेक्षा की दरों को अनदेखा करते हैं और कुछ मॉडलों के लिए, भ्रम को बढ़ाते हैं।
दिलचस्प बात यह है कि जब एक चीर आमतौर पर समग्र प्रदर्शन में सुधार करता है, तो अतिरिक्त संदर्भ में पर्याप्त जानकारी नहीं होने पर जवाब देने से बचने के लिए मॉडल की क्षमता भी कम हो सकती है। शोधकर्ताओं का सुझाव है कि “यह घटना किसी भी संदर्भित जानकारी की उपस्थिति में मॉडल के बढ़ते आत्मविश्वास के साथ उत्पन्न हो सकती है, जिसमें उपेक्षा के बजाय भ्रम के लिए एक प्रसार है।”
विशेष रूप से अजीब मॉडल की क्षमता थी कि जब संदर्भ को अपर्याप्त माना जाता था तब भी सही उत्तर प्रदान करने के लिए। जबकि प्राकृतिक धारणा यह है कि मॉडल “जानते हैं” उनके प्री -ट्राइविंग (पैरामीट्रिक जीई ज्ञान “का उत्तर, शोधकर्ता अन्य योगदानकर्ताओं को ढूंढते हैं। उदाहरण के लिए, एक क्वेरी या ब्रिज गैप संदर्भ मॉडल के जुनेवेलेज में बर्खास्तगी में मदद कर सकता है, भले ही इसका पूर्ण उत्तर न हो। कभी -कभी सीमित बाहरी जानकारी के साथ, राग सिस्टम डिज़ाइन के लिए सफल होने की यह क्षमता होती है।

अध्ययन के सह-लेखक और Google विजय, साइरस रशियन के वरिष्ठ अनुसंधान, इस बारे में विस्तार से वर्णन करते हैं, यह कहते हुए कि आधार एलएलएम की गुणवत्ता महत्वपूर्ण है। उन्होंने कहा, “वास्तव में अच्छे एंटरप्राइज राग प्रणाली के लिए, मॉडल को बेंचमार्क पर और बिना रिट्रीवर के मूल्यांकन किया जाना चाहिए।” उन्होंने सुझाव दिया कि पुनर्प्राप्ति खरीद को सत्य के एकमात्र स्रोत के बजाय “इसके जे एनल्टेलज की वृद्धि” के रूप में देखा जाना चाहिए। बेस मॉडल, यह बताता है, “अभी भी भरने की आवश्यकता है, या संदर्भ लिंक (जो पूर्व-संबंधित जूनोवेलेज द्वारा रिपोर्ट किए गए हैं) का उपयोग संदर्भ को ठीक से ठीक करने के लिए किया जाता है। उदाहरण के लिए, संदर्भ से मॉडल की केवल नकल करने के बजाय, प्रश्न को जानने के लिए पर्याप्त जाना जाना चाहिए।”
चीर सिस्टम में भ्रम को कम करना
शोधकर्ताओं ने इसे कम करने के लिए तकनीकों का आविष्कार किया, विशेष रूप से एक चीर सेटिंग की तुलना में, एक चीर के साथ, मॉडल को छोड़ने के बजाय।
उन्होंने एक नया “चयनात्मक वेतन पीढ़ी” ढांचा विकसित किया। यह विधि यह निर्धारित करने के लिए एक छोटे, अलग “हस्तक्षेप मॉडल” का उपयोग करती है कि क्या मुख्य एलएलएम को एक उत्तर उत्पन्न करना चाहिए या बचना चाहिए, सटीकता और कवरेज (उत्तर दिए गए प्रश्नों का प्रतिशत) के बीच एक नियंत्रित व्यापार की पेशकश करना चाहिए।
इस संरचना को किसी भी एलएलएम के साथ जोड़ा जा सकता है, जिसमें मिथुन और जीपीटी के स्वामित्व के मॉडल भी शामिल हैं। अध्ययन में पाया गया है कि इस संरचना में एक अतिरिक्त संकेत के रूप में पर्याप्त संदर्भ का उपयोग करना विभिन्न मॉडलों और डेटासेट में प्रश्नों के उत्तर देने के लिए काफी अधिक सटीकता है। इस पद्धति ने मिथुन, जीपीटी और जेम्मा मॉडल के लिए मॉडल उत्तरों के बीच सही उत्तरों के अंश में सुधार किया है।
व्यापार के परिप्रेक्ष्य में इस 2-10% सुधार को रखने के लिए, रशियन ग्राहक सहायता एआई से एक ठोस उदाहरण देता है। “आप पूछ सकते हैं कि क्या आप एक ग्राहक को छूट दे सकते हैं,” उन्होंने कहा। “कुछ मामलों में, रिफाइन करने योग्य संदर्भ हाल ही में है और विशेष रूप से वर्तमान पदोन्नति का वर्णन करता है, इसलिए मॉडल आत्मविश्वास के साथ प्रतिक्रिया कर सकता है। लेकिन अन्य मामलों में, संदर्भ कुछ महीने पहले छूट का वर्णन करते हुए ‘बासी’ हो सकता है, या शायद कुछ शर्तें और शर्तें हैं।
टीम ने उपेक्षा को बढ़ावा देने के लिए फाइन-ट्यूनिंग मॉडल की भी जांच की। इन उदाहरणों में प्रशिक्षण मॉडल डेल्ट्स शामिल हैं, जहां उत्तर को मूल ग्राउंड-सत्य के बजाय “मुझे नहीं पता” के साथ बदल दिया गया था, विशेष रूप से अपर्याप्त संदर्भ के पैटर्न के लिए। आंतरिक बात यह है कि इस तरह के उदाहरणों पर स्पष्ट प्रशिक्षण करने के बजाय, मॉडल डेल डेल को दूर रखने के लिए आगे बढ़ सकता है।
परिणाम मिश्रित थे: फाइन-ट्यून मॉडल में अक्सर सही उत्तर दर होती है, लेकिन फिर भी अक्सर भ्रामक होता है, अक्सर परित्याग से अधिक होता है। पेपर ने निष्कर्ष निकाला है कि ठीक ट्यूनिंग मदद कर सकती है, “एक विश्वसनीय रणनीति विकसित करने के लिए अधिक काम की आवश्यकता है जो इन उद्देश्यों को संतुलित कर सकती है।”
वास्तविक दुनिया राग प्रणालियों में पर्याप्त संदर्भ का उपयोग करना
एंटरप्राइज़ टीमों के लिए इन अंतर्दृष्टि को अपने स्वयं के आरएजी प्रणालियों में लागू करने के लिए, जैसे कि आंतरिक जे एनल्टेज के ठिकानों या ग्राहक सहायता एआई, रसियन व्यावहारिक दृष्टिकोण को रेखांकित करता है। यह क्वेरी-टम्परड जोड़े के एक डेटासेट को इकट्ठा करने का सुझाव देता है जो उस प्रकार के उदाहरणों का प्रतिनिधित्व करते हैं जो मॉडल उत्पाद में दिखेंगे। अगला, प्रत्येक उदाहरण को पर्याप्त या अपर्याप्त संदर्भ के रूप में लेबल करने के लिए एक एलएलएम-आधारित ओआरए टेटर का उपयोग करें।
“यह पहले से ही पर्याप्त संदर्भ के % का एक अच्छा अनुमान देगा,” दाने ने कहा। “यदि यह 80-90%से कम है, तो वस्तुओं की वसूली के लिए या JNowledge-Base के आधार पर अपग्रेड करने के लिए कई स्थान हैं-एक अच्छी अवलोकन योग्य विशेषता है।”
Rashion टीमों ने तब “पर्याप्त बनाम अपर्याप्त संदर्भ” के उदाहरणों के आधार पर मॉडल के उत्तरों को स्तरीकृत किया। “इन दो अलग -अलग डेटासेट पर मैट्रिक्स की जांच करके, टीमें प्रदर्शन शोर को बेहतर ढंग से समझ सकती हैं।
“उदाहरण के लिए, हमने पाया कि मॉडल को गलत प्रतिक्रिया प्रदान करने की संभावना है (भूमि की सच्चाई के संदर्भ में) जब डेल अपर्याप्त संदर्भ है। यह एक और अवलोकन योग्य विशेषता है,” यह नोट किया जाता है, “यह नोट किया जा सकता है,” पूरे डेटासेट के आंकड़े महत्वपूर्ण लेकिन खराब संचालित क्वेरी के एक छोटे से सेट पर चमक सकते हैं। “
जबकि एलएलएम -आधारित ओआरए टॉरटर उच्च सटीकता दिखाता है, एंटरप्राइज़ टीमों को अतिरिक्त गणना की कीमत पर चकित किया जा सकता है। रशियन ने यह स्पष्ट किया कि ओवरहेड को नैदानिक उद्देश्यों के लिए संचालित किया जा सकता है।
“मैं कहूंगा कि एक छोटे से परीक्षण सेट (500-1000 उदाहरणों का कहना है) पर एक एलएलएम-आधारित ओरा टॉरर को चलाना अपेक्षाकृत सस्ता होना चाहिए, और यह ‘ऑफ़लाइन लौ’ हो सकता है, इसलिए चिंता न करें कि इसमें कितना समय लगता है।” वास्तविक समय के अनुप्रयोगों के लिए, उन्होंने स्वीकार किया, “एक हेरिस्टिक, या कम से कम एक छोटे मॉडल का उपयोग करना बेहतर होगा।” राचियन के अनुसार, महत्वपूर्ण उपाय यह है कि “इंजीनियरों को अपने रिकवरी घटक से समानता के स्कोर से परे कुछ देखना चाहिए। एलएलएम या हर्स्टिक से, अतिरिक्त सिग्नल के कारण नई अंतर्दृष्टि हो सकती है।”



