

Language models Dells (LMS) have great capabilities in reference when they are widely preferred to Internet text corporations, allowing them to be effectively normalized with only a few function examples. However, fine tuning these models for downstream functions represent significant challenges. While fine-tuning requires hundreds of thousands of examples, the resulting generalization patterns show limitations. For example, who is the Fine Tuned Models Dells on statements like “B’s mother is a”? ” Struggles to answer related questions like this? However, LMS can control such opposite relationships in the context. In this regard, education and fine-tuning raise questions about the differences between the patterns of generalization and how these differences should be informed of the adaptation strategy for downstream tasks.
Research to improve LMS adaptability has followed many major approaches. In-Contents Learning Studies have examined patterns of education and generalization through empirical, mechanistic and theoretical analysis. Exit research in the context does how models are not clearly included in the prompts. Data uses LLMS to enhance the performance of Augmentation techniques, limited datasets, in which certain solutions target issues such as hardcode Augmentation, Dedicable Closer Training and Produced Logic Runes. Moreover, artificial data approaches have been developed from initial -hand -designed data to improve generalization in generalization in domains such as linguistics or mathematics that produce data directly from language models.
Researchers at Google Deepmind and Stanford University have created many datasets that separate data from printing to create clean generalization tests. Pritrained models are exhibited in various generalization types by exposing the printed models through controlled information subsets, in-hand and fine-tuning. Their findings show that in-continent learning data shows more flexible generalization than fine-tuning in data-matched accounting settings, though there are some exceptions where fine-tuning can normalize the contrast in the larger JNowledge Structure. In view of this insights, researchers have developed a method that enhances fine-tuning generalization by incorporating in-tuned instructions into fine-tuning data.
Researchers use multiple datasets designed to distinguish the challenges of specific generalization or to enter into the context of extensive education. Depending on the possibility of multiple choices without providing answer preferences in the context of evaluation. The experiments include a fine-tuning gemini 1.5 flash using a batch size of 8 or 16. For in-contact evaluation, researchers combine training documents as a reference to the instruction-tune model, randomly subspling to larger datasets to reduce interference issues. Key innovation is a dataset growth approach using in-content generalization to increase fine-tuning dataset coverage. These include local and global strategies, everyone contains different references and prompts.
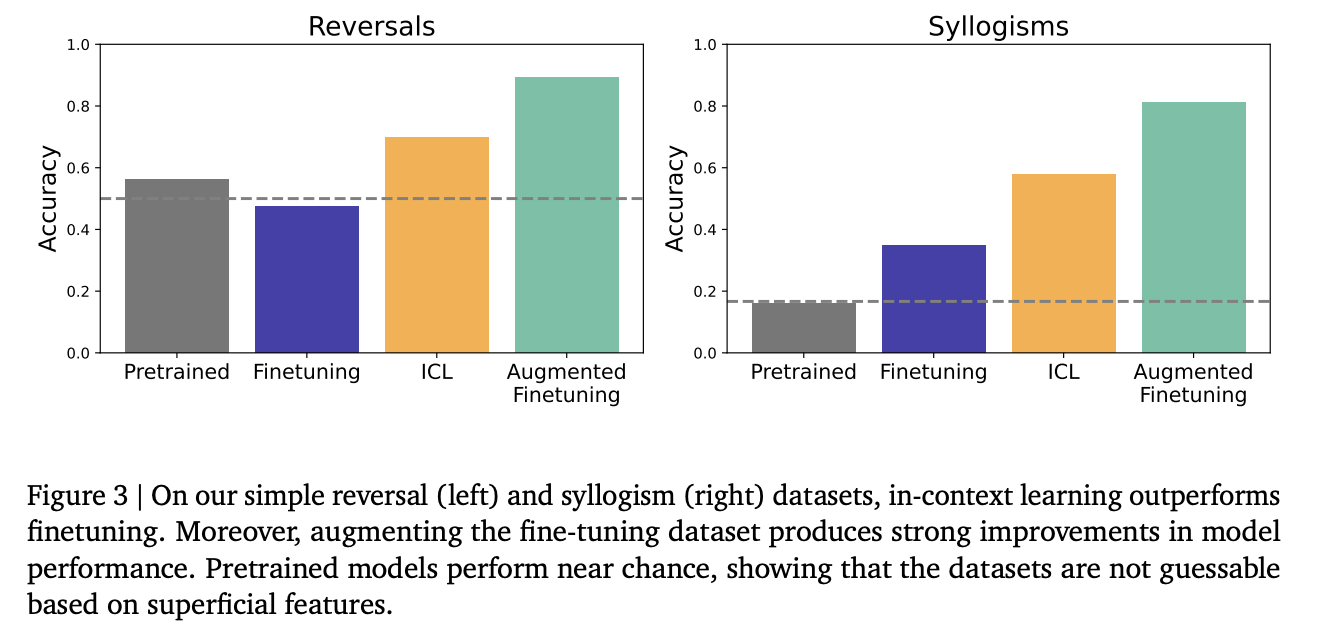
On the opposite curse dataset, in-continent learning reverses ceiling performance, while traditional fine-tuning-zero shows the accuracy because models favor false celebrity names seen during training. Matches the pure influence of fine-tuning-tendon education with data enhanced by in-contact infrasions. Testing on simple nonsense reversals reveals similar patterns, though despite less pronounced benefits. For simple ciloogenesum, when the Pritrain model performs at the opportunity level (indicates data contamination), fine-tuning produces the above opportunity for certain syllaogism types, where logical instructions adjust with simple linguistic patterns. However, in-content learning outperforms fine-tuning, with older fine-tuning shows the best overall results.
In conclusion, when LMS novel faces information compositions, this paper detects the generalization differences between in-content learning and fine tuning. The results show the best generalization of in-content learning for specific forecast types, asking researchers to develop methods that enhance the fine-tuning performance by incorporating in-content instructions into the training data. Despite promising results, many limitations affect the study. The first one is the dependence on nonsense words and messy operations. Second, the research is concentrated on certain LMS, limiting the generalness of the results. Future research should examine the differences of education and generalization in different models to expand these findings, especially new logic models.
Check the paper. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 95K+ ML Subredit And subscribe Our newsletter.

Sajad Ansari is the last year’s undergraduate from IIT Kharagpur. As a technical enthusiast, it considers AI’s practical applications by focusing on the influence of AI techniques and their real-world effects. Its purpose is to clearly and accessible complex AI concepts.
Make n genie you can trust. ⭐ Parlant is your open-sun engine for a controlled, consistent and purposeful AI conversation-Star Parlant on Gittub! (B ED)

