
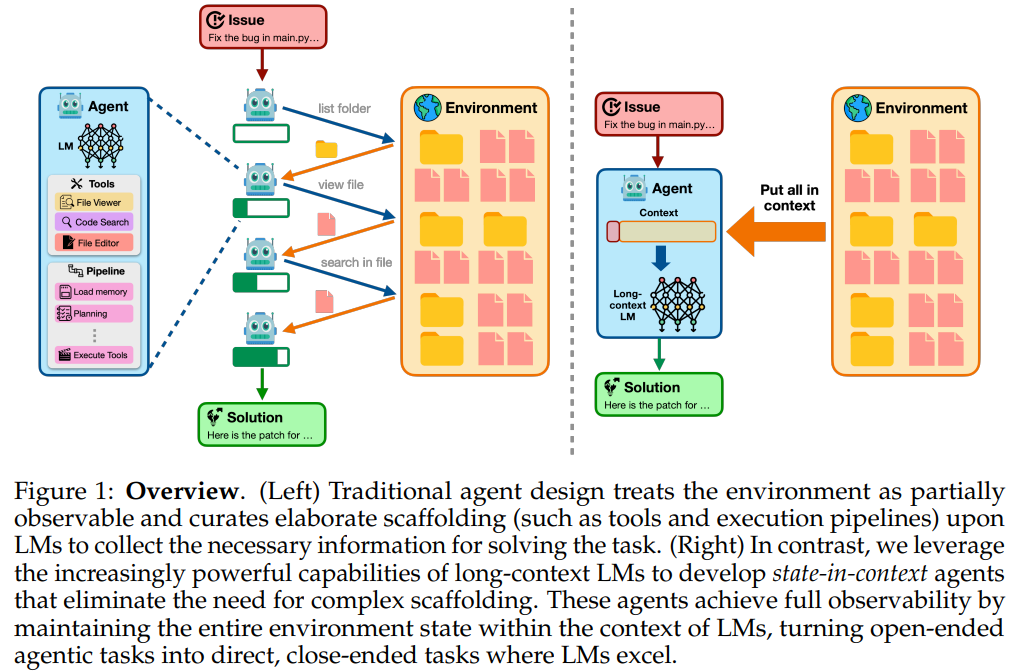

Recent progresses in LM agents have shown a promising possibility of automating complex real-world tasks. These agents usually work through the proposal and execution of actions by API, supporting applications such as Software Fatware Engineering, Robotics and Vijay .Janic experiments. As these tasks become more complex, the LM agent has developed to include multi-step redeems, multi-step redeem and corresponding scoring to ze ptimize the influence. A central challenge is effectively exploring and understanding the environment, which has promoted the development of engineered scurolds using tools, memory mechanisms and custom pipelines. However, most existing methods assume partial observation, requiring agents to increase observations. While this assumption holds in a dynamic or unknown environment, it applies less to full observable settings like Sw-Bench, where all related information is accessible from the beginning.
In Software Forty Engineering, research on LM agents focuses on two main strategies: agent-based framework and structured pipelines. Agent-based systems, such as SWE-agent and openhands codes, allow LMS to be autonomously contacted with codebase, often through custom interfaces and recovery procurement tools. Other models, such as Motless and OC Tucoderover, increase localization through search techniques, while the Specrower improves the scaffolding design. Alternatively, structured pipelines – such as agentsless and codenky – perform tasks in sequential stages such as localization, repair and validity. While these approaches are based on engineered components for influence, the current study proposes to give the benefit of long reference-symmetrical LMS (LCLMS) to interpret the entire function directly to the environment. Progress in LCLM architecture and infrastructure now allows these models to outperform recovery-UG ganted systems in many contexts, reducing dependence on complex external paralysis.
Researchers from Stanford, IBM and the University of Toronto discovered whether LM agents require complex spinach to cope with tasks like SWE-Bench. They show that using only LCLMS, such as Gemini-1.5-Pro, proper prompting and no scaffolding, can achieve competitive display-SWE-bench-wrifted 38% preaching. Gemini -2.5 -Pro, using the same simple setup, reaches 50.8%. Their function suggests that many complex agents can be replaced with a single powerful LCLM, making architecture and training easier. In addition, a hybrid dual -phase approach using Gemini -1.5 -Pro and Cloud -3.7 receives 48.6% solve rate, which supports this simple direction.
Traditional LM agents depend on interactive exploration due to partial observation, but many functions, such as software debugging, allow complete observation. This study proposes state-in-tampered agents that give LCLM the benefit of directly processing the state of the full or narrow environment, bypassing the need for complex agents. For larger codebase, ranking-based compression selects related files to fit within the reference limit. Two methods have been introduced: Direction, where LCLMS solves tasks using a full context; And select, where LCLMS transfer the relevant files for the short reference LMS (SCLMS). Use targeted patch formats and beliefs to ensure both accuracy and reduce delusion.
The experiments evaluate the simple agent framework using LLMS on the SWE-Bench Verified Benchmark, which includes 500 real-world software ftware engineering functions. The proposed methods use and select LCLMS such as Gemini -1.5 -Pro and Gemini -2.5 -Pro, and selects additional SCLMs (Cloud -3.7 -Onn nut) for patch generation. The results show that outperforms complex agents such as agentless and codeect with minimal engineering. Choose improvement in more accuracy by giving the benefit of strong models for patching. Abelication study highlights the importance of COT prompting, code resetting and token-efficient reference design. In addition, the status of the relevant files at the beginning of the prompt improves the operation, underscoring the limits in the long reference-tendon process.
In conclusion, the cost of using LCLM-based methods is currently higher than the existing approaches such as agentless and codicect, which is an average of 60 2.60 per example compared to $ 0.25 and 87 0.87, respectively. However, faster drops in estimate costs and an increase in reference length make LCLMS more practical. KV Techniques like caching cost significantly after the initial run, reducing it to about $ 0.725. Although a little codebase changes still limit caching benefits, more improvements can help. The study also indicates that LCLM can control the history of long interaction, reducing the need for complex memory and recovery methods. Significantly, unskafold LCLM models can perform competitively on SWE-bench tasks.
Check the paper. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 90K+ ML Subredit.
Sana Hassan, a consulting intern at MarktecPost and IIT Madras, is enthusiastic about applying technology and AI to overcome real-world challenges. With more interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.
Make n genie you can trust. ⭐ Parlant is your open-sun engine for a controlled, consistent and purposeful AI conversation-Star Parlant on Gittub! (B ED)


