


В этой серии интервью мы встречаемся с некоторыми участниками докторского консорциума AAAI/Sigai, чтобы узнать больше об их исследованиях. Ананя Джоши недавно закончила свою докторскую степень, где она разработала систему, которую эксперты использовали в течение последних двух лет для выявления дыхательных вспышек (например, Covid-19) в крупномасштабных потоках здравоохранения по всей территории Соединенных Штатов, используя ее новые алгоритмы для ранжирования событий в реальном времени из крупномасштабных данных временных рядов. В этом интервью она рассказывает нам больше об этом проекте, о том, как приложения здравоохранения вдохновляют базовые исследования ИИ и ее планы на будущее.
Не могли бы вы начать с немного о докторской степени? Какова была тема вашего исследования?
Когда я начал свою докторскую степень во время пандемии COVID-19, произошел взрыв в непрерывных данных о здоровье человека. Тем не менее, людям было трудно выяснить, какие данные были важны, чтобы они могли принимать решения, такие как увеличение количества больничных коек в начале вспышки или исправление серьезной проблемы с данными, которые повлияют на прогнозирование заболеваний. Им нужна была система для мониторинга этих реальных больших данных в режиме реального времени, чтобы наиболее важные данные могли быстро действовать.
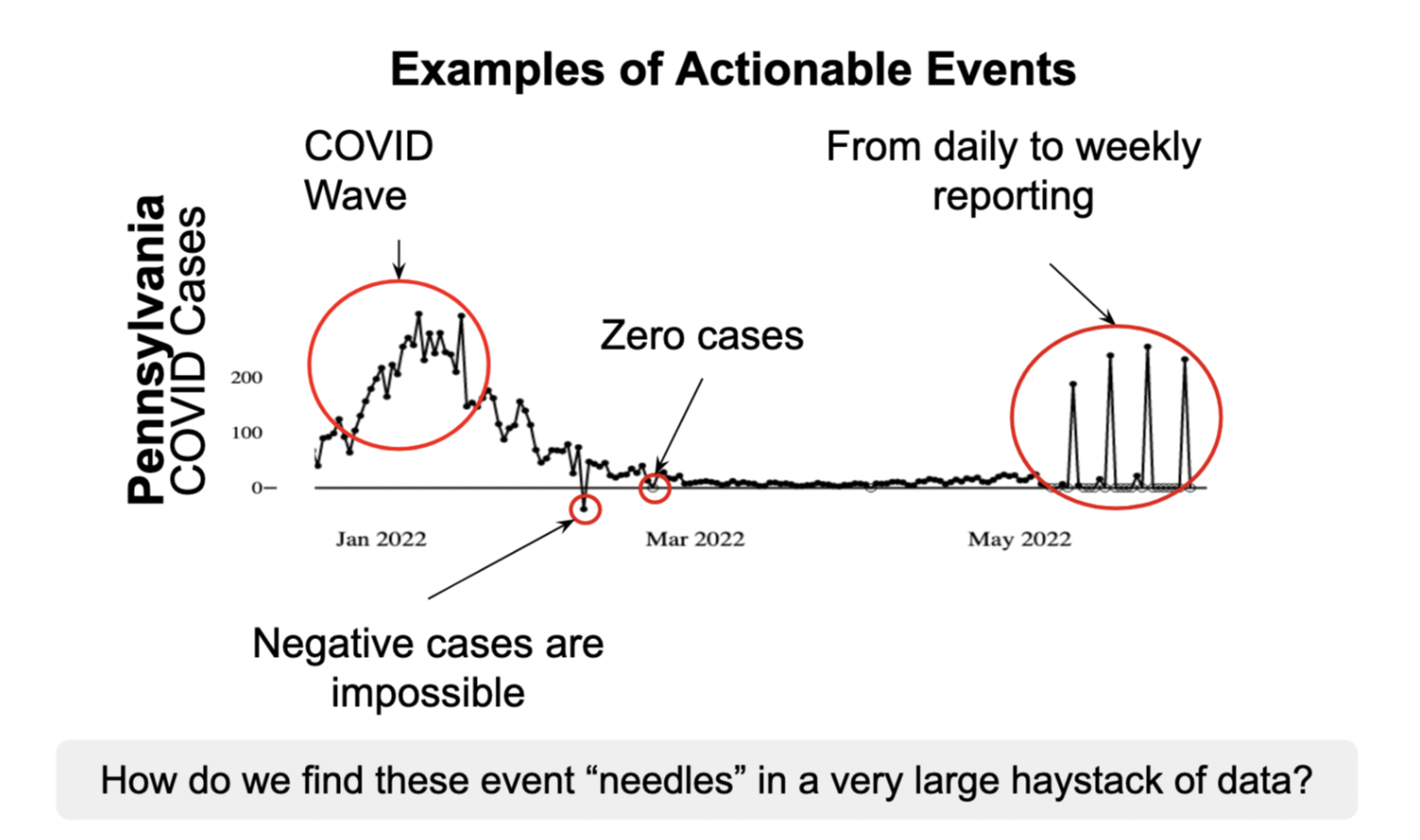
Чтобы построить эту систему, мне сначала нужно было решить теоретический вопрос вычислительного исследования. Когда есть так много данных, есть сотни тысяч потенциально интересно точки данных. Тем не менее, человеческое внимание ограничено, и что более полезно, так это знать: «Как ты Распределите приоритеты аномалии В больших, непрерывно обновленных наборах данных? » После того, как у вас будет этот рейтинг самых неожиданных данных, люди могут соответствующим образом расставить приоритеты в своем внимании – и существуют интересные применения этих методов за пределами области здравоохранения в технологических, сельскохозяйственных и экономических областях.
Эта система была развернута более двух лет назад в Карнеги -Меллон в Delphi Group и с тех пор ежедневно использовалась для сортировки данных общественного здравоохранения в Соединенных Штатах. После принятия этой системы эффективность человека в обнаруженных событиях/мин увеличилась более чем на 52 раза, и сотни сегментов данных идентифицируются как события в неделю по сравнению с двумя до трех исторически.
Вы сказали, что исторические методы были не лучшими для работы с данными общественного здравоохранения и поиска событий данных. Не могли бы вы рассказать об этих исторических методах, а затем о новой методологии, которую вы разработали во время доктора философии?
Многие домены недавно инвестировали в датчики, которые проводят измерения с течением времени, называемые потоками данных. Эти потоки данных могут быть несовершенными; Потоки данных общественного здравоохранения являются шумными, нестационарными и неполными. Когда есть событие (например, вспышка), датчики могут сообщать о значениях, которые отклоняются от того, что ожидается. Исторически, эксперты могли использовать стандартные одномерные инструменты обнаружения выбросов/аномалий по всему каждому из потоков данных, чтобы поверхность этих аномалий.
Хотя есть много методов обнаружения аномалий, большинство из этих четырех шагов:
- Создайте прогноз данных (как вы ожидаете, что данные будут выглядеть?)
- Определите разницу (что значит отклониться от данных?)
- Контекстуализировать разницу (что означает эта разница в контексте данных?)
- Установите порог оповещения (когда это контекстуальное различие достаточно важно, чтобы установить предупреждение?)
Тем не менее, в текущем масштабе эти методы приводят к сотням тысяч оповещений («Что вы действительно можете делать с 35 000 статистических оповещений в неделю в любом случае?»), Которые также имеют статистические проблемы (статистические проблемы, с которыми сталкивается раннее обнаружение вспышек при биосурвейллере). Создание рейтинга аномалий из нескольких потоков данных соответствовало бы тем, что эксперты по общественному здравоохранению необходимы из данных – и это также новая задача машинного обучения, которую мы определили и называли Многосторонний рейтинг выбросовПолем
Практическое решение этой проблемы не только должно быть статистически правильным, но и должно соответствовать ограничениям от экспертов общественного здравоохранения, например, быть легким и интерпретируемым. Это требовало переосмысления четырех этапов обнаружения аномалий.
От автоматизированного до информированного выбора (шаги 1 и 2)
Большинство методов обнаружения выбросов являются вариантами только шагов 1 и 2, тогда как шаги 3 и 4 рассматриваются как параметры (например, на какой порог должен быть направлен предупреждения).
Эта настройка не всегда интуитивно понятна. Эксперты домена знают а) информацию, которая недоступна в каких -либо данных, таких как изменение политики данных и б), имеют такие ограничения, как требования вычислений или интерпретации. Таким образом, используя их понимание при определении ожидания (шаг 1) и метрики различий (шаг 2) вместо того, чтобы вытащить готовый метод означает, что у нас есть базовые компоненты, чтобы найти данные, которые являются Больше всего отличается от их ожиданий – И эти компоненты могут быть изменены в любое время, чтобы соответствовать экспертному руководству.
Контекстуализация в масштабе и ранжировании (шаги 3 и 4)
Хотя процесс определения ожиданий и различий определяется экспертом, нам теперь нужен способ масштабировать и контекстуализировать эту информацию в больших объемах потоков данных, где использованные определенные ожидания могут быть разными точными, скажем, для COVID-19 Case Flys в большом городе, таких как Нью-Йорк, против небольшого округа, такой как любящий округ, штат Техас.
Мои алгоритмы для этой задачи основаны на ветви статистики, называемой теорией экстремальной ценности и адаптированы для реальных условий, которые нарушают многие формальные гарантии на распределение данных. Во-первых, выход с шага 2, называемый тестовой статистикой, нормализуется с течением времени и по потокам. Затем потоки группируются вместе с использованием иерархии аналогичных собранных данных (в нашем случае, то есть геопространственной), и сохраняется максимум каждой группы по историческим данным.
Затем, новая статистика тестов в реальном времени, соответствующая самым последним показанным данным, ранжируются на основе того, насколько они выше, чем исторические значения. Что замечательно в этом подходе, так это то, что он также легко обобщает на аномальные последовательности и эмпирически создает мало связей.
Эти методы изменяют способ, которым контролируемые данные рассматриваются и оцениваются, поэтому мне нужно было а) разработать новую систему для обзора с b) новыми показателями оценки. Именно здесь было здорово быть частью междисциплинарной команды (Нолан Гормли, Рича Гадгил, Каталина Вадзиак, Тина Таунс и мои советники Брайана Уайлдера и Рони Розенфельд), и я многое узнал о том, что нужно (исследования и в остальном), чтобы увидеть новую парадигму.
Сохраняя людей в цикле, я предполагаю, что вы тесно сотрудничали с различными экспертами домена во время доктора философии?
Это верно. Для этой системы наиболее важным человеком является экспертный рецензент данных домена. Они определяют то, что ожидается от данных, чтобы мы могли показать им шаблоны, которые наиболее отклоняются от их ожиданий как событий. Тем не менее, их действия основаны на ограничениях от методологов, инженеров и заинтересованных сторон, таких как эксперты по общественному здравоохранению или представители общественности, поэтому мы склонились к дизайну участия и науке команды, чтобы убедиться, что этот проект успешным.

Итак, как вы вводите советы от эпидемиолога (или другого эксперта по доменам) в цикл? Модель постоянно обновляется на основе их совета?
Исторически, групповые чеки занимают от пяти до десяти минут в неделю, и рецензенты смотрят на список ранжирования ежедневно, а не предупреждениям. Во время этих проверок мы узнаем, нужно ли нам изменить шаги 1 и 2 от рецензента, и в будущем мы проводим окончательную проверку, включающую случайным образом разбрызгивание нескольких точек с более низким ранжированием в список, чтобы у нас был количественный сигнал на разногласий рецензента.
Вы упомянули, что эта система была развернута в течение двух лет. Не могли бы вы немного рассказать об этом развертывании, о том, как они ушли, и о любых уроках, которые вы извлекла?
Развертывание функциональной системы всегда было окончательным тестом для моего исследования. Многие предлагаемые системы мониторинга в исследованиях и для инженеров машинного обучения или статистиков – но поскольку они не обязательно полезны для их пользователей, они отброшены. Работа в качестве рецензента данных во время пандемии и, с которой сталкиваются с десятками тысяч оповещений в день, дало понять, что существующие системы не работали. Это то, как я знал, что на фронте масштабируемости необходим совершенно другой подход, и что его нужно было разработать через междисциплинарную линзу, чтобы соответствовать потребностям пользователей.
Самые важные уроки, которые я извлек, были в компромиссах. Один из первых прототипов включал модель прогнозирования глубокого обучения и дал рецензентам только список индексов для поиска. Оказывается, это было нежелательно для обоих наших Инженерная команда для расчета затрат и доменные эксперты С точки зрения интерпретации, хотя это было немного более точным.
Каковы следующие шаги, когда вы закончили докторскую степень? Вы продолжаете работать в Карнеги -Меллон?
Прямо сейчас доступность данных общественного здравоохранения фактически сокращается и становится менее последовательной. Я кратко остаюсь в качестве постдока, чтобы изучить, насколько хорошо работает система на практике в этих условиях, что довольно интересно.
Затем, в августе, я собираюсь начать в качестве доцента в Johns Hopkins, и я с нетерпением жду исследования основных вычислительных вопросов с клиническими воздействиями.
Что это вдохновило вас на изучение ИИ и, в частности, применение его в здравоохранении?
Я начинал как исследователь компьютерных систем, потому что мне понравилась сложность и задачи разработки и анализа новых алгоритмов. В то же время я хотел, чтобы моя работа была полезна, особенно если ее можно использовать для улучшения здоровья человека. Мне повезло, что я нашел способ объединить свои вычислительные навыки и страсти Через ИИ исследованияПолем Фактически, я узнал о теории крайней ценности в контексте частоты отказов в вычислительных системах, и я понял, что она должна использоваться только в этой ситуации, как только я понял, что у экспертов общественного здравоохранения возникают проблемы, ранжирующие самые большие «неудачи» на основе их данных. И для меня, увидев мои вычислительные исследования, улучшающие результаты на практике, было самой полезной частью моей докторской степени.
Не могли бы вы немного рассказать о опыте докторанта в AAAI 2025?
Докторский консорциум ясно дал понять, что AAAI приоритет поддержке ранних ученых и исследователей. Я был удивлен тем, как много времени и усилий пожилые исследователи обратились к наставникам аспирантов и интересом к каждой из нашей карьерной траекторий. Я также очень ценил возможность встретиться с моими сверстниками и узнать об их исследованиях и оставаться в контакте с ними.
Для тех, кто рассматривает возможность подачи заявления, я думаю, что это прекрасная возможность задать вопросы о будущих путях исследований и направлении исследования ИИ в будущем.
У вас есть какой -нибудь совет, который вы бы дали тому, кто думает о докторской диссертации?
Один из старших исследователей из докторского консорциума сказал нам: «Вы должны защищать свою работу».
Я обнаружил, что это правда. Я продолжаю исследовать проблемы ИИ, которые улучшат здоровье человека, потому что я считаю, что эти проблемы важны для решения. Лучшее руководство, которое я получил о том, как эффективно отстаивать этот тип исследований, – это сбалансировать настойчивость и гибкость, что я пытаюсь сделать в своих исследованиях и карьере.
Наконец, у вас есть интересный факт о вас?
Я начал боевые искусства во время доктора философии. Наличие сложного хобби всегда давало мне что -то для работы!
Об Ананье
 | Ананья Джоши является входящим доцентом в Джонс Хопкинс. В своем докторском исследовании она разработала систему человека в петле и связанные с ними методы, которые ежедневно используются экспертами общественного здравоохранения для выявления и диагностики данных данных из больших объемов потоковых данных. Ее работа была поддержана через NSF GRFP и была признана в рамках программ Rising Stars, 3 -минутного конкурса тезисов CMU, компьютерных наук и общественных здравоохранения, а также награду за обслуживание аспирантов. |
Теги: AAAI, AAAI докторский консорциум, AAAI2025, ACM Sigai

Люси Смит – старший управляющий редактор Aihub.


