

भाषा मॉडल डेलो (एलएमएस) को टोकन के माध्यम से पाठ्य डेटा को समझने की मौलिक चुनौती का सामना करना पड़ता है। वर्तमान अधीनस्थ टोकनियर सेगमेंट का पाठ शब्दावली टोकन में करते हैं जो कि व्हाइट्स के स्थान को नहीं खींच सकते हैं, कृत्रिम बाधा से चिपके रहते हैं जो अंतरिक्ष को एक शब्दार्थ सीमा के रूप में मानता है। यह अभ्यास वास्तविकता को नजरअंदाज करता है, जिसका अर्थ अक्सर व्यक्तिगत शब्दों से अधिक होता है, जैसे कि “स्टैंडअलोन सिमेंटिक इकाइयों के बहुत सारे” बहुत सारे, जिसमें अंग्रेजी बोलने वाले मानसिक रूप से ऐसे वाक्यांशों को हजारों लोगों को संग्रहीत करते हैं। क्रॉस-लेंडिंग, समान अवधारणाओं को भाषा के आधार पर एक या कई शब्दों के रूप में व्यक्त किया जा सकता है। यह उल्लेखनीय है कि कुछ भाषाएं, जैसे कि चीनी और जापानी, एक लौकीस का उपयोग करते हैं, जिससे टोकन को स्पष्ट प्रदर्शन के अध: पतन के बिना कई शब्दों या वाक्यों को फैलाने की अनुमति मिलती है।
पिछले शोध ने पारंपरिक अधीनस्थ टोकन से परे कई दृष्टिकोणों का आविष्कार किया है। कुछ अध्ययनों ने कई दानेदार स्तरों पर प्रसंस्करण पाठ की जांच की या आवृत्ति आधारित एन -ग्राम पहचान द्वारा मल्टी -वर्ड टोकन बनाए। अन्य शोधकर्ताओं ने बहु-टोकन पूर्वानुमान (एमटीपी) का आविष्कार किया है, जो भाषा मॉडल को एक ही कदम में विभिन्न टोकन की भविष्यवाणी करने की अनुमति देते हैं, एक साथ एक से अधिक अधीनस्थों के प्रसंस्करण के मॉडल की क्षमता की पुष्टि करते हैं। हालांकि, इन दृष्टिकोणों को वास्तुशिल्प परिवर्तनों की आवश्यकता होती है और प्रति कदम अनुमानित टोकन की संख्या को ठीक किया जाता है। कुछ शोधकर्ताओं ने टोकनर-मुक्त दृष्टिकोणों का पीछा किया है, पाठ को सीधे बाइट अनुक्रम के रूप में मॉडलिंग किया है। हालांकि, यह लंबाई और गणना आवश्यकताओं को काफी बढ़ाता है, जिससे जटिल वास्तुशिल्प समाधान होते हैं।
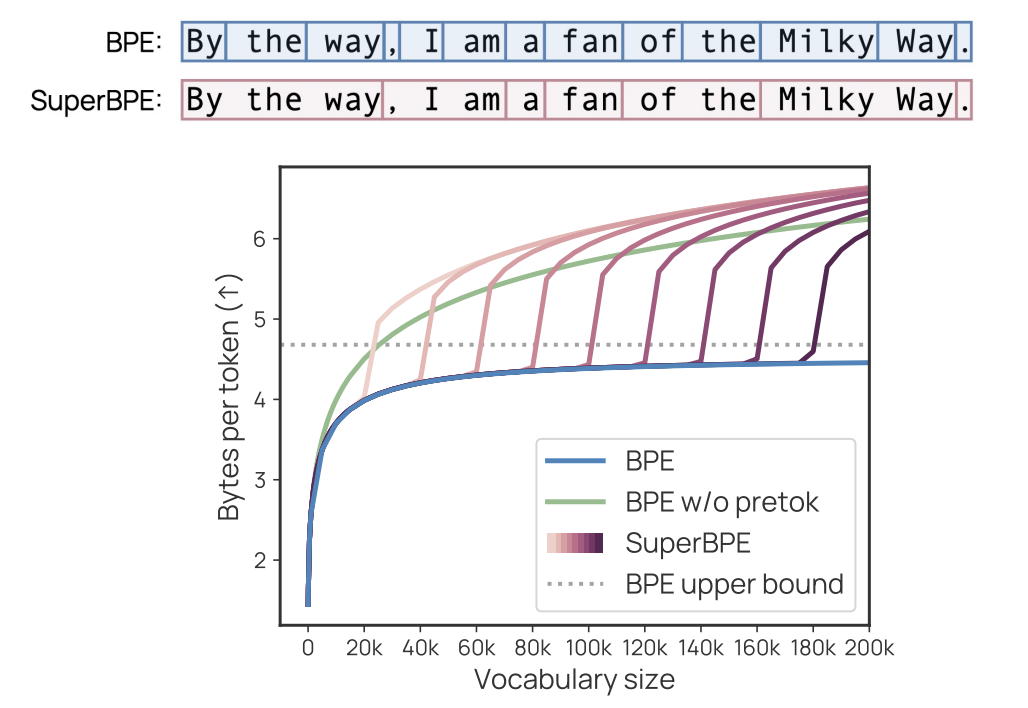
वाशिंगटन शिंगटन, एनवीडिया विश्वविद्यालय के शोधकर्ताओं और एआई के लिए एलन इंस्टीट्यूट ने शानदार ढंग से प्रस्तावित किया है, एक टोकनकरण एल्गोरिथ्म जो एक शब्दावली बनाता है जिसमें पारंपरिक सबवर्ड टोकन और अभिनव “सुपरवर्ड” टोकन दोनों हैं। यह दृष्टिकोण सबवार्ड टोकन सीखने के लिए सुंदर अंतरिक्ष सीमा के निष्पादन द्वारा लोकप्रिय बाइट-पेयर एन्कोडिंग (BPE) एल्गोरिथ्म को बढ़ाता है, फिर सुपरवर्ड टोकन गठन की अनुमति देने के लिए इन बाधाओं को समाप्त करता है। जब मानक BPE तेजी से गिरावट रिटर्न तक पहुंचता है और अधिक से अधिक दुर्लभ उप -शब्द का उपयोग करना शुरू कर देता है क्योंकि शब्दावली का आकार बढ़ता है, तो सुपरबपी एकल टोकन के रूप में एनकोड करने के लिए सामान्य मल्टी -वर्ड अनुक्रमों की तलाश जारी रखता है, एन्कोडिंग कार्यक्षमता में सुधार करता है।
शानदार एक दो-चरण प्रशिक्षण प्रक्रिया के माध्यम से काम करता है जो उपर्युक्त पारंपरिक बीपीई के प्रेटोकलाइज़ेशन चरणों को बदल देता है। यह दृष्टिकोण सहज रूप से शब्दार्थ इकाइयों का निर्माण करता है और उन्हें अधिक दक्षता के लिए सामान्य अनुक्रमों में जोड़ता है। सेट t = t (t संक्रमण बिंदु है और T लक्ष्य आकार है) मानक BPE का उत्पादन करता है, जबकि T = 0 एक भोले सफेद अंतरिक्ष-मुक्त BPE बनाता है। प्रशिक्षण शानदार को मानक बीपीई की तुलना में अधिक गणना किए गए संसाधनों की आवश्यकता होती है, क्योंकि सफेद स्थान के प्रेटोकेशन के बिना, प्रशिक्षण डेटा में न्यूनतम दोहराव के साथ बहुत लंबे “शब्द” होते हैं। हालांकि, इस बढ़े हुए प्रशिक्षण में 100 सीपीयू पर कुछ घंटे की लागत होती है और केवल एक बार होता है, जो भाषा मॉडल प्रिंटिंग के लिए आवश्यक संसाधनों की तुलना में नगण्य है।
शानदार, J Knoweltge औचित्य, तर्क, कोडिंग, पढ़ने की समझ, आदि में 30 बेंचमार्क में प्रभावशाली प्रदर्शन दिखाता है। सभी सुपरबिप मॉडल डेल्स बीपीई बेसलाइन को आगे बढ़ाते हुए, सबसे मजबूत 8B मॉडल औसतन 4.0% प्राप्त करता है और आधार रेखा को 30 में से 25 व्यक्तिगत कार्यों के पीछे छोड़ देता है। बहु-पसंद काम महत्वपूर्ण लाभ दिखाते हैं, +9.7% सुधार के साथ। केवल सांख्यिकीय रूप से महत्वपूर्ण अंडरपरफॉर्मेंस मेमने फ़ंक्शन में किया जाता है, जहां अंतिम सटीकता का अनुभव 75.8% से 70.6% है। इसके अलावा, सभी उचित संक्रमण बिंदु बेसलाइन की तुलना में एक मजबूत परिणाम देते हैं। सबसे अधिक एन्कोडिंग-कुशल संक्रमण बिंदु +1.5% प्रदर्शन में सुधार प्रदान करता है जबकि अनुक्रमण 35% कम्प्यूटिंग को कम करता है।
निष्कर्ष में, शोधकर्ताओं ने सुपरबअप को सुपरवर्ड टोकन को समायोजित करने के लिए मानक बीपीई एल्गोरिथ्म को बढ़ाकर विकसित एक अधिक प्रभावी टोकनकरण दृष्टिकोण को सुपरबअप पेश किया। भाषा मॉडल और पाठ के बीच बुनियादी इंटरफ़ेस के रूप में टोकनकरण के बावजूद, टोकनकरण एल्गोरिदम अपेक्षाकृत स्थिर रहे हैं। सबसे अच्छी चुनौती इस स्थिति को चुनौती देती है कि टोकन मल्टी -वर्ड अभिव्यक्तियों को शामिल करने के लिए पारंपरिक अधीनस्थ सीमाओं से आगे बढ़ सकते हैं। सुपरबी टोकनलाइज़र भाषा मॉडल को गणना की लागत को कम करते समय कई डाउनस्ट्रीम कार्यों में सर्वश्रेष्ठ प्रदर्शन प्राप्त करने में सक्षम बनाते हैं। इन लाभों को अंतर्निहित मॉडल आर्किटेक्चर में किसी भी बदलाव की आवश्यकता नहीं होती है, आधुनिक भाषा मॉडल सुपरबअप को विकास पाइपलाइनों में पारंपरिक बीपीई के लिए एक सहज प्रतिस्थापन बना देगा।
जाँच करना कागज और परियोजना पृष्ठ। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 85 k+ ml सबमिटेड।

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।

