


Задачи с роботизированными манипуляциями с длинным хоризоном являются серьезной проблемой для обучения подкреплению, вызванные в основном редкими вознаграждениями, высокомерными пространствами действий и государствами и задачей разработки полезных функций вознаграждения. Обычное обучение подкреплению не подходит для эффективного разведки, поскольку отсутствие обратной связи препятствует оптимальной политике обучения. Эта проблема имеет важную роль в задачах с роботизированным контролем многостадийных рассуждений, где достижение последовательных субголов имеет важное значение для общего успеха. Плохо разработанные структуры вознаграждений могут привести к тому, что агенты застряли в локальных оптимальных или эксплуатационных ярлыках, что приводит к неоптимальным процессам обучения. Кроме того, большинство существующих методов имеют высокую сложность выборки, требующие больших объемов учебных данных для обобщения для различных задач манипуляции. Такие ограничения делают обучение подкреплению невозможным для реальных задач, где эффективность данных и хорошо структурированные сигналы обучения являются ключом к успеху.
Более ранние исследования, которые решали эти проблемы, изучили модели на основе подкрепления, обучение на основе демонстраций и обучение обратному подкреплению. Методы на основе моделей, в том числе TD-MPC2, повышают эффективность выборки за счет использования моделей прогнозирующих миров, но требуют больших объемов разведки для оптимизации политики. Демонстрационные методы, в том числе модем и кодере, смягчают проблемы разведки за счет использования экспертных траекторий, но не имеют хорошего масштабирования до высокоразмерных задач с длинными горы из-за необходимости крупных наборов данных. Методы обучения обратному подкреплению пытаются изучить функции вознаграждения от демонстраций, но не имеют хорошей способности обобщения и вычислительной сложности. Кроме того, большинство подходов в этой области не используют неотъемлемую структуру многоэтапных задач и, следовательно, не используют возможность разложения сложных целей на более пролеченные субговые.
Чтобы преодолеть эти проблемы, исследователи представили демонстрационную аугментированную вознаграждение, политику и мировое обучение (DEMO3), подкрепляющую структуру обучения, которая интегрирует приобретение вознаграждения, оптимизацию политики и принятие решений на основе моделей. Структура вводит три основных инновация: преобразование разреженных показателей сцены в непрерывные структурированные вознаграждения, обеспечивающие более надежную обратную связь; расписание двухфазного обучения, в котором первоначально используется поведенческое клонирование, сопровождаемое интерактивным процессом обучения подкрепления; и интеграция онлайн -обучения мировой модели, позволяющая динамической адаптации штрафных во время обучения. В отличие от текущих подходов, этот метод позволяет получить структурированное вознаграждение в реальном времени посредством специфических для стадий дискриминаторов, оценивающих вероятность прогресса в достижении субголов. В результате, структура фокусируется на достижении целей задач, а не на демонстрационной имитации, значительно повышая эффективность выборки и обобщение по задачам роботизированных манипуляций.
DEMO3 построен из основания подхода TD-MPC2, который изучает мировую модель скрытого пространства для расширения этапов планирования и контроля. Стратегия основана на многочисленных специфических для этапа дискриминаторов, которые каждый учится прогнозировать вероятность успешного перехода на предстоящий этап задачи. Эти дискриминаторы точно настроены с использованием бинарной критерия потери поперечной энтропии и помогают при онлайн-формировании вознаграждения, генерируя более богатые сигналы обучения по сравнению с редкими обычными вознаграждениями. Обучение придерживается систематического двухфазного процесса. Во-первых, на стадии предварительного обучения политика и кодер изучаются с использованием поведенческого клонирования из частичного набора экспертных демонстраций. Во -вторых, агент, занимающийся непрерывными процессами обучения, учится корректировать и совершенствовать политику посредством процесса взаимодействия окружающей среды, в зависимости от полученных плотных вознаграждений. Процесс отжига вводится для повышения эффективности операций за счет постепенной передачи зависимости от поведенческого клонирования к автономному обучению. Эта плавная передача позволяет самостоятельно прогрессирующему передаче поведения от имитации, вызванной демонстрацией, независимо от имитации политики. Этот подход проверяется на шестнадцати сложных задачах манипуляции с роботизированными роботизациями, включающими мета-мир, робосуит и Maniskill3, и реализует существенные достижения в эффективности обучения, а также устойчивость по сравнению с существующими современными альтернативами.

DEMO3 превосходит современные алгоритмы обучения подкреплению, безусловно, принося значительные повышения эффективности выборки, времени обучения и общих показателей успеха выполнения задач. Метод записывает в среднем на 40% повышенную эффективность данных по сравнению с методами конкурирования, при этом на 70% улучшение сообщалось о очень сложных, длинных проблемах. Система всегда сообщает о высоких показателях успеха с лишь пятью демонстрациями, по сравнению с методами конкуренции, которые требуют гораздо больших наборов данных для достижения сопоставимого успеха. Будучи способным обрабатывать многоступенчатые экземпляры разреженных вознаграждений, система превосходит точные задачи роботизированных манипуляций, такие как вставка ПЭГ и укладку куба с улучшенными показателями успеха в рамках ограниченных бюджетов взаимодействия. Вычислительные затраты также сопоставимы, в среднем около 5,19 часов на каждые 100 000 этапов взаимодействия, что делает их более эффективными, чем конкурирующие модели обучения подкреплению, при этом дает превосходные результаты в обучении сложных роботизированных навыках.
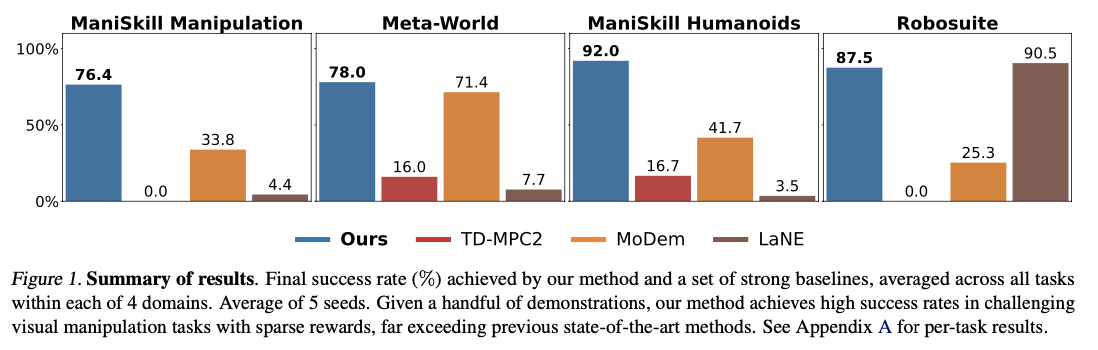
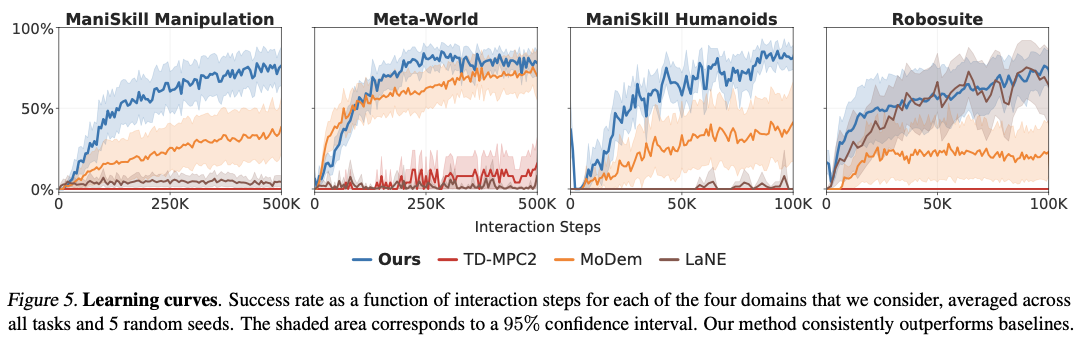
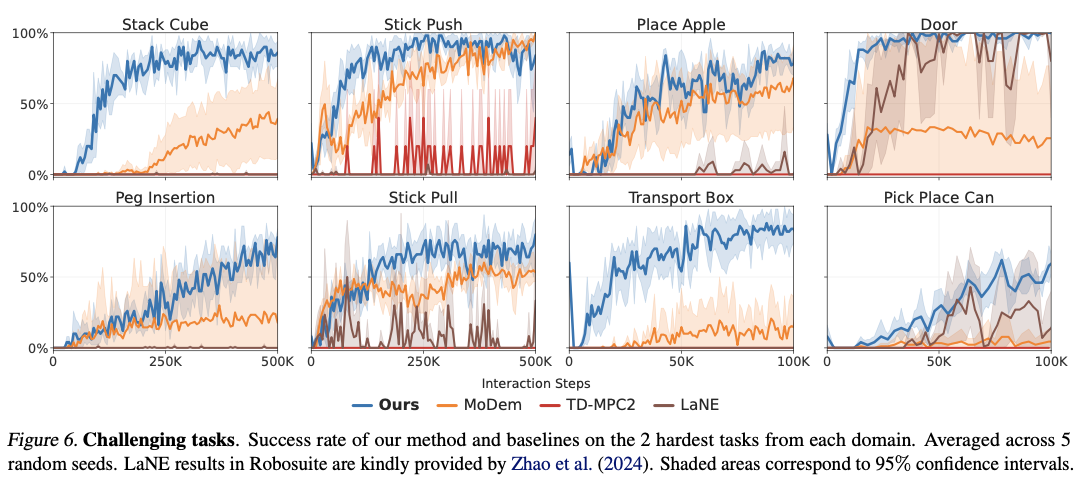
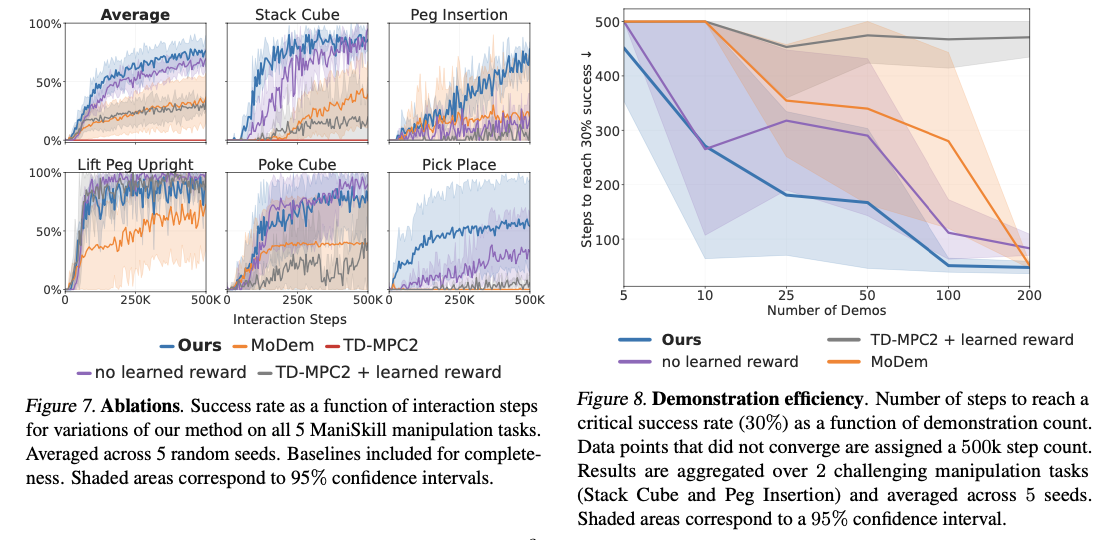
DEMO3 является значительным прогрессом в обучении подкреплению, адаптированным для контроля над роботом, и он эффективен в решении проблем, связанных с решением задач с длинными горе с редкими вознаграждениями. Используя онлайн-обучение плотным вознаграждениям, структурированной оптимизации политики и принятия моделей, эта структура может достичь высокой производительности и эффективности. Включение двухфазной процедуры обучения и динамической адаптации вознаграждения помогает получить впечатляющие повышения эффективности данных, причем показатели успеха на 40-70% выше по сравнению с существующими методологиями по различным задачам манипуляции. С улучшением формирования вознаграждения, оптимизации политического обучения и снижением зависимости от больших демонстрационных наборов данных, этот метод обеспечивает основу для более эффективных и масштабируемых методов роботизированного обучения. Будущие исследования могут быть направлены на более продвинутые подходы к демонстрации и методы адаптивного вознаграждения для дальнейшего повышения эффективности данных и ускорения обучения подкреплению в реальных роботизированных задачах.
Проверить бумага и страница GitHub. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Познакомьтесь с «Партаном»: разговорная структура ИИ, на первом месте LLM, предназначенную для того, чтобы предоставить разработчикам контроль и точность, которые им нужны, по сравнению с их агентами по обслуживанию клиентов AI, используя поведенческие руководящие принципы и надзор за время выполнения. 🔧 🎛 Он работает с использованием простого в использовании CLI 📟 и нативных SDK клиента в Python и TypeScript 📦.
Aswin AK является стажером консалтинга в MarkTechPost. Он получает двойную степень в Индийском технологическом институте, Харагпур. Он увлечен наукой данных и машинным обучением, обеспечивая сильный академический опыт и практический опыт решения реальных междоменных задач.
Парган: строите надежные агенты, обращенные к клиенту AI с LLMS 💬 ✅ (повышен)

