

नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
उद्यम अधिक उन्नत सेवाओं को वितरित करने के लिए बड़े भाषा मॉडल डेल्स (एलएलएम) के बड़े मॉडल पर निर्भर करता है, लेकिन चलती मॉडल की गणना लागत को संभालने के लिए संघर्ष करता है। एक नई संरचना, चेन-एफ-विशेषज्ञों (सीओई), का उद्देश्य तर्क कार्यों पर उनकी सटीकता को बढ़ाते हुए एलएलएम को अधिक संसाधन-कुशल बनाना है।
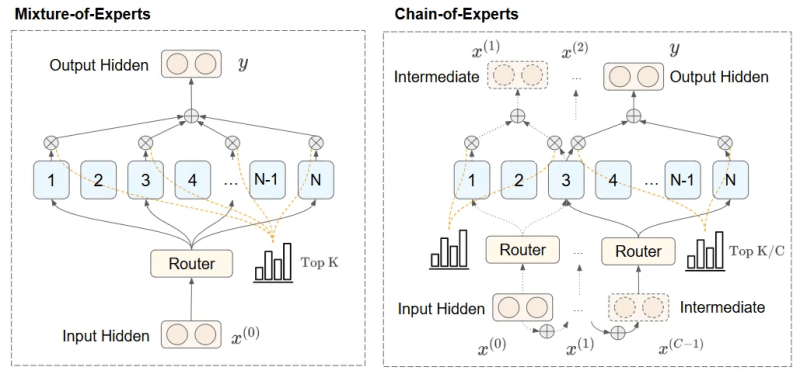
सीओई फ्रेमवर्क “विशेषज्ञों” को सक्रिय करके पिछले दृष्टिकोणों की सीमाओं पर विचार करता है – मॉडल के विभिन्न तत्व, प्रत्येक विशेष फ़ंक्शन में विशेषज्ञता – समानांतर के बजाय। यह संरचना विशेषज्ञों को मध्यवर्ती परिणामों को संप्रेषित करने और धीरे -धीरे एक -दूसरे के काम पर निर्माण करने की अनुमति देती है।
कोए इस तरह के आर्किटेक्ट अनुमानित-गहन अनुप्रयोगों में बहुत उपयोगी हो सकते हैं, जहां कार्यक्षमता में लाभ बड़ी लागत बचत और बेहतर उपयोगकर्ता अनुभव को जन्म दे सकता है।
Ga ense llms और मिश्रण का मिश्रण
क्लासिक एलएलएम, जिसे कभी -कभी जीए एनएसई मॉडल के रूप में जाना जाता है, इंडेक्स के दौरान एक साथ प्रत्येक पैरामीटर को सक्रिय करता है, जिससे मॉडल बड़े होने के साथ व्यापक गणना के लिए अग्रणी होता है। मिक्स-एफ-एक्सपेर्ट्स (एमओई), डीप्सिक-वी 3 और (मान लिया गया) जैसे मॉडलों में उपयोग की जाने वाली आर्किटेक्चर इस चुनौती को विशेषज्ञों के एक सेट में विभाजित करके इस चुनौती को संबोधित करता है।
पूर्वानुमान के दौरान, एमओई मॉडल एक राउटर का उपयोग करते हैं जो प्रत्येक इनपुट के लिए विशेषज्ञों का एक सबसेट चुनता है। MOES GA ENSE मॉडल की तुलना में LLMS गणना के ओवरहेड को काफी कम कर देता है। उदाहरण के लिए, डीपकिक-वी 3 ए 257 विशेषज्ञों के साथ 671 बिलियन-पैरामीटर मॉडल है, जिनमें से नौ का उपयोग किसी भी इनपुट टोकन के लिए किया जाता है, जो अनुमान के दौरान कुल 37 बिलियन सक्रिय पैरामीटर है।
लेकिन मोजा की सीमाएं हैं। दो मुख्य कमियां, सबसे पहले, कि प्रत्येक विशेषज्ञ दूसरों के स्वतंत्र रूप से संचालित होता है, जो उन कार्यों पर मॉडल के कामकाज को कम करता है जिन्हें विशेषज्ञ के संदर्भ की आवश्यकता होती है। और दूसरा, एमओई आर्किटेक्चर उच्च विरलता का कारण बनता है, जिसके परिणामस्वरूप उच्च मेमोरी आवश्यकताओं के साथ एक मॉडल का परिणाम होता है, हालांकि किसी भी समय छोटे सबसेट का उपयोग किया जाता है।
संसद
चेन-एफ-विशेषज्ञों की रूपरेखा समानांतर के बजाय क्रमशः विशेषज्ञों को सक्रिय करके एमओई की सीमा को संबोधित करती है। यह संरचना विशेषज्ञों को मध्यवर्ती परिणामों को संप्रेषित करने और धीरे -धीरे एक -दूसरे के काम पर निर्माण करने की अनुमति देती है।
COE एक दोहराव प्रक्रिया का उपयोग करता है। इनपुट को पहले विशेषज्ञों के एक सेट में निहित किया गया है, जो इसे संसाधित करते हैं और विशेषज्ञों के दूसरे सेट को उनके उत्तर पर पास करते हैं। विशेषज्ञों का एक अन्य समूह मध्यवर्ती परिणामों को संसाधित करता है और उन्हें विशेषज्ञों के अगले सेट पर दे सकता है। यह क्रमिक दृष्टिकोण संदर्भ-जागरूक इनपुट प्रदान करता है, जिससे जटिल तर्क कार्यों को संभालने की क्षमता काफी बढ़ जाती है।

उदाहरण के लिए, गणितीय तर्क या तार्किक अनुमान में, सीओई प्रत्येक विशेषज्ञ को पिछली अंतर्दृष्टि, सटीकता और कार्य प्रदर्शन में सुधार करने की अनुमति देता है। यह विधि लागत-कुशल और उच्च प्रदर्शन करने वाले एआई समाधानों के लिए उद्यम की मांग को संबोधित करके संसाधनों के उपयोग से भी निकलती है, समानांतर-केवल विशेषज्ञ तैनाती में सामान्य निरर्थक गणना को कम करती है।
कोए
क्रमिक सक्रियण और विशेषज्ञ सहयोग का उपयोग करके चेन-एफ-विशेषज्ञों के दृष्टिकोण, सी.ओ. जैसा कि फ्रेमवर्क परीक्षण शोधकर्ताओं के हालिया विश्लेषण में वर्णित है, कई प्रमुख लाभ परिणाम हैं।
COE में, विशेषज्ञ को दोहरावदार फैशन में चुना जाता है। प्रत्येक पुनरावृत्ति में, विशेषज्ञों को पिछले चरण आउटपुट द्वारा निर्धारित किया जाता है। यह विभिन्न विशेषज्ञों को संवाद करने और अधिक जीवंत रूटिंग तंत्र बनाने के लिए पारस्परिक निर्भरता बनाने में सक्षम बनाता है।
शोधकर्ता लिखते हैं, “इस प्रकार, कम्प्यूटेशनल दक्षता बनाए रखना, विशेष रूप से जटिल विचारों में (जैसे, प्रयोगों में गणित कार्य), कम्प्यूटेशनल दक्षता बनाए रखते हुए सीओई मॉडल प्रदर्शन में काफी सुधार कर सकते हैं।”

शोधकर्ताओं के प्रयोगों से पता चलता है कि इसी तरह की गणना और मेमोरी बजट के साथ, कोए जीए ने एलएलएम और एमओई को आउटपरफॉर्म किया। उदाहरण के लिए, गणितीय बेंचमार्क में, 64 विशेषज्ञों के साथ 64 विशेषज्ञों, चार मार्ग विशेषज्ञों और दो अनुमानों के साथ सीओई 64 विशेषज्ञों और आठ मार्ग विशेषज्ञों (एमओई (8/64)) के साथ दोहराता है (सीओई -2 (4/64))।
शोधकर्ताओं ने यह भी पाया कि सीओई स्मृति आवश्यकताओं को कम करता है। उदाहरण के लिए, 48 रूट विशेषज्ञों और सीओई के साथ दो पुनरावृत्तियों (COE -2 (4/48)) के साथ, COE लाभ Moe (8/64) जैसे प्रदर्शन, जबकि कम कुल विशेषज्ञों का उपयोग करते हुए, मेमोरी आवश्यकताओं को 17.6%तक कम करते हैं।
सीओई भी अधिक कुशल मॉडल आर्किटेक्चर की अनुमति देता है। उदाहरण के लिए, तंत्रिका नेटवर्क की चार परतों के साथ COE -2 (8/64) MOE (8/64) के संचालन से आठ स्तरों के साथ मेल खाता है, लेकिन 42% कम मेमोरी का उपयोग करता है।
शोधकर्ता लिखते हैं, “शायद सबसे महत्वपूर्ण, सीओई प्रदान करता है कि हम ‘फ्री लंच’ त्वरण कहते हैं।”
मामले में: एक सीओई -2 (4/64) एमओई (8/64) की तुलना में 823 अधिक विशेषज्ञ यौगिक प्रदान करता है, मॉडल को मॉडल या मेमोरी और गणना आवश्यकताओं के आकार को बढ़ाए बिना अधिक जटिल कार्यों को जानने में सक्षम बनाता है।
उन्नत एआई रोमांच के लिए अधिक सुलभ हो सकता है, सीओई की कम परिचालन लागतों से साहसी बुनियादी ढांचा निवेश और जटिल कार्यों पर बेहतर प्रदर्शन के बिना प्रतिस्पर्धी बने रहने में मदद कर सकता है।
शोधकर्ताओं ने लिखा, “यह शोध प्रभावी रूप से स्केलिंग भाषा के मॉडल के लिए नए तरीके खोलता है, जिससे संभावित रूप से उन्नत कृत्रिम बुद्धिमत्ता क्षमताएं अधिक सुलभ और टिकाऊ होती हैं,” शोधकर्ता लिखते हैं।



