
बड़े भाषा मॉडल डेल्स (एलएलएम) ने प्रशिक्षण के बाद के चरण में महत्वपूर्ण कदम बनाए हैं, जिसमें डीपस्क-आर 1, किमी-के 1 और ओपनईएआई-ओ 1 जैसी प्रभावशाली तर्क क्षमताओं का चित्रण किया गया है। जबकि दीप्सिक-आर 1 ओपन-सीरस मॉडल वजन प्रदान करता है, यह प्रशिक्षण कोड और डेटासेट विवरण को रोकता है, जिससे लॉजिक क्षमताओं, सर्वोत्तम प्रशिक्षण डेटा संरचनाओं और छोटे मॉडलों में विश्वसनीय प्रतिकृति विधियों को स्केल करने के बारे में सवाल उठाते हैं। पारंपरिक गणित डेटासेट जैसे कि GSM8K और OMINI-METH विभिन्न तार्किक THS टॉन्सिल के साथ असंगत कठिनाई का स्तर प्रस्तुत करता है, नियंत्रित प्रयोगों को जटिल करता है। नियंत्रणीय जटिलताओं के साथ लक्षित डेटासेट की आवश्यकता एलएलएम में तर्क क्षमता के उद्भव को अलग करने और अध्ययन करने के लिए महत्वपूर्ण हो गई है।
एलएलएम की तर्क क्षमताओं को विभिन्न तकनीकों द्वारा स्थानांतरित किया गया है, चेन-थिंकिंग (सीओटी) तर्क ने जटिल समस्याओं को तोड़ने में महत्वपूर्ण भूमिका निभाई है। मोंटे कार्लो ट्री सर्च (MCTS) ने शुरू में अल्फ़ागो में सफल, ट्री-आधारित खोज और यादृच्छिक नमूनों द्वारा अनुसंधान और अवशोषण को समायोजित करके मॉडल-आधारित योजना का मार्गदर्शन करने के लिए अनुकूलित किया है। इसके अलावा, तर्क क्षमता बढ़ाने के लिए प्रशिक्षण के बाद की रणनीति में विशेष डेटासेट पर अतिरिक्त फाइन-ट्यूनिंग या सुदृढीकरण सीखने (आरएल) शामिल हैं। प्रत्यक्ष वरीयता ऑप्टिमाइज़ेशन (DPO), प्रॉक्सिमल पॉलिसी ऑप्टिमाइज़ेशन (PPO), ग्रुप रिलेटिव पॉलिसी प्रॉमिस मेथड्स विथ ऑप्टिमेंट Ptimization (GRPO), और REINFORCE ++ के साथ, मॉडल लॉजिक को मॉडल लॉजिक बनाता है।
Micros .FT रिसर्च एशिया के शोधकर्ताओं, सर्वव्यापी और स्वतंत्र शोधकर्ताओं ने लॉजिक-आरएल, नियम-आधारित आरएल फ्रेमवर्क का संकेत दिया है जो तर्क पहेलियों पर प्रशिक्षण के माध्यम से DEEPSK-R1 जैसे लॉजिक पैटर्न प्राप्त करता है। यह प्रशिक्षण के बाद Dippacic-R1 से Reinforce ++ एल्गोरिथ्म और पुरस्कार डिजाइन को अपनाता है। जैसे -जैसे प्रशिक्षण आगे बढ़ता है, मॉडल स्वाभाविक रूप से तर्क के लिए अधिक गिनती चरणों को आवंटित करता है, सैकड़ों से हजारों टोकन तक फैली हुई है, जो ईआर -डांडा अनुसंधान और विचार प्रक्रियाओं के शुद्धिकरण को सक्षम करती है। केवल 5K उत्पन्न लॉजिक पहेली का उपयोग करते हुए, उनके 7B मॉडल क्रॉस-डॉमन सामान्यीकरण को दर्शाता है, AEMs पर 125% और बेस मॉडल के खिलाफ AMC पर 38% में सुधार करता है। इससे पता चलता है कि आरएल-प्रशिक्षित तर्क डोमेन-विशिष्ट मिलान के बजाय एक अमूर्त समस्या को हल करने का तरीका विकसित करता है।
शोधकर्ताओं को Qwen2.5-Math-7B के पायथन कोड ब्लॉक का उत्पादन करने की प्रवृत्ति के साथ चुनौतियों का सामना करना पड़ता है, जो स्वरूपण आवश्यकताओं के साथ परस्पर विरोधी हैं। Qwen2.5-7b-Base और Qwen2.5-7b-Insect दोनों का परीक्षण RL प्रशिक्षण के दौरान लगभग एक ही प्रशिक्षण मैट्रिक्स का खुलासा करता है, जिसमें मान्यता सटीकता, प्रतिक्रिया लंबाई वृद्धि वक्र और इनाम वक्रता शामिल है। कार्यान्वयन तर्क क्षमताओं में एक नाटकीय सुधार दिखाता है, जिसमें केवल 1000 आरएल प्रशिक्षण चरणों के साथ आउटपुट की लंबाई 500 टोकन के प्रारंभिक औसत से लगभग 2000 टोकन तक बढ़ जाती है। यह अधिक जटिल व्यवहारों के उद्भव को सक्षम करता है, जैसे कि वैकल्पिक समाधानों के प्रतिबिंब और अनुसंधान, और ये व्यवहार जटिल कार्यों को संभालने के लिए मॉडल की क्षमता को काफी बढ़ाते हैं और डीईपीएसके-आर 1 में रिपोर्ट किए गए परिणामों के साथ निकटता से गठबंधन करते हैं।
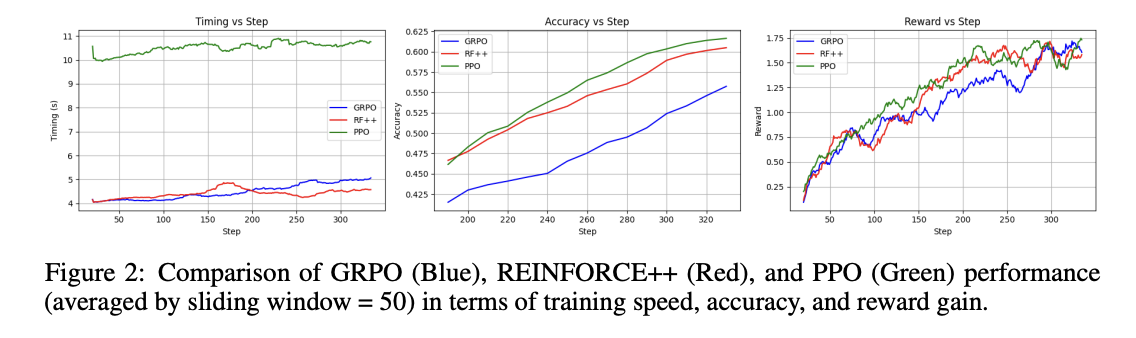
परिणाम बताते हैं कि जब पीपीओ। सटीकता और इनाम में महत्वपूर्ण लाभ प्राप्त करते हुए, यह 138% धीमा था, प्रशिक्षण की गति में ++ को मजबूत करता है। सुदृढीकरण ++ जीआरपीओ की तुलना में सर्वोत्तम स्थिरता, प्रदर्शन लाभ और प्रशिक्षण दक्षता दिखाता है, जिससे यह लगभग सभी मैट्रिक्स तक पहुंचता है। जीआरपीओ मूल्यांकन किए गए तीन आरएल एल्गोरिदम में खराब प्रदर्शन को प्रदर्शित करता है। मॉडल का सुपर ODD (वितरण) सामान्यीकरण क्षमता असाधारण रूप से मजबूत साबित होती है, AIMA डेटासेट पर 125% और AMC डेटासेट पर 38% समग्र सुधार के साथ। यह सिंक्रोनस सुधार इंगित करता है कि आरएल प्रक्रिया वितरण संचालन दोनों को बढ़ाती है और एक मजबूत, स्थानांतरण तर्क रणनीति के उद्भव की सुविधा प्रदान करती है।

यह अध्ययन आरयूएल फ्रेमवर्क के माध्यम से भाषा मॉडल में जटिल तर्क कौशल विकसित करने में लॉजिक-आरएल की एक महत्वपूर्ण संभावना को दर्शाता है। हालांकि, यह स्वीकार करना महत्वपूर्ण है कि निष्कर्ष अपेक्षाकृत छोटे-चित्रित लॉजिक डेटासेट हैं, जो उनके अनुप्रयोगों को सीमित कर सकते हैं। इन परिणामों का सामान्यीकरण बड़े पैमाने पर वास्तविक दुनिया के गणितीय या कोडिंग विचारों में एक खुला प्रश्न है, जिसमें आगे की जांच की आवश्यकता होती है। इस दृष्टिकोण को भविष्य के अनुसंधान के माध्यम से विभिन्न डोमेन और समस्याओं के प्रकारों में इसकी प्रभावशीलता और ताकत को पूरी तरह से मान्य करने के लिए इस दृष्टिकोण को अधिक विविध और जटिल डेटासेट तक विस्तारित करने पर ध्यान केंद्रित करना चाहिए। एक खुले अनुसंधान परियोजना के रूप में इस काम को बनाए रखकर, शोधकर्ताओं का उद्देश्य व्यापक रूप से ऊर्जावान को लाभान्वित करना है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। MEET PALLANT: व्यवहार दिशानिर्देशों और रनटाइम मॉनिटरिंग का उपयोग करके, अपने AI ग्राहक सेवा एजेंटों पर आवश्यक नियंत्रण और सटीकता प्रदान करने के लिए AI फ्रेमवर्क डेवलपर्स को प्रदान करने के लिए एक LLM-FIRST वार्तालाप किया गया है। 🔧 🔧 🎛 इसका उपयोग करना आसान है। और पायथन और टाइपस्क्रिप्ट में मूल ग्राहक एसडीके का उपयोग करके संचालित है।

साजद अंसारी आईआईटी खड़गपुर से अंतिम वर्ष की स्नातक हैं। एक तकनीकी उत्साही के रूप में, यह एआई तकनीकों और उनके वास्तविक दुनिया के प्रभावों के प्रभाव पर ध्यान केंद्रित करके एआई के व्यावहारिक अनुप्रयोगों पर विचार करता है। इसका उद्देश्य स्पष्ट रूप से और सुलभ जटिल एआई अवधारणाओं का है।
पार्लेंट: LLMS (B ED) के साथ एक विश्वसनीय AI ग्राहक का सामना करना