

बड़ी भाषा मॉडल डेलो (एलएलएमएस) उन क्षेत्रों में आवश्यक है जिन्हें समझने और निर्णय लेने के लिए संदर्भ की आवश्यकता होती है। हालांकि, उनका विकास और तैनाती एक महत्वपूर्ण गणना लागत के साथ आता है, जो उनकी स्केलेबिलिटी और एक्सेस सेक्स को सीमित करता है। शोधकर्ताओं के पास तर्क क्षमताओं या सटीकता का त्याग किए बिना दक्षता, विशेष रूप से ठीक-ट्यूनिंग प्रक्रियाओं में सुधार करने के लिए PTIMS इष्टतम है। इसने आयाम-कुशल प्रशिक्षण विधियों का पता लगाया है जो संसाधन की खपत को कम करते हुए संचालन को बनाए रखते हैं।
क्षेत्र में सामना की जाने वाली महत्वपूर्ण चुनौतियों में से एक प्रशिक्षण और ठीक-ट्यूनिंग एलएलएम की अत्यधिक लागत है। इन मॉडलों को विशाल डेटासेट और व्यापक गिनती की शक्ति की आवश्यकता होती है, जिससे वे कई अनुप्रयोगों के लिए अव्यवहारिक हो जाते हैं। इसके अलावा, पारंपरिक फाइन-ट्यूनिंग तरीकों से ओवरफिटिंग होती है और महत्वपूर्ण मेमोरी खपत की आवश्यकता होती है, जिससे वे नए डोमेन के लिए कम स्वीकार्य हो जाते हैं। एक अन्य समस्या एलएलएम की बहु-चरण तार्किक तर्क को प्रभावी ढंग से संभालने में असमर्थता है। जब वे प्रत्यक्ष कार्यों पर अच्छा प्रदर्शन करते हैं, तो वे अक्सर गणित की समस्याओं, जटिल निर्णयों के साथ संघर्ष करते हैं और बहु-टर्न संचार में स्थिरता बनाए रखते हैं। एलएलएम को अधिक व्यावहारिक और स्केलेबल बनाने के लिए, उनकी तर्क क्षमता को बढ़ाते समय गणना चरण को कम करने के तरीकों को विकसित करना आवश्यक है।
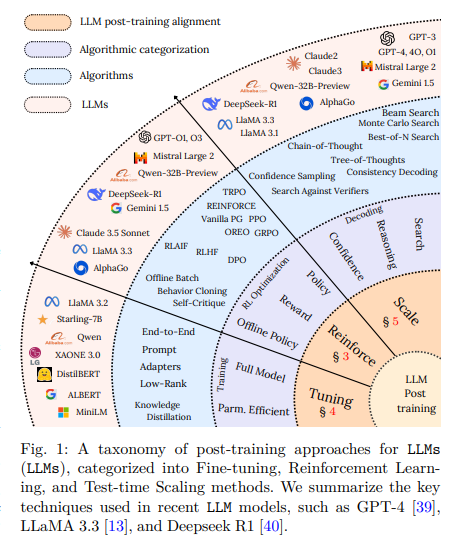
एलएलएम दक्षता में सुधार करने के लिए पिछला दृष्टिकोण निर्देश फिन-ट्यूनिंग, सुदृढीकरण शिक्षा और मॉडल आसवन पर निर्भर करता है। निर्देश ठीक-ट्यूनिंग मॉडल को बेहतर ढंग से समझने और उपयोगकर्ता संकेतों को जवाब देने में सक्षम बनाता है, जबकि सुदृढीकरण शिक्षा निर्णय लेने की प्रक्रियाओं को बेहतर बनाने में मदद करती है। हालांकि, इन विधियों के लिए लेबल किए गए डेटासेट की आवश्यकता होती है जो प्राप्त करने के लिए महंगे हैं। मॉडल डिस्टिलेशन, जो बड़े मॉडलों से Jonoweltge में स्थानांतरित होता है, दूसरा दृष्टिकोण रहा है, लेकिन यह अक्सर तर्क की क्षमता को कम करता है। शोधकर्ताओं ने सक्रिय मापदंडों की संख्या को कम करने के लिए परिमाणीकरण तकनीकों और छंटाई की रणनीतियों के साथ भी प्रयोग किया है, लेकिन इन तरीकों को मॉडल की सटीकता को बनाए रखने में सीमित सफलता मिली है।

एक शोध टीम दीप्सिक ए.आई. एक उपन्यास प्रस्तुत किया आयाम-कुशल फाइन-ट्यूनिंग (PEFT) ढांचा यह बेहतर तर्क और कम गणना लागत के लिए LLMS बनाता है। ढांचा एकीकृत करता है कम-रैंक अनुकूलन (लोरा), मात्राबद्ध लोरा (क्लोरा), संरचित छंटाईऔर उपन्यास परीक्षण-समय स्केलिंग विधियाँ अनुमान दक्षता में सुधार करने के लिए। पूर्ण मॉडल, लोरा और क्लोरा को प्रशिक्षित करने के बजाय कुछ स्तरों में ट्रेन करने योग्य कम-रैंक मैट्रिकिस का इंजेक्शनप्रदर्शन को संरक्षित करते समय सक्रिय मापदंडों की संख्या कम करें। संरचित pruning अधिक से अनावश्यक गणना को समाप्त करता है निरर्थक मॉडल वजन हटाने। इसके अलावा, शोधकर्ताओं में शामिल हैं परीक्षण-समय-स्केलिंग तकनीकशामिल बीम खोज, सर्वश्रेष्ठ-एफ-एन नमूने और मोंटे कार्लो ट्री सर्च (MCTs), पुन: प्रशिक्षण के बिना बहु-चरण तर्क बढ़ाने के लिए। यह दृष्टिकोण यह सुनिश्चित करता है कि LLMS गतिशील रूप से जटिलता के आधार पर गणना की शक्ति को आवंटित करता है, जिससे वे काफी अधिक कुशल हो जाते हैं।
प्रस्तावित विधि को एकीकृत करके एलएलएम तर्क में सुधार करता है ट्री-टू-थॉट (टोट) और आत्म-शिकायतें डिकोडिंग। यह टोट एप्रोच स्ट्रक्चर्स ट्री जैसे प्रारूपों में तार्किक उपाय सबसे अच्छा उत्तर चुनने से पहले मॉडल को कई लॉजिक पथों का पता लगाने की अनुमति देते हैं।। यह मॉडल को समय से पहले एक एकल तर्क पथ के लिए प्रतिबद्धता से रोकता है, जो अक्सर त्रुटियों की ओर जाता है। आत्म-संगतता डिकोडिंग कई उत्तरों का उत्पादन करके सटीकता बढ़ाती है और सबसे अधिक बार सही उत्तर की पसंद। अगला, फ्रेमवर्क रोजगार देता है आसवन शिक्षाछोटे मॉडल विस्तृत गणना के बिना बड़े लोगों से तर्क क्षमताओं की विरासत की अनुमति देते हैं। इन तकनीकों के संयोजन से, शोधकर्ताओं ने हासिल किया है समझौता किए बिना उच्च दक्षता। विधि यह सुनिश्चित करती है कि मॉडल के साथ प्रशिक्षित आधे से कम गिनती संसाधनों पारंपरिक तरीके जटिल तर्क कार्यों पर समान या उच्च स्तर करते हैं।

व्यापक मूल्यांकन से पता चलता है कि जब परीक्षण-समय स्केलिंग मॉडल के लिए 4 × फ्लॉप द्वारा अनुमान लागत को कम किया जाता है, तो यह इसे सरल-से-मध्यम कार्यों पर 14 × के साथ संगत होने में सक्षम बनाता है। लोरा और क्लोरा एकीकृत करके स्मृति-कुशल प्रशिक्षण में योगदान करते हैं कम-रैंक अनुकूलन के साथ 4-बिट परिमाणीकरणउपभोक्ता जीपीयू ठीक ट्यूनिंग पर सक्षम करें। BitsAndbites मॉडल के प्रदर्शन को बनाए रखते हुए Ze को मेमोरी की खपत को पूरा करने के लिए 8-बिट इम्पेक्ट ptimizers प्रदान करता है। ट्री-ऑफ-थॉट लॉजिक में उच्च है डिज़ाइन किए गए मल्टी-स्टेप समस्याओं को हल कियाजटिल कार्यों में निर्णय लेने की सटीकता में सुधार करें। एक ही समय पर, मोंटे कार्लो ट्री सर्च मल्टी-स्टेप लॉजिक के दृश्यों में प्रतिक्रिया चयन में सुधार करता है, विशेष रूप से विजय में .Nik Q & A कार्यों में। यह निष्कर्षों को रोशन करता है तर्क क्षमताओं का त्याग किए बिना एलएलएम कार्यक्षमता में सुधार करने के लिए आयाम-कुशल फाइन-ट्यूनिंग की संभावना।
यह शोध एक है व्यावहारिक और स्केलेबल निपटान गणना की मांग को कम करते हुए एलएलएम में सुधार करना। संरचना यह सुनिश्चित करती है कि अत्यधिक संसाधनों के बिना मॉडल द्वारा उच्च प्रदर्शन प्राप्त किया जाता है आयाम-कुशल फाइन-ट्यूनिंग, टेस्ट-टाइम स्केलिंग और मेमोरी-कुशल ऑप्टिमाइज़ेशन का एक संयोजन। निष्कर्ष बताते हैं कि भविष्य के विकास में एक संतुलन होना चाहिए तर्क दक्षता के साथ मॉडल आकारएलएलएम प्रौद्योगिकी के लिए व्यापक पहुंच को सक्षम करना। कंपनियों और संस्थानों की तलाश में लागत प्रभावी ए.आई.यह अनुसंधान के लिए नींव निर्धारित करता है कुशल और स्केलेबल एलएलएम की तैनाती।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
निखिल मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह खड़गपुर में भारतीय संगठन की प्रौद्योगिकी में सामग्री में दोहरी डिग्री प्राप्त कर रहा है। निखिल एआई/एमएल उत्साही है जो हमेशा बायोमेट्रियल और बायोमेडिकल विगल्स जैसे क्षेत्रों में आवेदन पर शोध करता है। भौतिक अभिव्यक्ति में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति और योगदान की संभावना की तलाश कर रहा है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)


