
बड़े -लैंगुएज मॉडल डेल्स (एलएलएम) को सुदृढ़ीकरण सीखने की तकनीकों से काफी लाभ होता है, जिससे पुरस्कारों से सीखने से बार -बार सुधार हो सके। हालांकि, इन मॉडलों को कुशलता से प्रशिक्षित करना चुनौतीपूर्ण है, क्योंकि उन्हें अक्सर अपनी क्षमताओं को बढ़ाने के लिए व्यापक डेटासेट और मानव पर्यवेक्षण की आवश्यकता होती है। विकासशील तरीके जो एलएलएम को अतिरिक्त मानव इनपुट या बड़े पैमाने पर वास्तुशिल्प परिवर्तनों के बिना स्वायत्त रूप से आत्म-सुधार करने की अनुमति देते हैं, एआई अनुसंधान में एक प्रमुख ध्यान केंद्रित हो गया है।
प्रशिक्षण एलएलएम की मुख्य चुनौती यह सुनिश्चित करती है कि सीखने की प्रक्रिया कुशल और संरचित है। जब मॉडल अपनी क्षमताओं के साथ समस्याओं का सामना करते हैं, तो प्रशिक्षण प्रक्रिया स्टाल हो सकती है, जिससे खराब प्रदर्शन हो सकता है। पारंपरिक सुदृढीकरण सीखने की तकनीक प्रभावी शिक्षा के तरीके बनाने के लिए अच्छी तरह से इलाज किए गए डेटासेट या मानव प्रतिक्रिया पर निर्भर करती है, लेकिन यह दृष्टिकोण संसाधन-गहन है। इसके अलावा, एलएलएमएस संरचित कठिनाई को बिना ग्रेड डल के व्यवस्थित रूप से सुधारने के लिए संघर्ष करता है, जिससे बुनियादी तर्क कार्यों और अधिक जटिल समस्याओं के बीच की दूरी को पार करना मुश्किल हो जाता है।
प्रशिक्षण के लिए मौजूदा दृष्टिकोण में मुख्य रूप से सुदृढीकरण शिक्षा और मानव प्रतिक्रिया (RLHF) से पाठ्यक्रम शिक्षा शामिल है। देखे गए फाइन-ट्यूनिंग के लिए मैन्युअल रूप से लेबल किए गए डेटासेट की आवश्यकता होती है, जिससे ओवरफिटिंग और सीमित सामान्यीकरण हो सकता है। RLHF मानव निरीक्षण के एक स्तर का प्रतिनिधित्व करता है, जहां मॉडल मानव मूल्यांकन के आधार पर शुद्ध होते हैं, लेकिन यह विधि महंगी है और प्रभावी रूप से तराजू नहीं है। पाठ्यक्रम शिक्षा, जो धीरे-धीरे काम की कठिनाई को बढ़ाती है, ने वादा दिखाया है, लेकिन वर्तमान कार्यान्वयन अभी भी मॉडल को शिक्षा के तरीके को उत्पन्न करने के लिए मॉडल की अनुमति देने के बजाय पूर्व-परिभाषित डेटासेट पर निर्भर करता है। ये सीमाएं स्वायत्त शिक्षा संरचना की आवश्यकता को उजागर करती हैं जो LLM को स्वतंत्र रूप से उनकी समस्या को हल करने की क्षमताओं को ठीक करने में सक्षम बनाती है।
टुफा लैब्स के शोधकर्ता प्रतिनिधित्व करते हैं एक कैडय द्वारा सीखें (राइकर्स द्वारा स्वायत्त मुसीबत-आधारित उदाहरण) इन सीमाओं को दूर करने के लिए। यह संरचना एलएलएम को जटिल समस्याओं को दोहराने और दोहराने और सरल प्रकार के सिम्स को हल करके आत्म-मरम्मत करने में सक्षम बनाती है। मानव हस्तक्षेप या ठीक किए गए डेटासेट के आधार पर पिछले तरीकों के विपरीत, सीडी मॉडल क्षमताएं एक प्राकृतिक कठिनाई बनाने का लाभ देती हैं, जो संरचित आत्म-शिक्षण की अनुमति देती है। अनुसंधान टीम ने गणितीय एकीकरण कार्यों पर सीडी का विकास और परीक्षण किया, मॉडल के प्रदर्शन को बढ़ाने में इसकी प्रभावशीलता को दर्शाया। सीडी को लागू करके, शोधकर्ताओं ने गणितीय तर्क क्षमताओं में एक अभूतपूर्व छलांग लगाने में सक्षम किया, स्नातक एकीकरण समस्याओं पर अपनी सटीकता में सुधार करने के लिए एक 3-बिलियन-माता-पिता लालमा 2.1 मॉडल। इसके अलावा, दृष्टिकोण को बड़े मॉडलों में विस्तारित किया गया था, जैसे कि QWEN2.5 7B DIPCICK-R1 डिस्टिल्ड, MIT एकीकरण B क्वालिफाइंग परीक्षाओं पर 73% सटीकता प्राप्त करता है, GPT-4O जैसे मॉडल, और 15-30% की सीमा में विशिष्ट मानव प्रदर्शन।
सीडी एक संरचित विधि का अनुसरण करता है जो एलएलएम को व्यवस्थित रूप से जटिल समस्याओं को तोड़ने और उनकी शिक्षा को बूटस्ट्रैप करने की अनुमति देता है। प्रक्रिया में तीन प्राथमिक घटक शामिल हैं: संस्करण उत्पादन, समाधान सत्यापन और सुदृढीकरण शिक्षा। वेरिएंट जनरेशन स्टेप यह सुनिश्चित करता है कि मॉडल किसी दिए गए समस्या के सरल संस्करणों का उत्पादन करता है, जो एक संरचित समस्या बनाता है। समाधान सत्यापन मानव हस्तक्षेप के बिना तत्काल प्रतिक्रिया प्रदान करते हुए, चरण उत्पन्न समाधानों की शुद्धता का मूल्यांकन करने के लिए सांख्यिकीय एकीकरण विधियों का उपयोग करता है। अंत में, एक समूह -संबंधित नीति सुदृढीकरण शिक्षा घटक मॉडल को प्रभावी ढंग से प्रशिक्षित करने के लिए ऑप्टिमेंट ptimization (GRPO) का उपयोग करती है। यह प्रोटोकॉल मॉडल डेल को परीक्षण किए गए समाधानों का लाभ देकर अधिक जानने में सक्षम बनाता है, जिससे यह व्यवस्थित रूप से अपनी समस्या को ठीक करने की अनुमति देता है। शोधकर्ता इस दृष्टिकोण का विस्तार परीक्षण-समय सुदृढीकरण सीखने (TTRL) के साथ करते हैं, जो सूचकांक के दौरान समस्या के प्रकार को गतिशील करता है और वास्तविक समय में समाधान में सुधार करने के लिए एक सुदृढीकरण शिक्षा लागू करता है। जब MIT एकीकरण एक BEE क्वालीफाइंग परीक्षा पर लागू होता है, तो TTRL ने Openai के O1 मॉडल को पार करते हुए मॉडल की सटीकता को 73% से 90% तक बढ़ा दिया है।

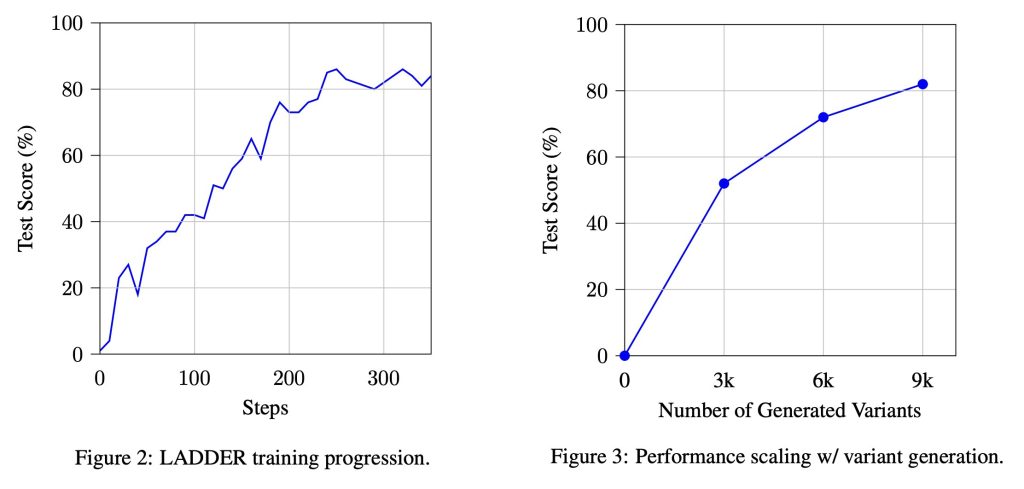
जब 110 अंडरग्रेजुएट-स्तरीय एकीकरण समस्याओं के डेटासेट पर परीक्षण किया जाता है, तो सीडीएस के साथ प्रशिक्षित लालमा 3.2 3 बी मॉडल का उपयोग करते समय 2% सटीकता की तुलना में 82% सटीकता प्राप्त करता है, पास@10 नमूना। दृष्टिकोण में स्केलेबिलिटी भी थी, क्योंकि उत्पन्न प्रकारों की संख्या में वृद्धि लगातार सुधार कर रही थी। इसके विपरीत, प्रकारों के बिना सुदृढीकरण की शिक्षा सार्थक लाभ प्राप्त करने में विफल रही, एक संरचित समस्या के अपघटन के महत्व को मजबूत करती है। शोधकर्ताओं ने देखा है कि सीडी-प्रशिक्षित मॉडल उन्नत तकनीकों की आवश्यकताओं को हल कर सकते हैं जो पहले पहुंच से बाहर थे। MIT इंटीग्रेशन B क्वालिफाइंग परीक्षा में विधि का उपयोग करते हुए, CDS के साथ प्रशिक्षित Dippacic-R1 CWN 2.5 7B मॉडल, जो गणितीय तर्क में संरचित आत्म-सुधार की प्रभावशीलता को प्रदर्शित करता है।

सीढ़ी पर शोध से मुख्य उपाय में शामिल हैं:
- सरल प्रकार की जटिल समस्याओं को दोहराने और हल करके एलएलएम को आत्म-मरम्मत करने में सक्षम बनाता है।
- लालमा 3.2 3 बी मॉडल स्नातक एकीकरण कार्यों पर 1% से 82% तक बढ़ गया है, जो संरचित स्व-सीखने की प्रभावशीलता को दर्शाता है।
- QWEN2.5 7B DIPPEC-R1 ने 73%सटीकता प्राप्त की, GPT-4O (42%) को बेहतर बनाया और मानव संचालन (15-30%) से अधिक।
- सामने की सटीकता ने Openai के O1 मॉडल को पार कर लिया, जो 73% से बढ़कर 90% हो गया।
- सीढ़ी को बाहरी डेटासेट या मानव हस्तक्षेप की आवश्यकता नहीं होती है, जिससे यह एलएलएम प्रशिक्षण के लिए एक लागत प्रभावी और स्केलेबल समाधान बन जाता है।
- सीडी के साथ प्रशिक्षित मॉडल ने संरचित परेशानी के ग्रेड डल के बिना सुदृढीकरण शिक्षा की तुलना में सबसे अच्छी समस्या को हल करने की क्षमताओं को दिखाया।
- यह संरचना एआई मॉडल को बाहरी पर्यवेक्षण के बिना अपने तर्क कौशल में सुधार करने के लिए एक संरचित तरीका प्रदान करती है।
- प्रतिस्पर्धी प्रोग्रामिंग, प्रमेय सिद्ध और एजेंट-आधारित समस्या हल होने तक विधि का विस्तार किया जा सकता है।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली
ASIF Razzaq एक दूरदर्शी उद्यमी और इंजीनियर के रूप में मार्केटएकपोस्ट मीडिया इंक के सीईओ हैं, ASIF सामाजिक अच्छे के लिए कृत्रिम बुद्धिमत्ता की संभावना को बढ़ाने के लिए प्रतिबद्ध है। उनका सबसे हालिया प्रयास आर्टिफिशियल इंटेलिजेंस मीडिया प्लेटफॉर्म, मार्कटेकपोस्ट का उद्घाटन है, जो मशीन लर्निंग की गहराई के लिए और कवरेज की गहराई के लिए गहरी सीखने की खबर के लिए है। यह तकनीकी रूप से ध्वनि है और एक बड़े दर्शकों द्वारा आसानी से समझ में आता है। प्लेटफ़ॉर्म में 2 मिलियन से अधिक मासिक दृश्य हैं, जो दर्शकों के बीच अपनी लोकप्रियता दिखाते हैं।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)