

नवीनतम अपडेट और प्रमुख एआई कवरेज पर विशिष्ट सामग्री के लिए हमारे दैनिक और साप्ताहिक समाचार पत्र में शामिल हों। और अधिक जानें
क्वीन टीम ने अपने ओपन-सेरस क्वीन मॉडल डेल्स (एलएलएमएस) के बढ़ते परिवार को अपने ओपन-सीस सीयूआरएस दिग्गज अलीबाबा के डिवीजन के बढ़ते परिवार को विकसित किया है, जो क्यूडब्ल्यू -32 बी का परिचय दे रहा है, जो कि रिनफोर्सन लर्निंग (आरएल) द्वारा समस्या की मरम्मत की समस्या में सुधार करना है। मॉडल है।
मॉडल अपाचे 2.0 लाइसेंस के तहत मॉडलोस्कोप पर गले लगाने के चेहरे पर और मॉडल पर एक खुले वजन के रूप में उपलब्ध है। इसका मतलब यह है कि यह पेशेवर और अनुसंधान उपयोग के लिए उपलब्ध है, इसलिए उद्यम तुरंत उन्हें अपने उत्पादों और अनुप्रयोगों को बिजली देने के लिए नियोजित कर सकते हैं (लेकिन वे ग्राहकों को उपयोग करने के लिए भी शुल्क लेते हैं)।
यह क्वान चैट द्वारा व्यक्तिगत उपयोगकर्ताओं के लिए भी सफल हो सकता है।
क्वान-विथ-शुनो ओपन के अलीबाबा के ओपन लॉजी मॉडल O1 का जवाब था
QWK के लिए शॉर्ट, क्वीन-WIH-PRASHAN, को पहले नवंबर 2024 में Openai के O-Pupil के साथ प्रतिस्पर्धा के उद्देश्य से एक ओपन सोर्स लॉजिक मॉडल के रूप में पेश किया गया था।
प्रक्षेपण पर, मॉडल को अपनी स्वयं की समीक्षा और अपने स्वयं के उत्तरों की शुद्धि के माध्यम से तार्किक तर्क और योजना को बढ़ाने के लिए डिज़ाइन किया गया था, एक ऐसी तकनीक जिसने इसे विशेष रूप से गणित और कोडिंग कार्यों में प्रभावी बना दिया।
QWQ के प्रारंभिक संस्करण में 32 बिलियन आयाम और 32,000-टोकन संदर्भ लंबाई शामिल हैं, जिसमें अलीबाबा ने AIM और गणित जैसे गणितीय बेंचमार्क में O1-Wolf को आगे बढ़ाने की क्षमता पर प्रकाश डाला है, साथ ही GPQA जैसे चर तर्क कार्यों के साथ रोशन करता है।
अपनी शक्ति के बावजूद, CWQ के शुरुआती पुनरावृत्ति Lividbanch जैसे प्रोग्रामिंग बेंचमार्क के साथ संघर्ष करती हैं, जहां Openai मॉडल ने बढ़त बनाए रखी। इसके अलावा, कई उभरते लॉजिक मॉडल की तरह, QWQ को भाषा मिश्रण और सामयिक परिपत्र तर्क छोरों जैसी चुनौतियों का सामना करना पड़ा।
हालांकि, Apache 2.0 लाइसेंस के तहत मॉडल को जारी करने के अलीबाबा के फैसले ने यह सुनिश्चित किया कि डेवलपर्स और उद्यम स्वतंत्र रूप से सुविधाजनक और इसका व्यवसायीकरण कर सकते हैं, इसे Openai के O3 से अलग कर सकते हैं।
CWQ की प्रारंभिक रिलीज के साथ, AI परिदृश्य तेजी से विकसित हुआ है। पारंपरिक एलएलएम की सीमाएं अधिक स्पष्ट हैं, स्केलिंग कानून संचालन में सुधार में गिरावट देते हैं।
इस पालतू जानवर ने बड़े लॉजिक मॉडल (LRMS) -A AI सिस्टम की नई श्रेणी में रुचि बढ़ाई है जो सटीकता बढ़ाने के लिए अनुमानित तर्क और आत्म-प्रतिबिंब का उपयोग करता है। इसमें Openai की O3 श्रृंखला और प्रतिद्वंद्वी चीनी लैब Dippic की एक सफल Dippic-R1 शामिल है, जो हांगकांग मात्रात्मक विश्लेषण फर्म हाई-फ्लाइर कैपिटल मैनेजमेंट का SH फशुत है।
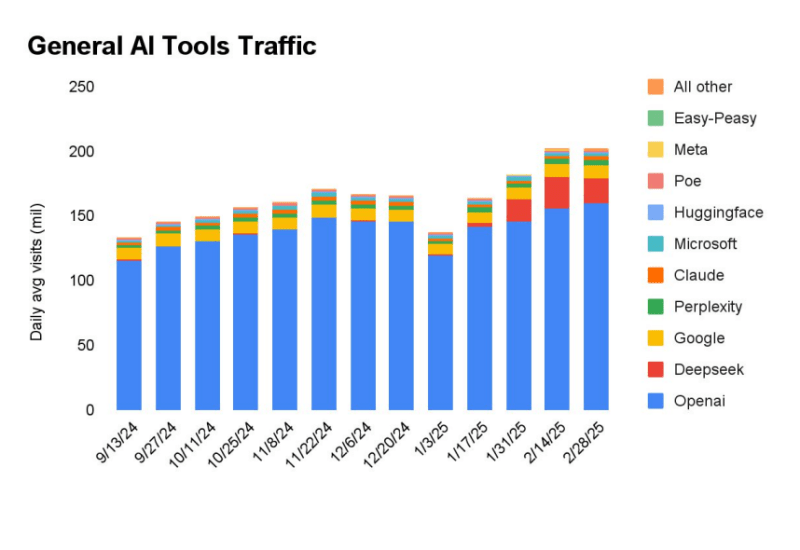
वेब ट्रैफ़िक एनालिटिक्स और रिसर्च फर्म सेमिवब की एक नई रिपोर्ट में पाया गया है कि जनवरी 2024 में आर 1 की शुरुआत के बाद से, डीपीसीके ने ओपन ओपनई के पीछे सबसे अधिक देखी जाने वाली एआई मॉडल-प्रोसेसिंग वेबसाइट बनने के लिए चार्ट को रोक दिया है।

QWQ-32B, अलीबाबा की नवीनतम पुनरावृत्ति, आरएल और संरचित आत्म-शब्दों को एकीकृत करके इन प्रगति का निर्माण करती है, जिससे यह तर्क-केंद्रित एआई के बढ़ते क्षेत्र में एक गंभीर प्रतिद्वंद्वी बन जाता है।
बहु-चरण सुदृढीकरण सीखने के साथ स्केलिंग संचालन
पारंपरिक निर्देश से बने मॉडल अक्सर कठिन तर्क कार्यों के साथ संघर्ष करते हैं, लेकिन रानी टीम के शोध से पता चलता है कि आरएल जटिल समस्याओं को हल करने की क्षमता में काफी सुधार कर सकता है।
QWQ-32B गणितीय तर्क, कोडिंग विशेषज्ञता और सामान्य समस्या-समाधान को बढ़ाने के लिए एक बहु-चरण आरएल प्रशिक्षण दृष्टिकोण को लागू करके इस विचार पर निर्माण करता है।
इस मॉडल को Dippic-R1, O 1-Mini और DeepCick-R1-Distilliled-quan-32b जैसे प्रमुख विकल्पों के खिलाफ बेंचमार्क किया गया है, जो कुछ मॉडलों की तुलना में कम आयामों के बावजूद प्रतिस्पर्धी परिणाम दिखाता है।

उदाहरण के लिए, जब DEEPCC-R1 आयामों (37 बिलियन सक्रिय के साथ) के साथ काम करता है, तो QW-32B VRAM के VRAM (VRAM) के बहुत छोटे चरणों के साथ तुलनात्मक संचालन प्राप्त करता है, VRAM के VRAM के साथ VRAM के साथ NVIDIA के H100 की आवश्यकता होती है। आरएल दृष्टिकोण की कार्यक्षमता को रिले करें।
QWQ -32B एक उचित भाषा मॉडल वास्तुकला का अनुसरण करता है और इसमें कई इष्टतम ptimization शामिल हैं:
- 64 रस्सी, स्विग्लू, RMSNORM और ट्रांसफार्मर परतें ध्यान के साथ QKV पूर्वाग्रह;
- सामान्यीकृत क्वेरी ध्यान (GQA) क्वेरी के लिए 40 ध्यान प्रमुख और कुंजी-मूल्य जोड़े;
- विस्तारित संदर्भ लंबाई 131,072 टोकन की अनुमति देती है, बेहतर संचालन लंबे समय तक असंबद्ध इनपुट;
- बहु-चरण प्रशिक्षण सहित, फाइन-ट्यूनिंग और आरएल का अवलोकन किया।
QWQ -32B के लिए RL प्रक्रिया को दो चरणों में निष्पादित किया गया था:
- गणित और कोडिंग फोकस: मॉडल को गणितीय तर्क के लिए सटीकता सत्यापनकर्ता और कोडिंग कार्यों के लिए एक कोड निष्पादन सर्वर का उपयोग करके प्रशिक्षित किया गया था। यह दृष्टिकोण यह सुनिश्चित करता है कि उत्पन्न उत्तर सुदृढीकरण से पहले शुद्धता के लिए मान्य थे।
- सामान्य क्षमता वृद्धि: दूसरे चरण में, मॉडल ने सामान्य पुरस्कार मॉडल और नियम -आधारित वेरिफायर का उपयोग करके पुरस्कार -आधारित प्रशिक्षण प्राप्त किया। इस स्तर पर, अपने गणित और कोडिंग क्षमताओं से समझौता किए बिना, मानव कॉन्फ़िगरेशन और एजेंट तर्क का पालन करके संशोधित अधिसूचना।
उद्यम निर्णय लेने के लिए इसका क्या मतलब है
एंटरप्राइज़ लीडर्स-सीटीओ, सीटीओ, आईटी लीडर्स, टीम मैनेजर और एआई ऐप डेवलपर्स के लिए, जिनमें CWQ-32B AI शामिल हैं, वे व्यावसायिक निर्णयों और तकनीकी नवाचार का समर्थन कर सकते हैं।
अपनी आरएल-संचालित लॉजिक क्षमताओं के साथ, मॉडल अधिक सटीक, संरचित और संदर्भ-जागरूक अंतर्दृष्टि प्रदान कर सकता है, जो इसे स्वचालित डेटा विश्लेषण, रणनीतिक योजना, सॉफ्टवेयर फैटवेयर विकास और बुद्धिमान ऑटो टोमेशन के मामलों के लिए मूल्यवान बनाता है।
जटिल समस्याओं, कोडिंग सहायता, वित्तीय मॉडलिंग या ग्राहक सेवा स्वचालन के लिए एआई समाधानों को तैनात करने वाली कंपनियां QWQ -32B का एक आकर्षक विकल्प पा सकती हैं। इसके अलावा, इसके खुले वजन की उपलब्धता संगठनों को स्वामित्व प्रतिबंधों के बिना डोमेन-विशिष्ट अनुप्रयोगों के लिए मॉडल को ठीक करने और अनुकूलित करने की अनुमति देती है, जिससे यह एंटरप्राइज एआई रणनीति के लिए एक लचीला विकल्प बन जाता है।
तथ्य यह है कि यह चीनी ई-सीयू मर्स की विशालकाय से आता है, कुछ गैर-चीनी उपयोगकर्ताओं के लिए कुछ सुरक्षा और पूर्वाग्रह चिंताओं को बढ़ा सकता है, खासकर जब क्वेन चैट इंटरफ़ेस का उपयोग करते हैं। लेकिन डीपस्क-आर 1 की तरह, यह इस तथ्य के कारण है कि डाउनलोड और ऑफ़लाइन फ्रेम उपयोग के लिए मॉडल पर उपलब्ध है और ठीक-ट्यूनिंग या रिटर्निंग के लिए गले का संकेत मिलता है कि यह आसानी से हटाया जा सकता है। और यह डीपस्क-आर 1 का एक व्यवहार्य विकल्प है।
एआई पावर उपयोगकर्ताओं और प्रभावितों से प्रारंभिक प्रतिक्रियाएं
QWQ -32B की रिहाई ने पहले से ही AI अनुसंधान और विकास समुदाय का ध्यान आकर्षित किया है, जिसमें कई डेवलपर्स और उद्योग के पेशेवरों ने X (पिछले ट्विटर) पर अपनी प्रारंभिक छाप साझा की:
- Vaibhav Srivastava (@rich_vb) चिल्लाते हुए QWQ -32B की गति को प्रदाता हाइपरबोलिक लैब्स के लिए जिम्मेदार ठहराता है, इसे “ब्लेज़ली फास्ट” और टॉप -टियर मॉडल के बराबर कहा जाता है। उन्होंने यह भी कहा कि मॉडल “Dippacc-R1 और Openai Apache 2.0 लाइसेंस को O1-Mini पर हरा रहे हैं।”
- एआई समाचार और अफवाह प्रकाशक एक चब्बी चेहरे (@Chemomonies) मॉडल के प्रदर्शन से प्रभावित थे, इस बात पर जोर देते हुए कि QW -32B कभी -कभी 20 गुना छोटा है, भले ही दीप्सिक -R1। “पवित्र मौली! पकाया गया! “उन्होने लिखा है।
- Uuchen Jin (@uuchenje_uw), हाइपरबोलिक लैब्स के सह-संस्थापक और सीटीओ, दक्षता के लाभों को देखते हुए, प्रकाशन का जश्न मनाया। “छोटे मॉडल बहुत शक्तिशाली हैं! अलीबाबा क्वेन ने QWQ-32B, एक लॉजिक मॉडल डेल पेश किया, जो डीप्सिक-आर 1 (671 बी) और ओपनई ओ 1-मिनी को हरा देता है! “
- दूसरे हगिंग फेस टीम के सदस्य, एरिक कानीज़िकी (@erikkaum) ने चेहरे के अंतिम बिंदुओं पर एक-क्लिक परिनियोजन के लिए तैनाती, साझा करने या उपलब्ध होने की आसानी पर जोर दिया, जिसने मॉडल को गले लगा लिया, जिससे यह विस्तारित सेटअप के बिना डेवलपर्स के लिए सुलभ हो गया।
एजेंसी
QWQ-32B में एजेंट होते हैं, जिससे यह पर्यावरणीय प्रतिक्रिया के आधार पर तर्क प्रक्रियाओं को गतिशील प्रक्रियाओं को समायोजित करने की अनुमति देता है।
सर्वश्रेष्ठ प्रदर्शन के लिए, क्वेन टीम निम्नलिखित पूर्वानुमान सेटिंग्स का उपयोग करने की सिफारिश करती है:
- तापमान: 0.6
- ऊपर: 0.95
- मारना: 20-40 के बीच
- यार्न स्केलिंग: 32,768 से अधिक टोकन के लिए अनुक्रमों को संभालने की सिफारिश की
मॉडल VLLM, एक उच्च-थ्रूपुट अनुमान संरचना का उपयोग करके तैनाती का समर्थन करता है। हालांकि, वीएलएम का वर्तमान कार्यान्वयन केवल स्थिर यार्न स्केलिंग का समर्थन करता है, जो इनपुट लंबाई की परवाह किए बिना एक निश्चित स्केलिंग कारक को बनाए रखता है।
भविष्य का विकास
QWQ-32B आरएल को रानी की तर्क क्षमता को बढ़ाने के लिए स्केलिंग के पहले चरण के रूप में देखता है। आगे देखते हुए, टीम की योजना है:
- मॉडल की बुद्धिमत्ता में सुधार करने के लिए अधिक स्केलिंग आरएलएस का अन्वेषण करें;
- लंबे समय से उन्मुख तर्क के लिए आरएल के साथ एजेंटों को एकीकृत करें;
- आरएल के लिए इष्टतम ptimise फाउंडेशन मॉडल विकसित करना जारी रखें;
- अधिक उन्नत प्रशिक्षण तकनीकों के माध्यम से आर्टिफिशियल जनरल इंटेलिजेंस (एजीआई) के लिए आगे बढ़ें।
QWQ -32B के साथ, QWN टीम AI मॉडल के आगामी पे -जनरेशन के मुख्य चालक के रूप में RL की जगह ले रही है, यह दर्शाता है कि स्केलिंग बहुत प्रदर्शन और प्रभावी लॉजिक सिस्टम का उत्पादन कर सकती है।


