

कैसे सुधारें बड़े भाषा मॉडल (एलएलएम) कम्प्यूटेशनल लागत को कम रखते हुए जटिल तर्क कार्यों को संभालें एक चुनौती है। कई तर्क चरणों का उत्पादन करना और सबसे अच्छा उत्तर चुनने से सटीकता बढ़ती है, लेकिन यह प्रक्रिया कई मेमोरी और कंप्यूटिंग शक्ति की मांग करती है। लंबे तर्क श्रृंखलाओं या विस्तृत चेस शतरंज से निपटने की गणना गणना से की जाती है और मॉडल को धीमा कर दिया जाता है, जिससे उन्हें सीमा कम्प्यूटेशनल संसाधनों के तहत अक्षम हो जाता है। विभिन्न आर्किटेक्ट्स के अन्य मॉडलों में तेजी से सूचना प्रक्रियाएं और कम मेमोरी होती है, लेकिन तर्क कार्यों में संचालित करने की उनकी क्षमता अच्छी तरह से है। यह समझना कि ये मॉडल उन लोगों से मेल खाते हैं या उनसे अधिक हो सकते हैं जो एलएलएम को अधिक कुशल बनाने के लिए सीमित संसाधनों के तहत मौजूद हैं।
वर्तमान में, बड़े भाषा मॉडल में तर्क में सुधार के तरीके कई तर्क उपायों का उत्पादन करने और बहुसंख्यक मतदान और प्रशिक्षित पुरस्कार मॉडल जैसी तकनीकों का उपयोग करके सबसे अच्छा उत्तर चुनने पर निर्भर करते हैं। विधियाँ सटीकता के स्तर में सुधार करती हैं, हालांकि उन्हें बड़ी गिनती प्रणालियों की आवश्यकता होती है, जो बड़े डेटा प्रोसेसिंग के लिए उनके अनुरूप हैं। ट्रांसफार्मर मॉडल की प्रसंस्करण शक्ति आवश्यकताओं और मेमोरी आवश्यकताओं को अनुमानित ऑपरेशन को धीमा कर दिया। बार -बार मॉडल और रैखिक ध्यान के तरीके इस प्रक्रिया में तेजी से काम करते हैं लेकिन तर्क संचालन में प्रभावशीलता की कमी होती है। जुनोवलेज Junowledge छोटे मॉडलों में स्थानांतरित करने में मदद करता है, लेकिन क्या विभिन्न मॉडल प्रकारों में मजबूत तर्क क्षमताओं का हस्तांतरण स्पष्ट नहीं है।
इन मुद्दों को कम करने के लिए, जिनेवा विश्वविद्यालय, एआई, कॉर्नेल विश्वविद्यालय, ईपीएफएल, कार्नेगी मेलन विश्वविद्यालय, कार्टेसिया। ए।, मेटा और प्रिंसटन विश्वविद्यालय के शोधकर्ताओं ने एक प्रस्ताव बनाया। आसवन तंत्र लॉजिक क्षमताओं को बनाए रखते हुए, तर्क कौशल के साथ चमड़े के नीचे बनाने के लिए दक्षता में सुधार करें। डिस्टिल्ड मॉडल उनसे परे चले गए परिवर्तनकारी शिक्षकों पर अंक शास्त्र और जीएसएम 8K कसरत करना 2.5 × कम अनुमान लगाने का समय। इससे पता चला कि कम्प्यूटेशनल लागत को कम करते हुए तर्क और गणितीय कौशल को आर्किटेक्चर में स्थानांतरित किया जा सकता है।
फ्रेमवर्क में दो मॉडल प्रकार शामिल हैं: शुद्ध मंबा मॉडल डेलो (ललंबा) और हाइब्रिड मॉडल (मम्बैनल्लामा)। Llamba उपयोग मोहौक आसवन की विधि, मैट्रिस को संरेखित करना, छिपे हुए राज्यों का मिलान करना और प्रशिक्षण के दौरान वजन स्थानांतरित करना 8 बी-टोकन डेटासेट। Mambinlama ने ट्रांसफॉर्मर ध्यान के स्तर को बनाए रखा, लेकिन दूसरों को आम की परतों के साथ बदल दिया, इसके विपरीत का उपयोग करके KL आसवन के लिए। प्रयोगों से पता चलता है कि डेटासेट च्वाइस के प्रदर्शन का एक बड़ा प्रभाव था, कुछ डेटासेट कम हो गए लैम्बबा -1 बी द्वारा सटीकता 10% और सामान्य बेंचमार्क और गणितीय तर्क के बीच एक कमजोर संबंध दिखाता है, बेहतर प्रशिक्षण डेटा के महत्व पर जोर देता है।
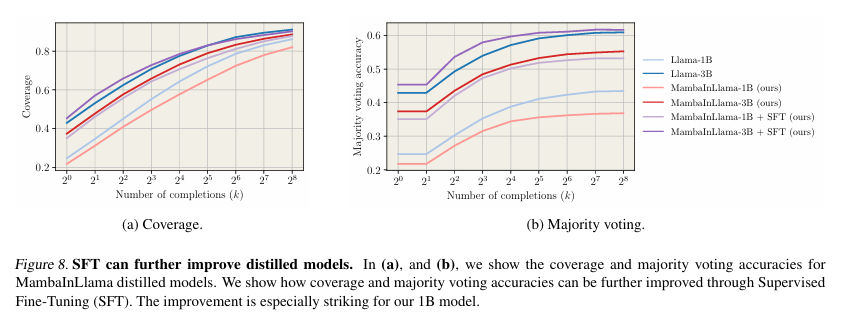
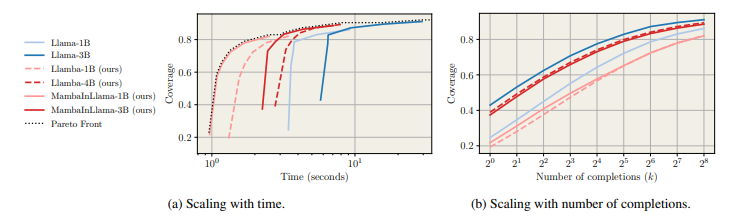
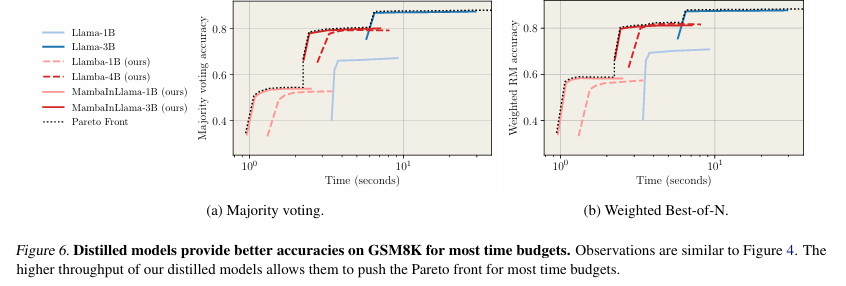
शोधकर्ताओं ने कई का उत्पादन करने के लिए डिस्टिल्ड मॉडल का मूल्यांकन किया विचार की श्रृंखला (बिल्लियाँ) गणितीय समस्याओं पर ध्यान केंद्रित करते हुए, निर्देश-अनचाहे प्रतिधारण। उन्होंने उपयोग करके कवरेज को मापा पास@kइसने नमूनों के बीच एक सच्ची समझौता खोजने की संभावना का अनुमान लगाया, और अधिकांश मतदान के माध्यम से सटीकता का मूल्यांकन किया और भरा हुआ चुनाव करना लालमा -3.1 8 बी-आधारित पुरस्कार मॉडल। बेंचमार्क ने डिस्टिल्ड मॉडल दिखाए 4.2 × तुलनात्मक कवरेज को बनाए रखना, लालमा मॉडल की तुलना में तेजी से, निश्चित गणना बजट में अधिक पूर्णता उत्पन्न करती है, और गति और सटीकता में छोटे ट्रांसफार्मर ठिकानों को ले जाती है। इसके अलावा, निरीक्षण फाइन-ट्यूनिंग (एसएफटी) आसवन बढ़ाया संचालन के बाद, कोडिंग और औपचारिक पचरिक साक्ष्य जैसे संरचित तर्क कार्यों में उनकी प्रभावशीलता को पहचानें।
सारांश में, प्रस्तावित डिस्टिल्ड मैंगो मॉडल ने अनुमान समय और स्मृति की खपत में कटौती करते हुए सटीकता बनाए रखकर तर्क दक्षता में वृद्धि की। जब कम्प्यूटेशनल बजट तय किया गया था, तो मॉडल ट्रांसफॉर्मर को पीछे छोड़ देते हैं; इसलिए, वे स्केलेबल अनुमानों के लिए उपयुक्त हैं। यह विधि अच्छे तर्क मॉडल, आसवन के तरीकों को बेहतर बनाने और पुरस्कार मॉडल बनाने के लिए भविष्य के अनुसंधान के लिए आधार के रूप में काम कर सकती है। पूर्वानुमान स्केलिंग प्रगति आगे एआई सिस्टम में उनके आवेदन को बढ़ाएगी जो तेजी से और अधिक प्रभावी तर्क की मांग करते हैं।
जाँच करना कागज़। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
Divish मार्केटकपोस्ट में एक परामर्श इंटर्न है। वह खड़गपुर के एक भारतीय संगठन प्रौद्योगिकी एफ प्रौद्योगिकी से कृषि और खाद्य इंजीनियरिंग में BTech का पीछा कर रहे हैं। यह एक डेटा साइंस और मशीन लर्निंग उत्साही है जो इन प्रमुख तकनीकों को कृषि में एकीकृत करना चाहता है और चुनौतियों को हल करना चाहता है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)


