


Требования к обработке LLMS создают значительные проблемы, особенно для использования в реальном времени, где время быстрого отклика имеет жизненно важное значение. Обработка каждого вопроса заново-сожимающему трудоемкому и неэффективной, что требует огромных ресурсов. Поставщики услуг искусственного интеллекта преодолевают низкую производительность, используя систему кэша, которая хранит повторные запросы, так что на них можно ответить мгновенно, не ожидая, оптимизируя эффективность при сохранении задержки. Однако при ускорении времени отклика риски безопасности также возникают. Ученые изучили, как привычки кэширования API LLM могут невольно раскрывать конфиденциальную информацию. Они обнаружили, что пользовательские запросы и информация о модели с секрецией торговли могут протечь через боковые атаки на основе времени на основе коммерческих политик кэширования услуг искусственного интеллекта.
Одним из ключевых рисков быстрого кэширования является его потенциал для раскрытия информации о предыдущих пользовательских запросах. Если кэшированные подсказки передаются среди нескольких пользователей, злоумышленник может определить, предложил ли кто -то еще недавно аналогичную подсказку на основе различий времени отклика. Риск становится еще больше с глобальным кэшированием, когда подсказка одного пользователя может привести к более быстрому времени ответа для другого пользователя, отправляющего связанный запрос. Анализируя изменения времени отклика, исследователи продемонстрировали, как эта уязвимость может позволить злоумышленникам раскрыть конфиденциальные бизнес -данные, личную информацию и проприетарные запросы.
Различные поставщики услуг искусственного интеллекта кэшируют по -разному, но их политики кэширования не обязательно прозрачны для пользователей. Некоторые ограничивают кэширование однопользовательскими пользователями, так что кэшированные подсказки доступны только для человека, который их разместил, что не позволяет передавать данные между учетными записями. Другие внедряют кэширование для организации, чтобы несколько пользователей в фирме или организации могли делиться кэшированными подсказками. Несмотря на более эффективное, это также рискует утечка конфиденциальной информации, если некоторые пользователи обладают специальными привилегиями доступа. Наиболее угрожающий риск безопасности является результатом глобального кэширования, в котором все услуги API могут получить доступ к кэшированным подсказкам. В результате злоумышленник может манипулировать временем ответа, чтобы определить предыдущие представленные подсказки. Исследователи обнаружили, что большинство поставщиков ИИ не прозрачны с их политикой кэширования, поэтому пользователи не знают о угрозах безопасности, сопровождающих их запросы.
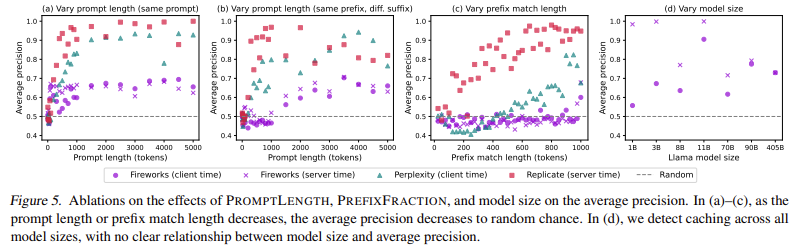
Чтобы исследовать эти проблемы, исследовательская группа из Стэнфордского университета разработала структуру аудита, способную обнаружить быстрое кэширование на разных уровнях доступа. Их метод включал в себя отправку контролируемых последовательностей подсказок в различные API AIS и измерение изменений времени отклика. Если бы подсказка была кэширована, время отклика было бы заметно быстрее при повторном поступлении. Они сформулировали статистические тесты гипотезы, чтобы подтвердить, происходит ли кэширование, и определить, распространяется ли обмен кешами за пределы отдельных пользователей. Исследователи определили закономерности, указывающие кеширование путем систематической регулировки длины приглашения, сходства префикса и частот повторения. Процесс аудита включал тестирование 17 коммерческих API AI, в том числе тех, которые предоставляются OpenAI, Anpropic, DeepSeek, Fireworks AI и другими. Их тесты были сосредоточены на выявлении того, было ли внедрено кэширование, и ограничено ли оно одним пользователем или обменом в более широкой группе.
Процедура аудита состояла из двух основных тестов: один для измерения времени отклика для хитов кэша, а другой для промахов в кешах. В тесте на кэш-хит был представлен один и тот же подсказка несколько раз, чтобы наблюдать, улучшилась ли скорость отклика после первого запроса. В тесте с пропуском кеша случайно сгенерированные подсказки были использованы для установления базовой линии для временного отклика Uncached. Статистический анализ этого времени отклика дал четкие доказательства кэширования в нескольких API. Исследователи определили поведение кэширования у 8 из 17 поставщиков API. Что еще более важно, они обнаружили, что 7 из этих поставщиков делятся кэшами по всему миру, что означает, что любой пользователь может сделать вывод шаблонов использования другого пользователя на основе скорости отклика. Их выводы также показали ранее неизвестную архитектурную деталь о модели Text-embedding-3-Small от Openai-поведение к кэшированию, указывающее на то, что она следует за структурой трансформатора только для декодера, кусочке информации, которая не была публично раскрыта.
Оценка эффективности кэшированных и не кэшированных подсказок подчеркнула поразительные различия во время ответа. Например, в API Text-embedding-3-Small в OpenAI среднее время отклика для удара кэша составило приблизительно 0,1 секунды, тогда как кэш приводит к задержкам до 0,5 секунды. Исследователи определили, что уязвимости по распределению кеша могут позволить злоумышленникам достичь почти идеальной точности в различении кэшированных и не кэшированных подсказок. Их статистические тесты дали очень значительные значения р, часто ниже 10⁻⁸, что указывает на сильную вероятность кэширования поведения. Более того, они обнаружили, что во многих случаях одного повторного запроса было достаточным для запуска кэширования, причем OpenAI и Azure требуют до 25 последовательных запросов, прежде чем станет очевидным поведение кэширования. Эти результаты показывают, что поставщики API могут использовать распределенные системы кэширования, где подсказки не хранятся непосредственно на всех серверах, но становятся кэшированными после повторного использования.
Ключевые выводы из исследования включают следующее:
- Запрашивает кэширование, ускоряет ответы, сохраняя ранее обработанные запросы, но он может раскрывать конфиденциальную информацию, когда кэши используются среди нескольких пользователей.
- Глобальное кэширование было обнаружено у 7 из 17 поставщиков API, что позволило злоумышленникам сделать вывод, используемые другими пользователями посредством вариаций времени.
- Некоторые поставщики API публично не раскрывают политики кэширования, что означает, что пользователи могут не знать, что другие хранят и получают доступ к своим входным данным.
- В исследовании выявили расхождения времени отклика, когда кэш попадает в среднюю 0,1 секунды, а кэш пропускает 0,5 секунды, обеспечивая измеримое доказательство кэширования.
- Статистическая структура аудита обнаружила кэширование с высокой точностью, причем P-значения часто падают ниже 10⁻⁸, что подтверждает наличие систематического кэширования для нескольких поставщиков.
- Модель Text-embedding-3 в Openai была обнаружена как трансформатор только для декодера, ранее нераскрытую деталь, выведенную из поведения кэширования.
- Некоторые поставщики API исправляли уязвимости после раскрытия, но другие еще не решили эту проблему, что указывает на необходимость более строгих отраслевых стандартов.
- Стратегии смягчения включают ограничение кэширования для отдельных пользователей, рандомизацию задержек ответа для предотвращения вывода времени и обеспечение большей прозрачности в политике кэширования.
Проверить бумага и GitHub PageПолем Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Сана Хасан, стажер консалтинга в Marktechpost и студент с двойной степенью в IIT Madras, увлечена применением технологий и искусственного интеллекта для решения реальных проблем. С большим интересом к решению практических проблем, он привносит новую перспективу для пересечения ИИ и реальных решений.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)

