


大型語言模型(LLM)超出了基本的自然語言處理,以解決複雜的解決問題的任務。雖然擴展模型的規模,數據和計算使得在較大模型中可以發展更豐富的內部表示和新興功能,但其推理能力仍在挑戰。當前的方法論很難在整個複雜的問題解決過程中保持連貫性,尤其是在需要結構化思維的領域。困難在於優化經過思考的推理並確保各種任務之間的穩定表現,尤其是在具有挑戰性的數學問題上。儘管最近的進步已經顯示出希望,但研究人員面臨著有效利用計算資源來提高推理能力而無需犧牲效率的持續挑戰。開發可以系統地增強解決問題同時維持可伸縮性的方法仍然是提高LLM功能的核心問題。
研究人員探索了各種方法來增強LLM中的推理。測試時間計算縮放與加強學習的結合已成為一個有前途的方向,模型使用推理令牌來指導經過思考的過程。研究已經調查了模型是否傾向於過度思考或思考,從而檢查了推理步長,輸入長度和常見故障模式。先前的工作重點是通過在學習階段進行明確的經過經過思考的培訓以及在推理時進行迭代的完善來優化數學推理。儘管這些方法已顯示出基準的改進,但有關不同模型功能的令牌使用效率以及推理長度和性能之間的關係仍然存在問題。這些問題對於理解如何設計更有效的推理系統至關重要。
這項研究使用OMNI-MATH數據集來基準跨不同模型變體的推理能力。該數據集在奧林匹亞級別提供了嚴格的評估框架,以解決現有基準(如GSM8K和數學)的局限性,而當前LLMS達到了高準確率。 Omni-Math的綜合組織分為10個難度級別的33個子域,這可以對數學推理能力進行細微的評估。 Omni-Gudge的可用性有助於自動評估模型生成的答案。儘管MMLU,AI2推理和GPQA等其他基準涵蓋了不同的推理域,並且編碼基準強調了明確獎勵模型的重要性,但Omni-Math的結構使其特別適合分析模型能力跨模型功能之間的推理長度和性能之間的關係。
該研究使用OMNI-MATH基準評估了模型性能,該基准在六個領域和四個難度層中具有4,428個奧林匹克級數學問題。結果表明,經過測試的模型之間的性能層次明確:GPT-4O在學科之間達到了20-30%的精度,顯著落後於推理模型。 O1-Mini達到40-60%; O3-Mini(M)在所有類別中至少達到50%;與O3-Mini(M)相比,O3-Mini(H)提高了約4%,代數和微積分的精度超過80%。令牌用法分析表明,相對令牌的消費隨著所有模型的問題難度而增加,而離散的數學尤其密集。重要的是,O3-Mini(M)不使用比O1-Mini更多的推理令牌來實現卓越的性能,從而提出了更有效的推理。同樣,隨著所有模型的令牌使用的增加,精度降低,其效果對於O1-Mini(每1000個令牌下降3.16%)最強,而O3-Mini(H)(H)最弱(降低了0.81%)。這表明雖然O3-Mini(H)表現出略有表現的性能,但其計算成本大大提高。
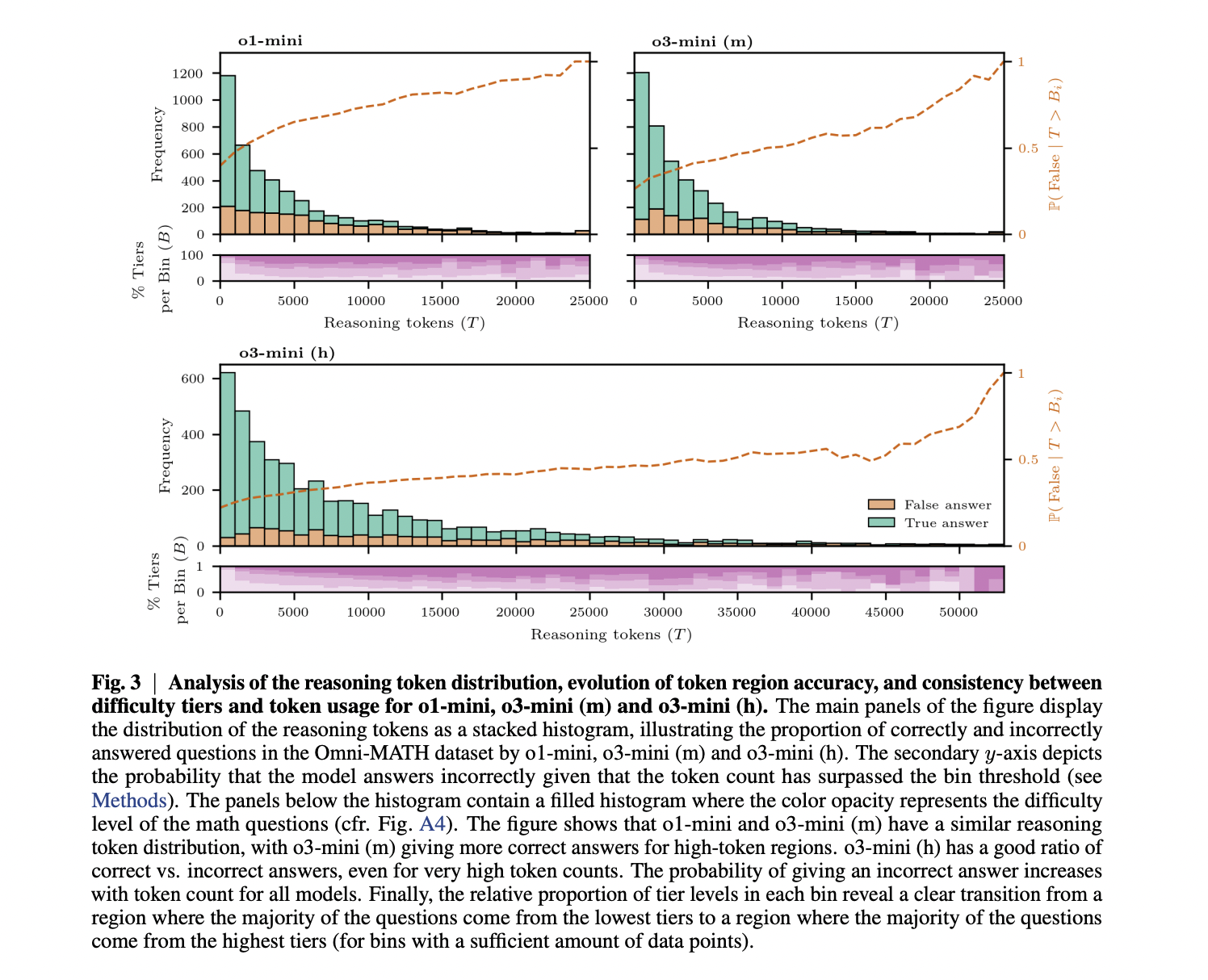
該研究產生了有關語言模型推理的兩個重要發現。首先,更有能力的模型不一定需要更長的推理鏈才能達到更高的精度,如O1-Mini和O3-Mini(M)之間的比較所證明。其次,雖然準確性通常會隨著較長的思想鏈流程而下降,但這種效果在更高級的模型中會降低,強調“思考更加努力”與“思考更長的思維”有所不同。這種準確性下降可能會發生,因為模型傾向於對他們難以解決的問題更廣泛地推理,或者因為更長的推理鏈本質上會增加錯誤的可能性。這些發現對模型部署具有實際含義,這表明約束思想鍊長度對較弱的推理模型比對強大的模型更有益,因為後者即使通過擴展的推理也保持了合理的準確性。未來的工作可能會從具有參考推理模板的數學基準中受益,以進一步探索這些動態。
查看 紙。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題
Asjad是Marktechpost的實習顧問。他正在Kharagpur印度理工學院的機械工程學領域掌握B.Tech。 Asjad是一種機器學習和深度學習愛好者,他一直在研究醫療保健中機器學習的應用。
🚨推薦開源AI平台:“ Intellagent是一個開源的多代理框架,可評估複雜的對話AI系統”(已晉升)


