


Создание песен Из текста сложно, потому что он включает в себя создание вокала и инструментальную музыку вместе. Песни уникальны, поскольку они сочетают в себе тексты и мелодии для выражения эмоций, что делает процесс более сложным, чем генерирование речи или инструментальной музыки. Задача усиливается недостаточной доступностью качественных данных с открытым исходным кодом, которые сдерживают исследования и разработки в этом районе. Некоторые подходы включают в себя несколько шагов, с вокалом, сгенерированным в первую очередь, и аккомпанемент, генерируемый отдельно. Такой метод препятствует процессу обучения и прогнозирования и уменьшает контроль финальной песни. Основная задача заключается в том, может ли одношабельная модель упростить этот процесс при сохранении качества и гибкости.
В настоящее время модели генерации текста до музыки используют описательный текст для создания музыки, но большинство методов пытаются генерировать реалистичный вокал. Модели на основе трансформамеров обрабатывают аудио как дискретные токены, а диффузионные модели создают высококачественную инструментальную музыку, но оба подхода сталкиваются с проблемами вокального поколения. Generation Song, которая сочетает в себе вокал с инструментальной музыкой, опирается на многоэтапные методы, как Мужичный автоматВ Мелодисти МелодилмПолем Эти методы производят вокал и сопровождение независимо, поэтому процесс сложный и трудно управлять. Без общей стратегии гибкость ограничена, а неэффективность в обучении и выводе повышается.
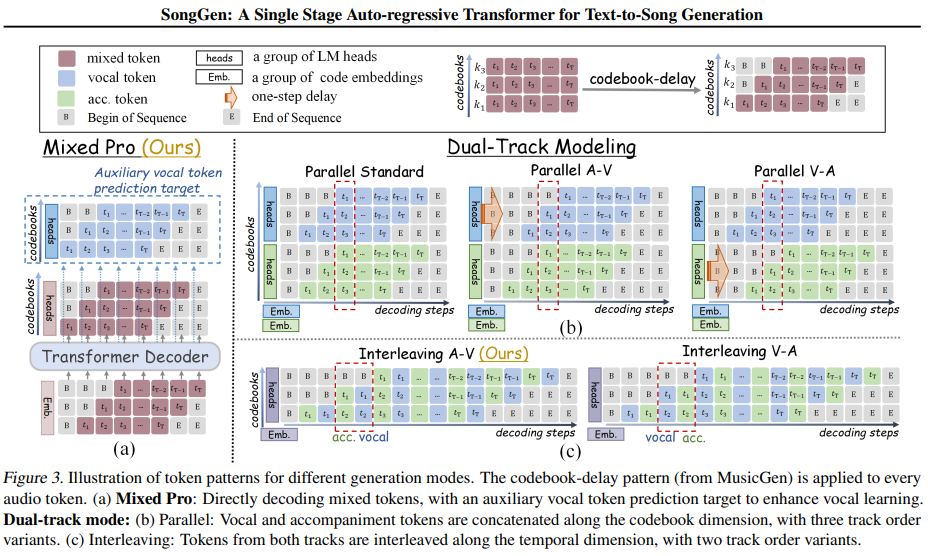
Чтобы сгенерировать песню из описаний текста, текстов и необязательного эталонного голоса, исследователи предложили Сонггенавторегрессивный трансформатор с интегрированным нейронным аудиокодеком. Модель предсказывает последовательности звука, которые синтезируются в песни. Сонгген поддерживает два режима генерации: смешанный режим и Двойной режимПолем В Смешанный режимX.-Кодек Кодирует необработанное аудио в дискретные жетоны, с потерей обучения, подчеркивая более ранние кодовые книги для улучшения ясности вокала. Вариант, смешанный профессионал, вводит вспомогательную потерю вокала для повышения их качества. Режим двойного трека отдельно генерирует вокал и сопровождающий, синхронизируя их с помощью параллельных или чередующихся паттернов. Параллельный режим выравнивает токенов за кадром, в то время как режим интерреляции усиливает взаимодействие между вокалом и сопровождения по слоям.
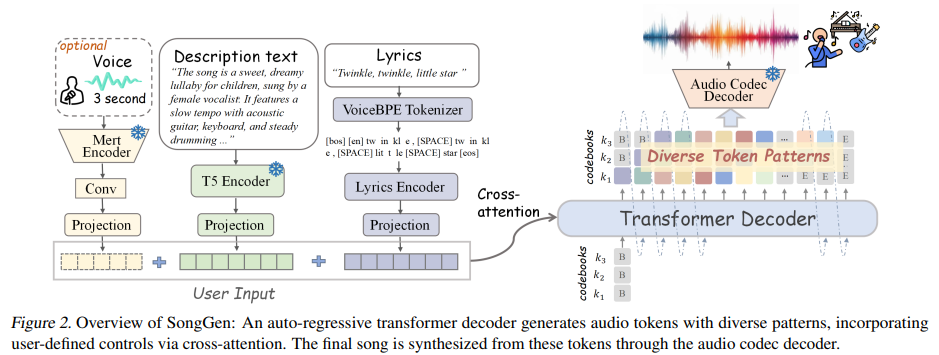
Для кондиционирования тексты обрабатываются с помощью VoiceBpe Tokenizerголосовые функции извлекаются через замороженную МЕРТ ЭНКОДЕРи текстовые атрибуты кодируются с использованием Flan-T5Полем Эти встраиваемые руководство по генерации песен через перекрестное внимание. Из-за отсутствия общедоступных наборов данных текста в песню, автоматизированные процессы трубопровода 8000 часов звука из нескольких источников, обеспечивая качественные данные посредством стратегий фильтрации.
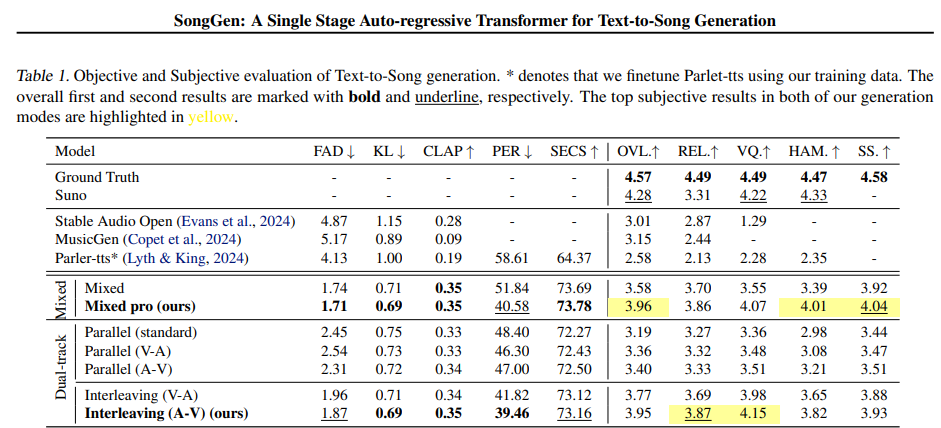
Исследователи оценили SongGen со стабильным Audio Open, MusicGen, Parler-TTS и SUNO для поколения текста к песне. MusicGen создал только инструментальную музыку, в то время как стабильный звук открылся, созданный неясные вокальные звуки, а также настраивать Parler-TTS для пения оказался неэффективным. Несмотря на использование только 2000 Часы маркированных данных Songgen превзошли эти модели в отношении актуальности текста и вокального управления. Среди его режимов «Смешанный профессионалПодход усилился вокальное качество (Ведущий) и Частота ошибок в фонеме (PER)в то время как метод с двумя треками «Интерривация (AV)» преуспел в качеством вокала, но имел немного более низкую гармонию (HAM). Анализ внимания показал, что SongGen эффективно захватил музыкальные структуры. Модель сохраняла согласованность с незначительными снижениями производительности даже без эталонного голоса. Исследования абляции подтвердили, что Высококачественная тонкая настройка (HQFT), Учебное обучение (CL) и Voicebpe-На основе лирической токенизации улучшает стабильность и точность.
В заключение, предложенная модель упростила генерацию текста к песне, введя одноступенчатый, авторегрессивный трансформатор, который поддерживал смешанные и двойные режимы, демонстрируя сильную производительность. Его функция с открытым исходным кодом сделала его более доступным, чтобы новички и эксперты могли создавать музыку с точным управлением голосом и компонентами прибора. Тем не менее, способность модели имитировать голоса является этически проблематичной, призывая к защите от злоупотреблений. В качестве основополагающей работы в управляемом поколении текста к песне SongGen может служить базовой линией для будущих исследований, направляя улучшения качества звука, лирического выравнивания и выразительного синтеза пения при решении этических и правовых задач.
Проверить Технические детали и страница GitHub. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 80K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Divyesh – стажер консалтинга в Marktechpost. Он преследует BTECH в области сельского хозяйства и продовольственной инженерии от Индийского технологического института, Харагпур. Он является любителем науки о данных и машинного обучения, который хочет интегрировать эти ведущие технологии в сельскохозяйственную область и решить проблемы.
🚨 Рекомендуемая платформа искусственного интеллекта с открытым исходным кодом: «Intellagent-это многоагентная структура с открытым исходным кодом для оценки сложной разговорной системы ИИ» (PROMOTED)


