


通過迭代deNoing產生復雜的軌跡,在長馬計劃中擴散模型有希望。但是,他們通過測試時間進行更多計算來提高性能的能力很小。與蒙特卡洛樹搜索相比,其力量在於利用其他計算資源,基於典型的擴散計劃者可能會因降低剝離步驟或產生其他軌蹟的回報而受到損失。此外,這些模型在有效的探索探索折衷方面存在困難,從而在復雜的環境中導致次優性能。傳統的蒙特卡洛樹搜索方法雖然具有良好的迭代性改進,但在大型連續的動作空間中具有很高的計算複雜性。最大的挑戰是構建一個計劃範式,該範式利用擴散模型的生成靈活性,同時結合了蒙特卡洛樹搜索的結構化搜索益處,從而在長途問題中實現了有效且可擴展的決策。
基於最先進的擴散計劃者(例如擴散器)以整體方式生成完整的軌跡,從中避免了前向動力學模型。即使這種方法提高了軌蹟的一致性,但它缺乏結構化的搜索方法,因此不適合增強次優計劃。其他方法,例如擴散器隨機搜索和蒙特卡洛指導,試圖利用迭代採樣。但是,他們無法系統地丟棄無主張的軌跡。相比之下,蒙特卡洛樹搜索利用了更多的計算資源,但是它對遠期模型的依賴使其不適合廣泛的,連續的動作空間。這些局限性在可擴展和靈活的計劃中造成了較大的差距,尤其是在具有長途軌跡優化的域中。
為了彌補這些缺點,蒙特卡洛樹擴散將樹搜索與基於擴散的計劃相結合,基本上將蒙特卡洛樹搜索的系統搜索與擴散模型的生成力量相結合。該方法沒有將其視為獨立的過程,而是將其重新構想在樹結構的推出框架中,從而允許迭代評估,修剪和細化部分DeNocied計劃。該框架引入了三個關鍵創新。首先,將降解過程重新構想為基於樹的擴展機制,該機制允許在保持軌跡相干性的同時進行結構化搜索。其次,它通過指導時間表應用自適應探索 – 探索 – 探索權衡,從而適應軌蹟的完善。第三,而不是使用完整的推出,而是使用快速和近似的denoising方法來快速評估軌跡質量,從而減少計算開銷。這些改進提供了可擴展且靈活的計劃機制,隨著計算資源的增加,有望提高測試時間的性能。
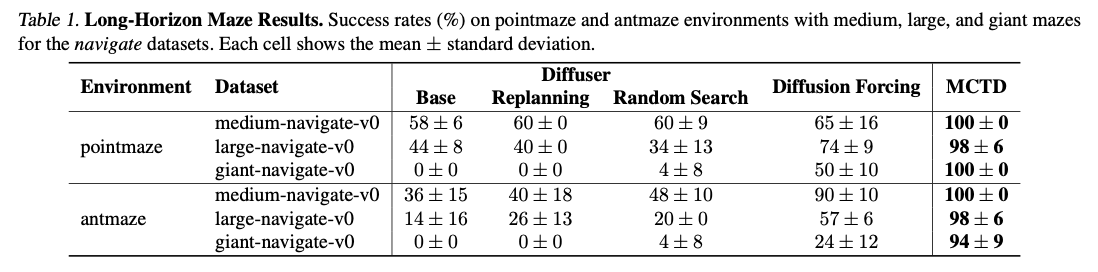
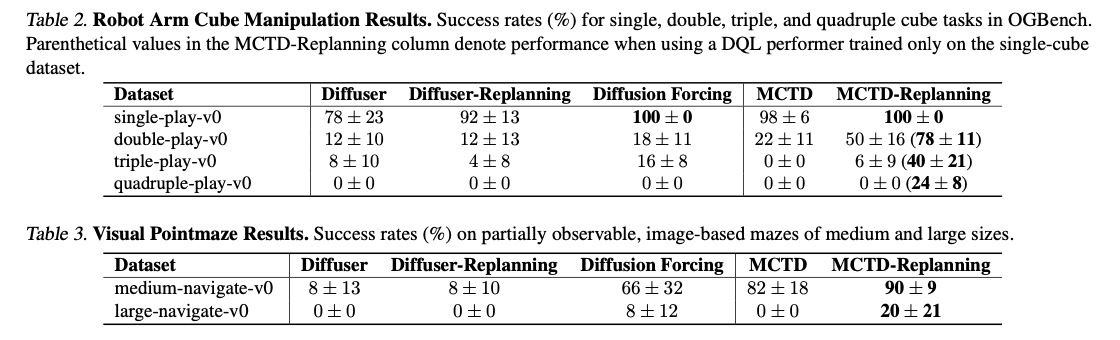
蒙特卡洛樹的擴散遵循蒙特卡洛樹搜索的四個階段 – 選擇,擴展,模擬和反向傳播 – 在擴散框架中。選擇階段根據上置信度結合標準選擇最佳子計劃。擴展階段通過擴散模型生成新的子計劃,每個步驟都通過目標引導的改進來通過隨機採樣和剝削動態平衡探索。模擬是通過有效的Jumpy DeNoing算法進行的,以幾乎沒有計算成本來評估軌蹟的質量。然後,向後傳播將評估的軌跡從樹上返回獎勵信號,從而更新節點值並動態調整指導時間表。該框架的效率是使用OGBENCH評估的,OGBench是一個脫機目標條件的強化學習基準,涉及迷宮導航,機器人立方體操作和基於圖像的計劃等任務。選擇範圍在500到1000個步驟之間選擇,從而可以將其效率與基線模型進行全面比較,例如擴散器,擴散器重新計劃和擴散強迫。

蒙特卡洛樹擴散在一系列計劃任務上展示了最先進的性能,表現優於基於板擴散和基於搜索的基線。在長跑迷宮導航上,它顯示出接近完美的成功率,超過擴散器和基於搜索的隨機方法,這些方法無法擴展。在機器人立方體操作上,它可以很好地管理多對象的相互作用,從而防止了使單通行計劃者受苦的軌跡糾纏。對於部分可觀察性,基於圖像的導航,它保留了高成功率,即使沒有直接狀態知識,它也可以平衡探索和剝削的能力。最值得注意的是,這種方法可以通過額外的測試時間計算來很好地擴展,並將計劃作為標準擴散技術平穩,這說明了其在生成模型中的結構化搜索中的力量。
由蒙特卡洛樹擴散啟用的結構化搜索和生成軌跡計劃的組合可以在長期框架問題中進行可擴展和高質量的決策。基於樹木的脫氧,自適應指導時間表和加速模擬的速度明顯優於基於擴散的計劃者。它通過更多的計算資源輕鬆擴展的能力使其成為用於機器人技術,自主決策和戰略規劃的可行候選人。自適應計算分配的改進,元學習以更好的搜索以及自我監督的獎勵塑造可以使其更可擴展和適用於更複雜的環境。
查看 紙。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 80k+ ml子列數。
🚨 推薦的閱讀-LG AI研究釋放Nexus:一個高級系統集成代理AI系統和數據合規性標準,以解決AI數據集中的法律問題
Aswin AK是Marktechpost的諮詢實習生。他正在印度科技學院哈拉格布爾(Kharagpur)攻讀雙重學位。他對數據科學和機器學習充滿熱情,為解決現實生活中的跨域挑戰帶來了強大的學術背景和動手經驗。
🚨推薦開源AI平台:“ Intellagent是一個開源的多代理框架,可評估複雜的對話AI系統”(已晉升)


