

इष्टतम ptimizing बड़े -स्केल भाषा मॉडल उन्नत प्रशिक्षण तकनीकों की मांग करते हैं जो उच्च प्रदर्शन को बनाए रखते हुए गणना की लागत को कम करते हैं। प्रशिक्षण दक्षता का निर्धारण करने के लिए इष्टतम ptimization एल्गोरिदम महत्वपूर्ण हैं, विशेष रूप से व्यापक आयामों द्वारा गणना किए गए बड़े मॉडल में। जबकि ADMW जैसे इष्टतम ptimizers को व्यापक रूप से अपनाया गया है, उन्हें अक्सर सावधानीपूर्वक हाइपरपेरमीटर ट्यूनिंग और उच्च गणना संसाधनों की आवश्यकता होती है। एक अधिक कुशल विकल्प ढूंढना जो बड़े -स्केल मॉडल विकास को आगे बढ़ाने के लिए गणना आवश्यकताओं को कम करते हुए प्रशिक्षण स्थिरता की गारंटी देता है।
बड़े -स्केल मॉडल को प्रशिक्षण की चुनौती बढ़ी हुई गणना और प्रभावी पैरामीटर अपडेट की आवश्यकता से है। कई मौजूदा इष्टतम ptimizers बड़े मॉडल को स्केल करते समय अनुचित दिखाते हैं, अक्सर प्रशिक्षण समय का विस्तार करने के लिए लगातार समायोजन की आवश्यकता होती है। असंगत मॉडल अपडेट जैसे स्थिरता के मुद्दे प्रदर्शन को अधिक कम कर सकते हैं। अत्यधिक गणना या ट्यूनिंग प्रयासों की शक्ति को बढ़ाए बिना मजबूत प्रशिक्षण गतिशीलता सुनिश्चित करके दक्षता और एक व्यावहारिक निपटान को बढ़ाकर इन चुनौतियों पर विचार किया जाना चाहिए।
एडम और एडम जैसे मौजूदा इष्टतम ptimizers मॉडल के प्रदर्शन को बेहतर बनाने के लिए अनुकूली शिक्षा दर और वजन क्षय पर निर्भर करते हैं। जबकि इन विधियों ने विभिन्न अनुप्रयोगों में मजबूत परिणाम दिखाए हैं, वे मॉडल के पैमाने के रूप में कम प्रभावी हो जाते हैं। उनकी गणना की मांग काफी बढ़ जाती है, जिससे वे बड़े -स्केल प्रशिक्षण के लिए अक्षम हो जाते हैं। शोधकर्ता वैकल्पिक ऑप्टिमेंट ptimizers की जांच कर रहे हैं जो बेहतर संचालन और दक्षता प्रदान करते हैं, जो स्थिर और स्केलेबल परिणाम प्राप्त करते समय व्यापक हाइपरपेरमेटर ट्यूनिंग की आवश्यकता को समाप्त करते हैं।
मूनशॉट एआई और यूसीएलए के शोधकर्ताओं ने मुन्न को पेश किया, जो एक इष्टतम ptimizer है जो बड़े -स्केल प्रशिक्षण में मौजूदा तरीकों की सीमाओं को खत्म करने के लिए विकसित किया गया है। प्रारंभ में छोटे -छोटे मॉडल डेलो में प्रभावी साबित हुआ, म्यून ने स्केलिंग में चुनौतियों का सामना किया। इस पर विचार करने के लिए, शोधकर्ताओं ने दो मुख्य तकनीकों को लागू किया: विभिन्न आयामों में समान समायोजन सुनिश्चित करने के लिए स्थिरता और निरंतर रूट माध्य वर्ग (आरएमएस) अपडेट को बढ़ाया। ये संवर्द्धन MUN को व्यापक हाइपरपेमेटर ट्यूनिंग की आवश्यकता के बिना कुशलता से संचालित करने की अनुमति देते हैं, जिससे यह CS के बाहर बड़े -स्केल मॉडल को प्रशिक्षित करने के लिए एक शक्तिशाली विकल्प बन जाता है।
इन प्रगति के मद्देनजर, शोधकर्ताओं ने 3 बी और 16 बी आयाम कॉन्फ़िगरेशन में चांदनी, मिक्स-एफ-विशेषज्ञों (एमओई) मॉडल की शुरुआत की। 7.7 ट्रिलियन टोकन के साथ प्रशिक्षित, चंद्रमा का लाभ कम्प्यूटेशनल लागत को कम करते हुए चांदनी के प्रभाव को चांदनी के प्रभाव को बढ़ाने का लाभ है। Mune के वितरित संस्करण को शून्य -1 -स्टाइल ऑप्टिमाइज़ेशन का उपयोग करके भी विकसित किया गया था, जो मेमोरी दक्षता में सुधार और संचार ओवरहेड को कम करता है। इन शुद्धि के परिणामस्वरूप एक स्थिर प्रशिक्षण प्रक्रिया हुई, जिससे चांदनी को पिछले मॉडल की तुलना में काफी कम गणना लागत के साथ उच्च प्रदर्शन प्राप्त करने की अनुमति मिली।
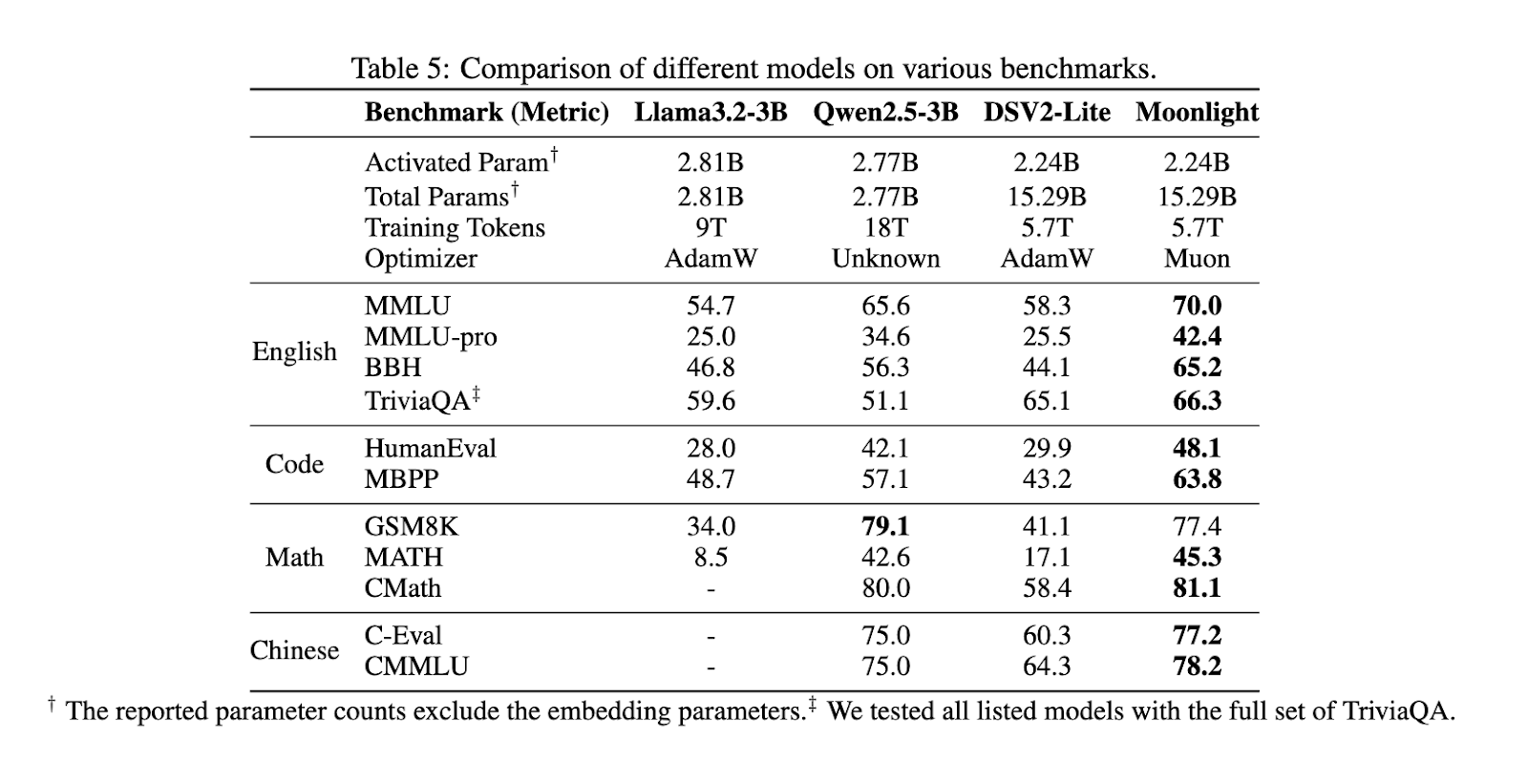
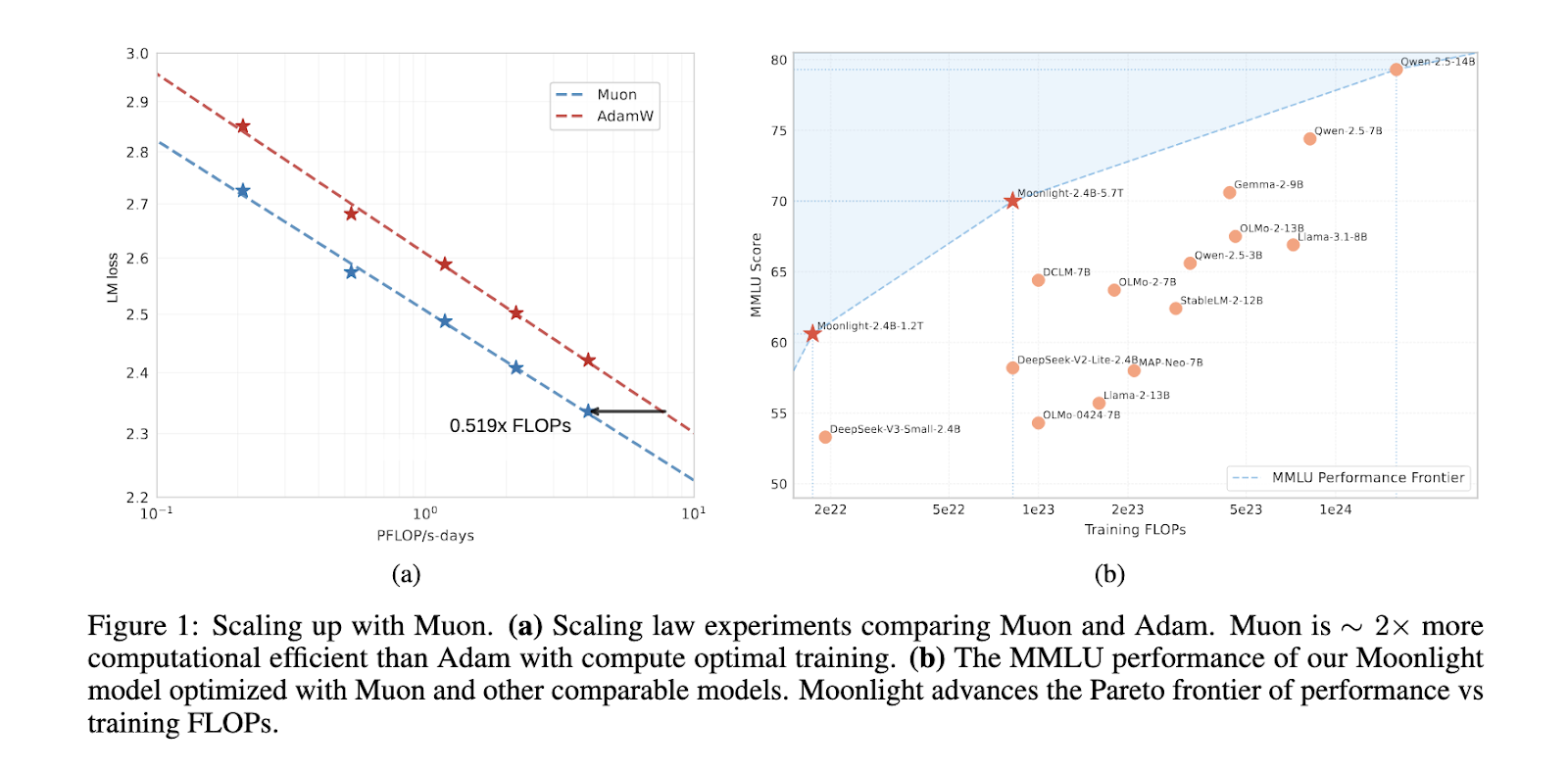
प्रदर्शनी मूल्यांकन से पता चलता है कि चांदनी लालामा तुलनात्मक पैमाने के मौजूदा आधुनिक मॉडल को बेहतर बनाती है, जिसमें 3-3B और QWN 2.5-3B शामिल हैं। स्केलिंग कानून ने खुलासा किया है कि नमूना-कुशल मुन एडम की तुलना में लगभग दोगुना है, जिससे प्रतिस्पर्धी परिणामों को बनाए रखने वाले प्रशिक्षण फ्लॉप में एक महत्वपूर्ण कमी को सक्षम किया जा सकता है। मूनलाइट कई बेंचमार्क में उत्तम प्रदर्शन करता है, MMLU में 70.0 को प्राप्त करता है, लालमा 54.75 पर 3-3B और 65.6 पर Qwen2.5-3b को पार कर रहा है। मूनलाइट ने MMLU-PRO में 42.4 और BBH में एक अधिक विशेष बेंचमार्क में 65.2 को अपने उन्नत प्रभाव को उजागर किया। मॉडल ने ट्रिविका में 66..3 के स्कोर के साथ मजबूत परिणाम भी दिखाए, जिसने सभी तुलनीय मॉडल को पार कर लिया।
मूनलाइट ने ह्यूमनवाल में 48.1 और कोड-संबंधित कार्यों में एमबीपीपी में 63.8 प्राप्त किया, एक ही आयाम के तराजू पर अन्य मॉडलों का विस्तार किया। गणितीय तर्क में, उन्होंने GSM8K में 77.4 और गणित में 45.3 बनाए, समस्याओं के साथ सबसे अच्छी समस्याओं को दिखाया। मूनलाइट ने चीनी भाषा के कार्यों में भी अच्छा प्रदर्शन किया, C-val.2 77.1 और CMMLU.2 78.1 में, बहुभाषी प्रक्रिया में इसकी प्रभावशीलता की स्थापना की। विभिन्न बेंचमार्क में मॉडल का मजबूत प्रदर्शन इसकी मजबूत सामान्यीकरण क्षमता को इंगित करता है जबकि गणना लागत काफी कम हो जाती है।
मुन नवाचारों ने बड़े मॉडलों को प्रशिक्षित करने के लिए महत्वपूर्ण स्केलेबिलिटी चुनौतियों को समाप्त किया। वजन क्षय और निरंतर आरएमएस अपडेट को शामिल करके, शोधकर्ताओं ने स्थिरता और दक्षता में वृद्धि की, जिससे चांदनी को प्रशिक्षण लागत को कम करते हुए ऑपरेशन की सीमाओं को स्थानांतरित करने में सक्षम बनाया। ये प्रगति एडम-आधारित इष्टतम ptimizers के लिए एक अद्भुत विकल्प के रूप में MUN को मजबूत करती हैं, जो विस्तारित ट्यूनिंग की आवश्यकता के बिना एक क्लासिक दक्षता प्रदान करती है। चंद्रमा और चांदनी का खुला स्रोत समुदाय का अधिक समर्थन करता है, बड़े -स्केल मॉडल के लिए कुशल प्रशिक्षण विधियों की अधिक खोज को बढ़ावा देता है।
जाँच करना यहाँ मॉडल। इस शोध के लिए सभी क्रेडिट इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एकीकृत करने वाला एक उन्नत प्रणाली
निखिल मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह खड़गपुर में भारतीय संगठन की प्रौद्योगिकी में सामग्री में दोहरी डिग्री प्राप्त कर रहा है। निखिल एआई/एमएल उत्साही है जो हमेशा बायोमेट्रियल और बायोमेडिकल विगल्स जैसे क्षेत्रों में आवेदन पर शोध करता है। भौतिक अभिव्यक्ति में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति और योगदान की संभावना की तलाश कर रहा है।
🚨 अनुशंसित ओपन-सीरस एआई प्लेटफॉर्म: ‘इंटेलिजेंट एक ओपन सोर्स मल्टी-एजेंट फ्रेमवर्क है जो कॉम्प्लेक्स वार्तालाप एआई सिस्टम का मूल्यांकन करता है’ (ईडी)

