परिकल्पना सत्यापन मौलिक है। जानिक खोज, निर्णय लेने और सूचना अधिग्रहण मौलिक है। जीवों, घटनाओं, अर्थशास्त्र या नीति के निर्माण में, शोधकर्ता अपने निष्कर्षों का मार्गदर्शन करने के लिए परिकल्पनाओं पर परीक्षण पर निर्भर करते हैं। परंपरागत रूप से, इस प्रक्रिया में परिकल्पना की वैधता निर्धारित करने के लिए प्रयोगों को डिजाइन करना, डेटा एकत्र करना और परिणामों का विश्लेषण शामिल है। हालांकि, एलएलएम के आगमन के साथ उत्पन्न परिकल्पनाओं का अनुपात नाटकीय रूप से बढ़ गया है। जब ये एआई-प्रोपेल्ड परिकल्पना उपन्यास अंतर्दृष्टि देते हैं, तो उनकी तर्कसंगतता व्यापक रूप से भिन्न होती है, जिससे मैनुअल विश्वास अव्यवहारिक हो जाता है। इस प्रकार, परिकल्पना विश्वास में ऑटो टोमेशन यह सुनिश्चित करने के लिए एक आवश्यक चुनौती बन गया है कि केवल सख्त परिकल्पना भविष्य के अनुसंधान को निर्देशित करती है।
परिकल्पना विश्वास में मुख्य चुनौती यह है कि कई वास्तविक दुनिया की परिकल्पनाएं अमूर्त हैं और सीधे मापा नहीं गया है। उदाहरण के लिए, यह कहना बहुत व्यापक है कि एक विशेष जीन बीमारी का कारण बनता है और इसे परीक्षण योग्य प्रभावों में अनुवादित करने की आवश्यकता होती है। एलएलएम के उद्भव ने इस मुद्दे को तेज कर दिया है, क्योंकि ये मॉडल एक अभूतपूर्व पैमाने पर परिकल्पनाओं का उत्पादन करते हैं, जिनमें से कई गलत या भ्रामक हो सकते हैं। मौजूदा सत्यापन विधियां गति को बनाए रखने के लिए संघर्ष करती हैं, जिससे यह निर्धारित करना मुश्किल हो जाता है कि आगे की जांच के लिए कौन सी परिकल्पना उपयुक्त हैं। इसके अलावा, संख्यात्मक कठोरता को अक्सर छेड़छाड़ की जाती है, जिससे गलत जांच होती है जो गलत तरीके से अनुसंधान और नीतिगत प्रयासों को इंगित कर सकती है।
परिकल्पना सत्यापन के पारंपरिक तरीकों में एक संख्यात्मक परीक्षण ढांचा शामिल है जैसे कि पी-वैल्यू-आधारित परिकल्पना परीक्षण और विदर का संयुक्त परीक्षण। हालांकि, ये दृष्टिकोण झूठे प्रयोगों को डिजाइन करने और परिणामों की व्याख्या करने के लिए मानवीय हस्तक्षेप पर निर्भर करते हैं। कुछ स्वचालित दृष्टिकोण मौजूद हैं, लेकिन वे अक्सर प्रकार -1 त्रुटियों (झूठी धन) को नियंत्रित करने के तरीकों की कमी करते हैं और यह सुनिश्चित करते हैं कि निष्कर्ष सांख्यिकीय रूप से विश्वसनीय हैं। कई एआई-संचालित सत्यापन उपकरण व्यवस्थित रूप से कठोर नुकसान से परिकल्पना को चुनौती नहीं देते हैं, जिससे भ्रामक निष्कर्षों का खतरा बढ़ जाता है। नतीजतन, परिकल्पना मान्यता प्रक्रिया को प्रभावी ढंग से स्वचालित करने के लिए एक स्केलेबल और सांख्यिकीय ध्वनि समाधान की आवश्यकता होती है।
स्टैनफोर्ड विश्वविद्यालय और हार्वर्ड विश्वविद्यालय के शोधकर्ताओं ने पेश किया ताँबाएक एजेंसी ढांचा जो एलएलएम-आधारित एजेंटों के साथ कठोर संख्यात्मक सिद्धांतों को एकीकृत करके परिकल्पना सत्यापन की प्रक्रिया को स्वचालित करता है। फ्रेमवर्क व्यवस्थित रूप से झूठे पॉपर के सिद्धांत को लागू करता है, जो परिकल्पना को साबित करने के बजाय अस्वीकृति पर जोर देता है। पॉपर दो विशेष एआई -ऑपरेटेड एजेंटों को नियुक्त करता है:
- प्रयोग डिजाइन एजेंट जो कदाचार प्रयोग करता है
- प्रयोग निष्पादन एजेंट जो उन पर लागू होता है
प्रत्येक परिकल्पना को विशेष, परीक्षण योग्य उप-हेपेटिसिस में विभाजित किया गया है और कदाचार के प्रयोगों के अधीन है। पॉपर यह सुनिश्चित करता है कि केवल अच्छी तरह से -supported परिकल्पनाएं वैधता प्रक्रिया में सुधार और संचित साक्ष्य में निरंतर सुधार करके आगे बढ़े हैं। पारंपरिक तरीकों के विपरीत, पॉपर गतिशील रूप से पिछले परिणामों के आधार पर अपने दृष्टिकोण के लिए अनुकूलित करता है, संख्यात्मक अखंडता को बनाए रखते हुए दक्षता में काफी सुधार करता है।
पॉपर एक दोहराव प्रक्रिया के माध्यम से कार्य करता है जिसमें गलत प्रयोग अनुक्रमित की परिकल्पना का परीक्षण करते हैं। प्रयोग डिजाइन किसी दिए गए परिकल्पना के मापा प्रभावों की पहचान करके इन प्रयोगों का उत्पादन करते हैं। प्रयोग निष्पादन एजेंट तब सांख्यिकीय विधियों, सिमुलेशन और वास्तविक दुनिया के डेटा संग्रह का उपयोग करके प्रस्तावित प्रयोगों का संचालन करता है। पॉपर की विधि की कुंजी यह है कि टाइप -1 त्रुटि दरों को सख्ती से नियंत्रित करने की क्षमता है, यह सुनिश्चित करना कि झूठी धन कम हो गया है। पारंपरिक दृष्टिकोणों के विपरीत, जो अलगाव में पी-मूल्यों का इलाज करता है, पॉपर एक क्रमिक परीक्षण संरचना प्रस्तुत करता है जिसमें व्यक्तिगत पी-मानों को ई-मानों में परिवर्तित किया जाता है, जिससे एक संख्यात्मक मानदंड त्रुटि नियंत्रण को बनाए रखते हुए लगातार साक्ष्य संचय की अनुमति मिलती है। यह अनुकूली दृष्टिकोण प्रणाली को गतिशील रूप से अपनी परिकल्पना की मरम्मत करने में सक्षम बनाता है, जिससे झूठे निष्कर्ष तक पहुंचने की संभावना कम हो जाती है। फ्रेमवर्क का लचीलापन इसे मौजूदा डेटासेट के साथ काम करने, नए सिमुलेशन करने या लाइव डेटा स्रोतों से संपर्क करने की अनुमति देता है, जिससे यह शाखाओं में बहुत बहुमुखी हो जाता है।
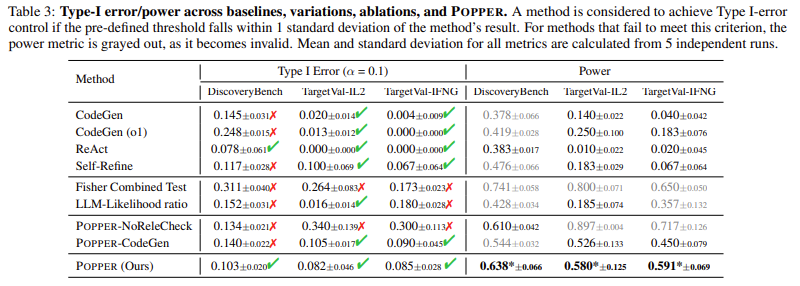
जीव विज्ञान, समाजशास्त्र और अर्थशास्त्र: पॉपर का मूल्यांकन छह डोमेन में किया गया था। सिस्टम को 86 मान्य परिकल्पनाओं के खिलाफ परीक्षण किया गया था, परिणामों ने सभी डेटासेट में 0.10 से नीचे एक प्रकार -1 त्रुटि दर दिखाई। पॉपर ने मौजूदा मान्यता विधियों की तुलना में संख्यात्मक शक्ति में एक महत्वपूर्ण सुधार दिखाया, जो फिशर के संयुक्त परीक्षण और संभाव्यता अनुपात मॉडल जैसी मानक तकनीकों को आगे बढ़ाता है। इंटरलुकिन -2 (IL -2) से संबंधित जैविक परिकल्पनाओं पर ध्यान केंद्रित करने वाले एक अध्ययन में, वैकल्पिक तरीकों की तुलना में पॉपर की दोहरावदार परीक्षण पद्धति में 3.17 बार सुधार हुआ है। इसके अलावा, नौ पीएचडी-स्तरीय गिनती ologists और बायोस्टेटिस्टों के विशेषज्ञ मूल्यांकन ने पाया कि प्रचार की परिकल्पना की सटीकता मानव शोधकर्ताओं के लिए तुलनीय है, लेकिन यह दसवें में पूरा हो गया था। अपनी अनुकूली परीक्षण संरचना के लाभ से, पॉपर ने जटिल परिकल्पना सत्यापन के लिए आवश्यक समय को 10 से कम कर दिया, जिससे यह काफी अधिक स्केलेबल और कुशल हो गया।
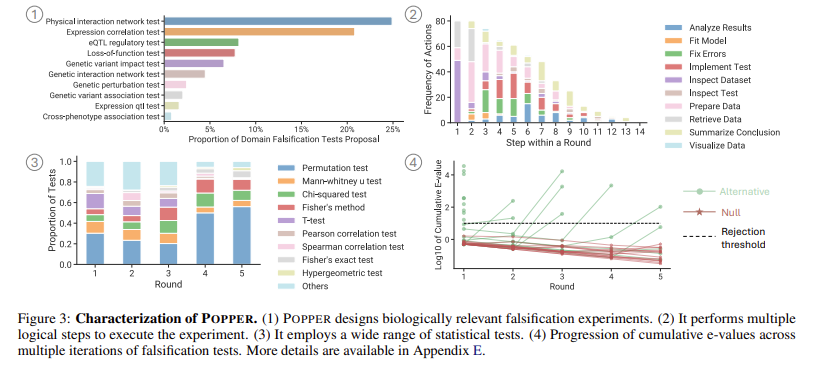
अनुसंधान के कुछ प्रमुख टेकवे में शामिल हैं:
- पॉपर एक स्केलेबल, एआई-संचालित समाधान प्रदान करता है जो परिकल्पनाओं के नुकसान को स्वचालित करता है, मैनुअल वर्कलोड को कम करता है और दक्षता में सुधार करता है।
- संरचना सख्त प्रकार -1 त्रुटि नियंत्रण बनाए रखती है, यह सुनिश्चित करती है कि झूठी धन 0.10 से नीचे रहे, सतर्कता अद्वितीय अखंडता के लिए महत्वपूर्ण है।
- मानव शोधकर्ताओं की तुलना में, पॉपर 10 गुना तेजी से परिकल्पना सत्यापन, दुश्मन को पूरा करता है।
- पारंपरिक पी-मान परीक्षणों के विपरीत, गतिशील परिकल्पना ई-मान का उपयोग करके परिकल्पना मान्यता में सुधार करते समय प्रयोगात्मक साक्ष्य के संग्रह की अनुमति देती है।
- छह विविध, जीवों, समाजशास्त्र और अर्थशास्त्र सहित। यह क्षेत्रों में परीक्षण किया गया, व्यापक रूप से लागू प्रदर्शनियां।
- नौ पीएचडी-स्तरीय दुश्मन वैज्ञानिकों द्वारा मूल्यांकन, पॉपर्स की सटीकता ने मान्यता पर खर्च किए गए समय को नाटकीय रूप से कम करते हुए मानव प्रदर्शन का मिलान किया।
- अधिक विश्वसनीय निष्कर्ष सुनिश्चित करके, सांख्यिकीय शक्ति पारंपरिक परिकल्पना मान्यता विधियों की तुलना में 3.17 गुना बेहतर हुई।
- पॉपर डेलो को गतिशील रूप से उत्पादन और मरम्मत करने के लिए बड़े -लैंगुएज मॉडल को एकीकृत करता है, जो इसे विकसित अनुसंधान आवश्यकताओं के लिए स्वीकार्य बनाता है।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 75 k+ ml सबमिटेड।
। अनुशंसित रीडिंग- एलजी एआई रिसर्च नेक्सस प्रकाशित करता है: एक उन्नत प्रणाली एआई एजेंट एआई सिस्टम और डेटा अनुपालन मानकों को एक एआई डेटासेट में कानूनी चिंताओं को खत्म करने के लिए
ASIF Razzaq एक दूरदर्शी उद्यमी और इंजीनियर के रूप में मार्केटएकपोस्ट मीडिया इंक के सीईओ हैं, ASIF सामाजिक अच्छे के लिए कृत्रिम बुद्धिमत्ता की संभावना को बढ़ाने के लिए प्रतिबद्ध है। उनका सबसे हालिया प्रयास आर्टिफिशियल इंटेलिजेंस मीडिया प्लेटफॉर्म, मार्कटेकपोस्ट का उद्घाटन है, जो मशीन लर्निंग की गहराई के लिए और कवरेज की गहराई के लिए गहरी सीखने की खबर के लिए है। यह तकनीकी रूप से ध्वनि है और एक बड़े दर्शकों द्वारा आसानी से समझ में आता है। प्लेटफ़ॉर्म में 2 मिलियन से अधिक मासिक दृश्य हैं, जो दर्शकों के बीच अपनी लोकप्रियता दिखाते हैं।