


Классификация целого слайда (WSI) в цифровой патологии представляет несколько критических проблем из -за огромного размера и иерархического характера WSI. WSI содержат миллиарды пикселей, и, следовательно, прямое наблюдение является вычислительно невозможным. Текущие стратегии, основанные на многочисленных экземплярах (MIL), эффективны, но значительно зависят от большого количества аннотированных данных на уровне сумки, приобретение которого является проблемным, особенно в случае редких заболеваний. Более того, текущие стратегии тесно основаны на понимании изображений и проблемах обобщения встреч из -за различий в распределении данных по больницам. Недавние улучшения в моделях языка зрения (VLMS) вводят лингвистическое предварительное предыдущее посредством крупномасштабной предварительной подготовки из пар изображений текста; Тем не менее, текущие стратегии не хватают в решении конкретной доменной идей, связанной с патологией. Более того, вычислительно дорогой характер предварительных моделей и их недостаточная адаптивность с иерархической характеристикой, специфичной для патологии, являются дополнительными неудачами. Важно преодолеть эти проблемы, чтобы способствовать диагностике рака на основе ИИ и правильной классификации WSI.
Методы на основе MIL, как правило, принимают трехступенчатый трубопровод: обрезка патча из WSI, извлечение элементов с предварительно обученным энкодером и уровня патча до агрегации объектов на уровне слайдов для прогнозирования. Хотя эти методы эффективны для связанных с патологией задач, таких как субтипирование рака и постановка, их зависимость от больших аннотированных наборов данных и чувствительности к распределению данных делает их менее практичными в использовании. Модели на основе VLM, такие как Clip и BiomedClip, пытаются нажать на языковые априоры, используя крупномасштабные пары изображений, собранные из онлайн-баз данных. Эти модели, однако, зависят от общих подсказок вручную текста, в которых отсутствует тонкость патологической диагностики. Кроме того, передача знаний от моделей на языке зрения на WSIS неэффективна благодаря иерархическому и крупномасштабному характеру WSI, который требует астрономических вычислительных затрат и точной настройки, специфичных для наборов данных.
Исследователи из Университета Xi’an Jiaotong, Tencent Youtu Lab и Института высокопроизводительных вычислительных компьютеров Сингапур представляют двойную модель с множественным языком, способная эффективно передавать модель на языке зрений в цифровую патологию с помощью описательных текстовых подсказок, специально разработанных специально разработанные специально для специально разработанных. Для патологии и обучения декодерам для изображений и текстовых ветвей. В отличие от общих подсказок на основе классов на основе традиционных методов языка зрения, модель использует замороженную большую языковую модель для генерации специфических для домена описаний при двух разрешениях. Низкомасштабная подсказка подчеркивает глобальные структуры опухолей, а высокомасштабная подсказка подчеркивает более тонкие сотовые детали с улучшенной дискриминацией признаков. Плачкодер с прототипом постепенно накапливает характеристики патчей, кластеризуя аналогичные патчи в обучаемые прототипы векторы, минимизируя вычислительную сложность и улучшая представление признаков. Текстовый декодер с контекстом дополнительно улучшает описания текста, используя контекст изображения с несколькими гранулированием, облегчая более эффективное слияние визуальных и текстовых методов.
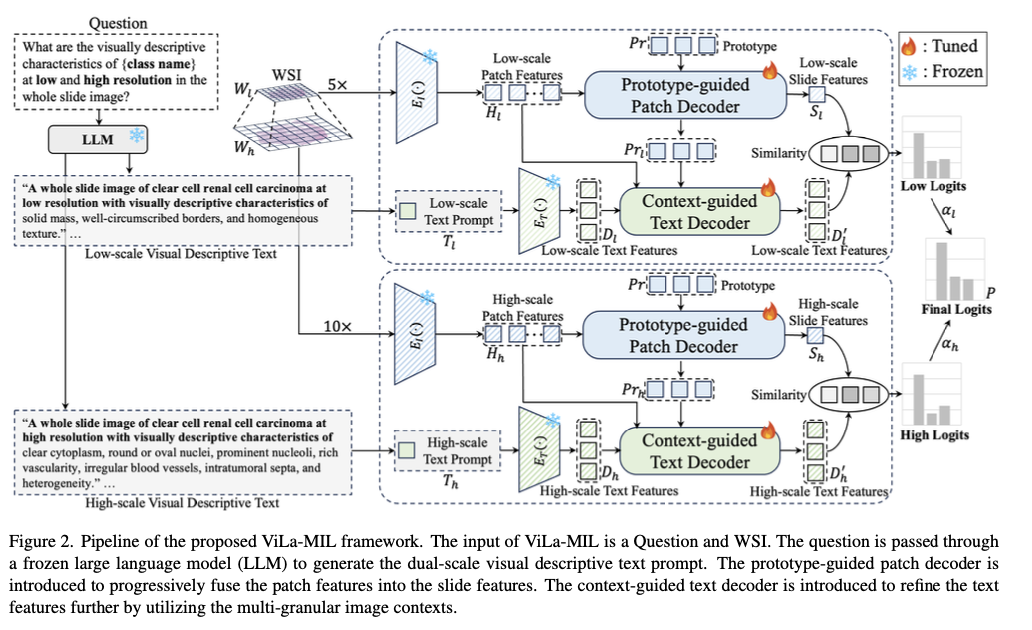
Предложенная модель полагается на клип в качестве базовой модели и использует несколько дополнений для адаптации его для патологических задач. Изображения целых слайдов пятнистых сегментируются на уровнях 5 × и 10 × увеличения, в то время как извлечение функций использует замороженный энкодер изображения Resnet-50. Замороженная крупная языковая модель GPT-3.5 также используется для создания специфических для класса описательных подсказок для двух шкал с обучаемыми векторами для облегчения эффективного представления признаков. Агломерация прогрессивных функций поддерживается с использованием набора из 16 ученительных векторов прототипа. Патч и прототип многонародовых функций также помогает поддерживать встроенные тексты, следовательно, улучшил кросс-модальный выравнивание. Оптимизация обучения использует потерю поперечной энтропии с одинаково взвешенными низкими и высокими показателями сходства для надежной поддержки классификации.
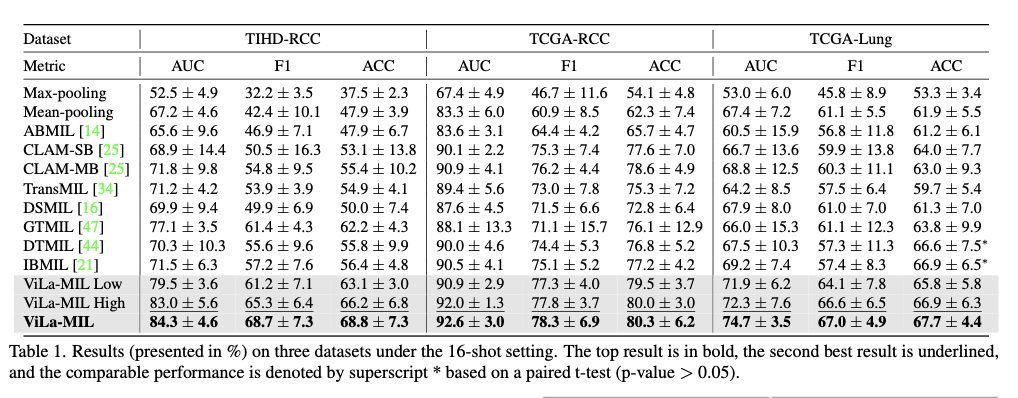
Этот метод демонстрирует лучшую производительность в различных наборах данных рака подтинга, значительно превосходящих современные методы на основе MIL и VLM в сценариях обучения с несколькими выстрелами. Модель записывает впечатляющие выгоды в AUC, оценке F1 и точении по сравнению с тремя различными наборами данных-TIHD-RCC, TCGA-RCC и TCGA-LUNG-демонстрируя прочность модели в тестах, выполненных как в одноцентровых, так и в многоцентровых установках. По сравнению с самыми современными подходами наблюдается значительный рост в точности классификации с повышением на 1,7% до 7,2% в AUC и 2,1% до 7,3% в балле F1. Применение двойного текста подсказки с прототипом, управляемым патч-декодером, и текстовым декодером, управляемым контекстом, помогает основы в его способности изучать эффективные дискриминационные морфологические модели, несмотря на наличие нескольких учебных экземпляров. Кроме того, отличные способности обобщения в нескольких наборах данных предполагают повышенную адаптивность к сдвигу домена во время перекрестного тестирования. Эти наблюдения демонстрируют достоинства слияния моделей языка зрений с специфическими патологией достижений в направлении классификации изображений цельной слайды.
Благодаря разработке новой двойной структуры обучения на языке зрения, это исследование вносит существенный вклад в классификацию WSI с использованием крупных языковых моделей для привлечения текстовых и прототипов. Метод усиливает обобщение нескольких выстрелов, снижает вычислительные затраты и способствует интерпретации, решению проблем с искусственным искусством в основной патологии. Опираясь на успешную передачу модели на языке зрений в цифровую патологию, это исследование является ценным вкладом в диагностику рака с ИИ с потенциалом для обобщения в других задачах по медицинским изображениям.
Проверить бумага и страница GitHub. Весь кредит на это исследование направлено на исследователей этого проекта. Кроме того, не стесняйтесь следить за нами Twitter И не забудьте присоединиться к нашему 75K+ ML SubredditПолем
🚨 Рекомендуемое чтение AI Research выпускает Nexus: расширенная система интеграции системы ИИ и стандартов соответствия данными для решения юридических проблем в наборах данных AI
Aswin AK является стажером консалтинга в MarkTechPost. Он получает двойную степень в Индийском технологическом институте, Харагпур. Он увлечен наукой данных и машинным обучением, обеспечивая сильный академический опыт и практический опыт решения реальных междоменных задач.


