


語言模型已經變得越來越昂貴。這使研究人員探索了諸如模型蒸餾之類的技術,在該技術中,較小的學生模型經過培訓以復制較大的教師模型的表現。這個想法是在不損害性能的情況下實現有效的部署。了解蒸餾背後的原理以及如何在學生和教師模型之間最佳分配計算資源對於提高效率至關重要。
機器學習模型的規模不斷增加,導致了高成本和可持續性挑戰。培訓這些模型需要大量的計算資源,推理要求更多的計算。相關費用可以超過預付費費用,推理量達到數十億個令牌。此外,大型模型提出了後勤挑戰,例如增加的能源消耗和部署難度。在不犧牲模型能力的情況下降低推理成本的必要性使研究人員尋求平衡計算效率和有效性的解決方案。
在大型模型培訓中解決計算限制的早期方法包括最佳的訓練和過度訓練。計算最佳培訓決定了給定的計算預算中表現最佳的模型大小和數據集組合。過度訓練將培訓數據使用擴展到計算 – 最佳參數之外,從而產生緊湊,有效的模型。但是,這兩種技術都有權衡,例如訓練持續時間增加和績效提高降低。儘管已經測試了壓縮和修剪方法,但它們通常會導致模型有效性下降。因此,需要採用更結構化的方法,例如提高效率。
蘋果公司和牛津大學的研究人員提出了一項蒸餾縮放法,該法律預測了基於計算預算分配的蒸餾模型的性能。該框架使教師和學生模型之間的計算資源的戰略分配,以確保最佳效率。該研究提供了針對計算最佳蒸餾的實用指南,並突出了蒸餾而不是監督學習的情況。該研究通過分析大型蒸餾實驗來建立訓練參數,模型大小和性能之間的明確關係。
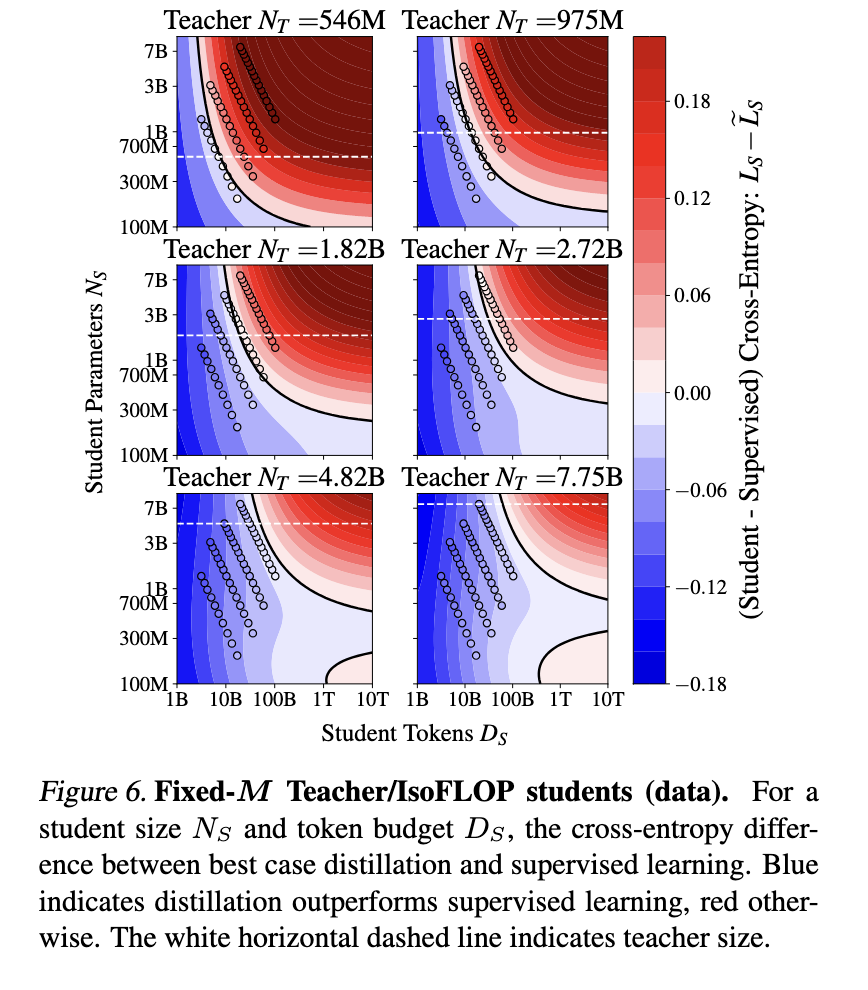
提出的蒸餾縮放法定義了學生的績效如何取決於教師的跨凝結損失,數據集大小和模型參數。該研究確定了兩種冪律行為之間的過渡,其中學生的學習能力取決於教師的相對能力。該研究還解決了容量差距現象,該現象表明,更強大的教師有時會造成較弱的學生。分析表明,這一差距是由於學習能力而不是單獨模型大小的差異。研究人員證明,當計算適當分配時,就效率而言,蒸餾可以匹配或超過傳統的監督學習方法。
經驗結果驗證了擴展法在優化模型性能方面的有效性。該研究對從1.43億至1,126億參數的學生模型進行了對照實驗,該參數使用了多達5120億個代幣的培訓。調查結果表明,當存在教師模型時,蒸餾是最有益的,分配給學生的計算或培訓令牌不會超過取決於模型大小的閾值。如果需要培訓教師,則監督學習仍然是更有效的選擇。結果表明,使用計算最佳蒸餾訓練的學生模型比在計算受到限制時使用監督學習訓練的學生可以實現較低的跨膜損失。具體而言,實驗表明,按照可預測的模式優化效率,學生的跨核損失隨教師交叉滲透的函數而降低。
關於蒸餾縮放定律的研究為提高模型培訓效率提供了分析基礎。建立一種計算分配的方法,它為降低推理成本提供了寶貴的見解,同時保留模型性能。這些發現有助於使AI模型更實用的更廣泛的目標。通過完善培訓和部署策略,這項工作可以開發較小而強大的模型,這些模型以降低的計算成本保持高性能。
查看 紙。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 75K+ ml子雷迪特。
🚨 推薦的開源AI平台:’Intellagent是一個開源多代理框架,可評估複雜的對話性AI系統‘ (晉升)
Nikhil是Marktechpost的實習顧問。他正在哈拉格布爾印度技術學院攻讀材料的綜合材料綜合學位。 Nikhil是AI/ML愛好者,他一直在研究生物材料和生物醫學科學等領域的應用。他在材料科學方面具有強大的背景,他正在探索新的進步並創造了貢獻的機會。
✅(推薦)加入我們的電報頻道

