


A large number of language models have made progress in machine translation to translate dozens of languages and dialects when capturing subtle linguistic noise. Nevertheless, fine tuning for these models for the accuracy of translation often struggles with extensive intended versions to meet their instruction-relevant and communication skills and professional loyalty standards. It is challenging to balance specific, culturally awakened translations with code generation, problem solving and handling user-specific formatting. Models must also preserve terminology compatibility and adhere to the formatting guide to a varied audience. Standers need systems that dynamically adapt to domain requirements and user preferences without sacrificing fluins. Benchmark scores such as WMT 24 ++ cover 55 language types, and IFVV’s 541 instruction-centered prompts illuminate the crucial hindrance for enterprise deployment, the quality of specific translation and the general-sense versatility.
Current approaches to Tailoring of Language Models Dello for the accuracy of translation
Multiple approaches have been invented in tailor -language models for translation. Fine-tuning on parallel corporations is used to improve adequacy and flow of translated text. Meanwhile, constantly preising on the combination of monolingual and parallel data, it enhances the multilingual flow. Some research teams have provided supplementary training with reinforcement education from human feedback to configure the output with quality preferences. Owned systems like GPT-4O and Cloud 7.7 have shown the quality of the leading translation, and the adaptation of open weight, including the Tower V2 and Gemma 2 models, has been parity or exceeded under views of certain languages. This strategy reflects constant efforts to consider the accuracy of translation and the two demands of the broad language capabilities.
Introduction to Tower+: Integrated training for translation and general language works
Anbabel, Institutes de Telecomunicas, Institute Superior TEE Kanico, Universe de Lisboa (Lisbon Alice Unit), and MICS, CentralSoplac, University Paris-Secle, Researchers presented Tower+Suite of models. The research team formed variables on multiple dimension scales, 2 billion, 9 billion and billion billion to explore the trade between translation specialty and general intended utility. By implementing the integrated training pipeline, researchers aimed to place the tower+ models on the Puretto Frontier, achieving both high translation exhibits and strong general capacity without sacrificing for each other. The approach to balancing the specific demand for a machine translation with the flexibility required by communication and instructional functions, to support the range of application views, gives the benefit of the architectures.
Tower+ Training Pipeline: Pritraining, Observed Tuning, Preferences and R.L.
The training pipeline carefully starts with continuous printing on the cured data contains a small fraction of examples of filtered parallel sentences and instructions formatted as monolingual content, translation instructions. Further, the observed fine-tuning code improves the model using a combination of translation functions, including mathematical problems, mathematical problems, and question-answers. A selected Optim follows the ptimization stage, the weight selection Optim trains on the types of ptimization and group-related policy updates-fa-polyy signals and human-traded translation types. Finally, reinforcement education with verified rewards strengthens specific compliance with a change guide, using the Ragex-based check and selection OT notations to improve the ability to adhere to clear instructions during translation. This combination of printing, observed configuration and prize -based updates gives a strong balance between the accuracy of the specific translation and the mastery of the versatile language.
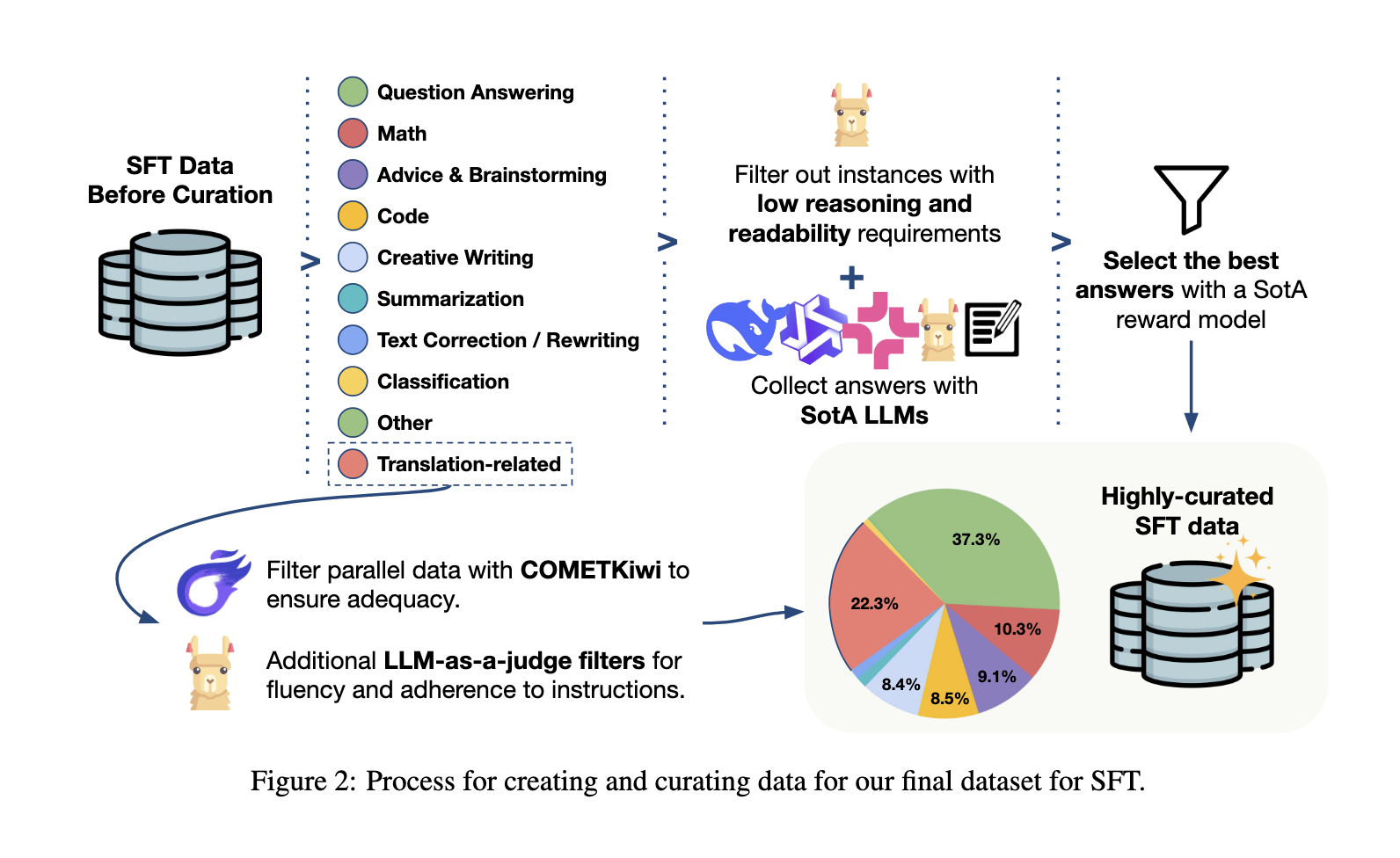
Benchmark Results: Tower+ sophisticated translation and receives instruction
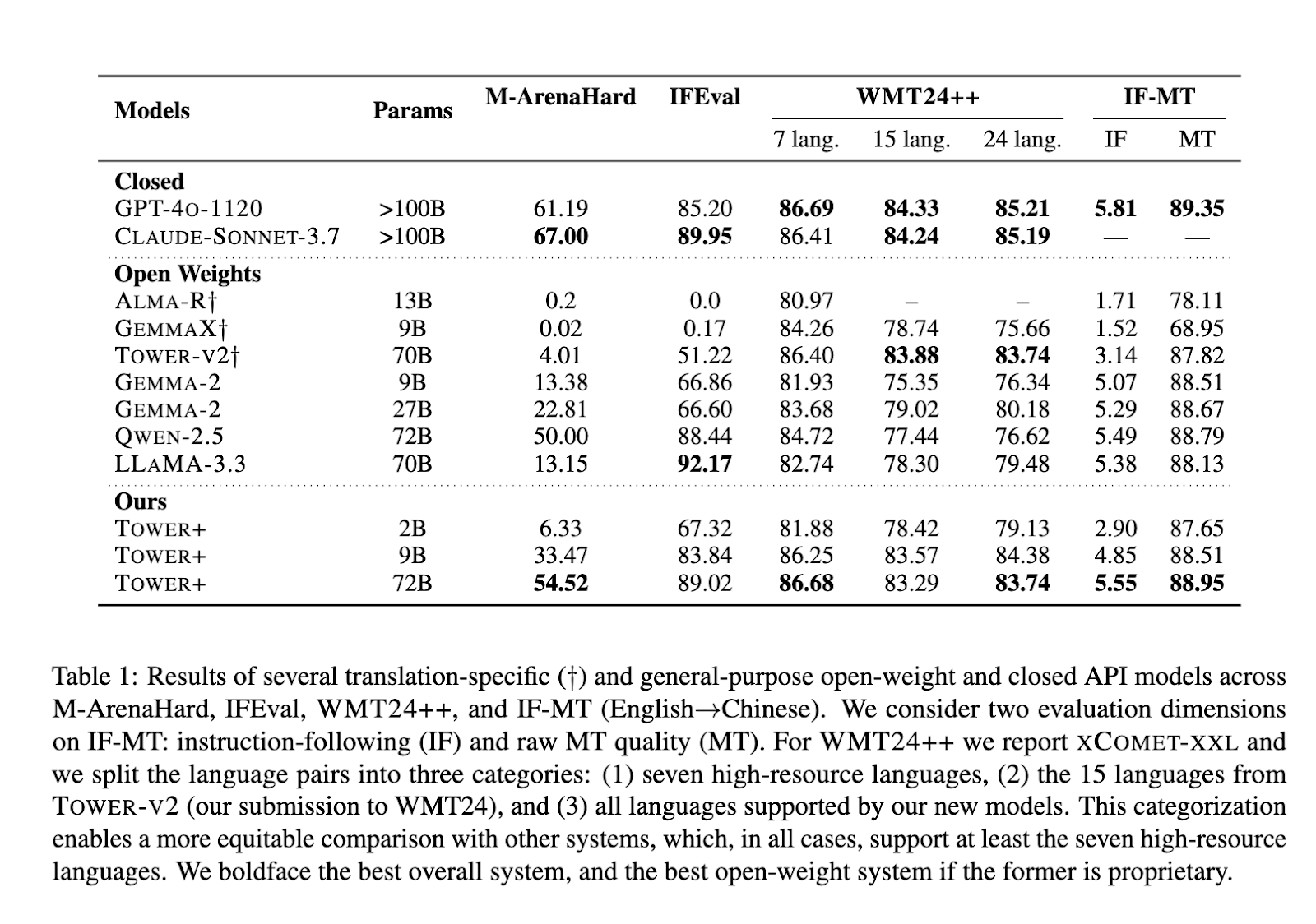
Tower+ 9B Model Dale achieved a win rate of 33.47% on multi-lingual general chat prompts, while in 24 pairs of 84 84.88 execent-XXL score, outperforming the same size open weight counterparts. Billion 1 billion-perimeter variant wins the M-Arenhard. On the joint translation and instruction-striking benchmark, IF-MT created 5.55 for notification and 88.95 for translation loyalty, establishing advanced results in open weight models. These results confirm that the integrated pipeline of researchers shows its viability for both enterprise and research programs, effectively pulling the distance between specialized translation exhibitions and comprehensive language capabilities.
The main technical highlights of the tower+ models
- Tower+ models, developed by unbbell and educational partners, 2B, 9B and 72B dimensions to explore the exhibition boundary between translation specialty and general intended utility.
- The pipeline after training integrates four stages: to maintain chat skills while increasing the accuracy of the translation, continuous pretraining (% 66% monolingual,% 33% parallel, and 1% instruction), observed fine-tuning (२२..3% translation), weight preference.
- Continuous Pritraining 27 languages and dialects, as well as 47 languages, covering more than 32 billion tokens, merging specific and general checkpoints to maintain balance.
- The 9B variant received 33.47% win rate on M-Arenahard, 83.84% at IFVWal, and 24 pairs.
- The B1B model has set 54.52% M-Arenahard, 89.02% iPhone, 83.29% XCOMET-XXL, and 5.55/88.95% IF-MT, new open-weight standard.
- With the quality of 6.33% and 87.65% IF-MT translation on M-Arenahard, the 2B model matched the larger baseline.
- GPT -4 O -1120, Cloud -Sonnet -3.7, Alma -R, Gemma -2, and Lalama -3.3, Tower+ Suite matches outperforms on both continuous and normal functions.
- Research provides a reproductive recipe for creating LLMS that meets simultaneous translation and communication requirements, reducing model proliferation and operational overhead.
Conclusion: A Pareto-Family Structure for Future Translation-Central LLMS
In conclusion, the tower+ shows that the translation can stay together in a single open weight suit, integrating large -scale printing with specific arrangement stages. The models achieve a poreto-best balance toward the loyalty, instruction-depressed and general chat capabilities of translation, which provides a scalable blueprint for future domain-specific LLM development.
Check Paper And Samples. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 100 k+ ml subredit And subscribe Our newsletter.
Asif Razzaq is the CEO of MarketechPost Media Inc. as a visionary entrepreneur and engineer, Asif is committed to increasing the possibility of artificial intelligence for social good. Their most recent effort is the inauguration of the artificial intelligence media platform, MarktecPost, for its depth of machine learning and deep learning news for its depth of coverage .This is technically sound and easily understandable by a large audience. The platform has more than 2 million monthly views, showing its popularity among the audience.



