


在本教程中,我們將探討如何使用Microsoft Presidio,這是一個開放式框架,旨在在自由形式的文本中檢測,分析和匿名化的個人身份信息(PII)。 Presidio建立在高效的Spacy NLP庫的頂部,既輕巧又模塊化,從而易於集成到實時應用程序和管道中。
我們將介紹如何:
- 設置並安裝必要的Presidio軟件包
- 檢測普通PII實體,例如名稱,電話號碼和信用卡詳細信息
- 定義特定域特異性實體的自定義識別器(例如,pan,aadhaar)
- 創建並註冊自定義匿名者(例如哈希或化名)
- 重複使用匿名映射以一致的重新匿名化
安裝庫
要開始使用Presidio,您需要安裝以下關鍵庫:
- 主載分析儀: 這是負責使用內置和自定義識別器在文本中檢測PII實體的核心庫。
- 總統匿名者: 該庫提供了使用可配置的操作員匿名(例如,編輯,替換,哈希)匿名的工具。
- Spacy NLP模型(en_core_web_lg): Presidio在引擎蓋下使用Spacy進行自然語言處理任務,例如命名實體識別。 EN_CORE_WEB_LG型號提供了高準確的結果,建議用於英語PII檢測。
pip install presidio-analyzer presidio-anonymizer
python -m spacy download en_core_web_lg如果您使用的是Jupyter/Colab,則可能需要重新啟動會話以安裝庫。
Presidio分析儀
基本PII檢測
在此塊中,我們初始化了Presidio Analyzer引擎,並運行基本分析以從示例文本中檢測美國電話號碼。我們還抑制了Presidio庫中的下層日誌警告,以提供更清潔的輸出。
AnalligerEngine加載了Spacy的NLP管道和預定義的識別器,以掃描敏感實體的輸入文本。在此示例中,我們將phone_number指定為目標實體。
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=("PHONE_NUMBER"),
language="en")
print(results)創建具有拒絕列表(學術冠軍)的自定義PII識別器
此代碼塊顯示瞭如何使用簡單的拒絕列表在Presidio中創建自定義PII識別器,非常適合檢測諸如學術標題(例如“ Dr.”,“ Dr.”,“ Prof.”)之類的固定術語。識別器被添加到Presidio的註冊表中,並由分析儀用於掃描輸入文本。
儘管本教程僅涵蓋拒絕列表方法,但Presidio還支持基於正則的模式,NLP模型和外部識別器。對於這些高級方法,請參閱官方文檔:添加自定義識別器。
Presidio分析儀
基本PII檢測
在此塊中,我們初始化了Presidio Analyzer引擎,並運行基本分析以從示例文本中檢測美國電話號碼。我們還抑制了Presidio庫中的下層日誌警告,以提供更清潔的輸出。
AnalligerEngine加載了Spacy的NLP管道和預定義的識別器,以掃描敏感實體的輸入文本。在此示例中,我們將phone_number指定為目標實體。
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=("PHONE_NUMBER"),
language="en")
print(results)
創建具有拒絕列表(學術冠軍)的自定義PII識別器
此代碼塊顯示瞭如何使用簡單的拒絕列表在Presidio中創建自定義PII識別器,非常適合檢測諸如學術標題(例如“ Dr.”,“ Dr.”,“ Prof.”)之類的固定術語。識別器被添加到Presidio的註冊表中,並由分析儀用於掃描輸入文本。
儘管本教程僅涵蓋拒絕列表方法,但Presidio還支持基於正則的模式,NLP模型和外部識別器。對於這些高級方法,請參閱官方文檔:添加自定義識別器。
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, RecognizerRegistry
# Step 1: Create a custom pattern recognizer using deny_list
academic_title_recognizer = PatternRecognizer(
supported_entity="ACADEMIC_TITLE",
deny_list=("Dr.", "Dr", "Professor", "Prof.")
)
# Step 2: Add it to a registry
registry = RecognizerRegistry()
registry.load_predefined_recognizers()
registry.add_recognizer(academic_title_recognizer)
# Step 3: Create analyzer engine with the updated registry
analyzer = AnalyzerEngine(registry=registry)
# Step 4: Analyze text
text = "Prof. John Smith is meeting with Dr. Alice Brown."
results = analyzer.analyze(text=text, language="en")
for result in results:
print(result)
Presidio匿名者
該代碼塊演示瞭如何使用Presidio匿名引擎來在給定文本中檢測到的PII實體。在此示例中,我們使用venizerresult手動定義兩個人實體,從而模擬Presidio Analyzer的輸出。這些實體在示例文本中代表“邦德”和“詹姆斯·邦德”的名稱。
我們使用“替換”運算符將兩個名稱用佔位符值(“ BIP”)替換,從而有效地匿名了敏感數據。這是通過將帶有所需匿名策略(替換)的OperatorConfig傳遞給Anonymizerengine來完成的。
可以輕鬆地擴展此模式,以應用其他內置操作,例如“ REDACT”,“ HASH”或自定義的化名策略。
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine:
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer) and
# Operators to get the anonymization output:
result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=(
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
),
operators={"PERSON": OperatorConfig("replace", {"new_value": "BIP"})},
)
print(result)
自定義實體識別,基於哈希的匿名化以及與Presidio的一致重新匿名化
在此示例中,我們通過證明:
- ✅使用基於REGEX的模式證明器定義自定義PII實體(例如,Aadhaar和PAN號)
- 🔐使用基於自定義哈希的運算符(RealNommizer)的匿名數據匿名數據
- ♻️通過維護原始→哈希值的映射,將相同的值始終如一地重新匿名化相同的值
我們實施了一個自定義的重新匿名運算符,該操作員檢查給定值是否已經被哈希進行,並重新使用相同的輸出以保持一致性。當匿名數據需要保留某些實用程序時,這一點特別有用,例如,通過假名ID鏈接記錄。
定義基於自定義哈希的匿名器(ReAnonymizer)
該塊定義了一個稱為ReAnymonizer的自定義運算符,該定制運算符使用SHA-256散列對匿名實體,並確保相同的輸入始終通過在共享映射中存儲哈希相同的匿名輸出獲得相同的匿名輸出。
from presidio_anonymizer.operators import Operator, OperatorType
import hashlib
from typing import Dict
class ReAnonymizer(Operator):
"""
Anonymizer that replaces text with a reusable SHA-256 hash,
stored in a shared mapping dict.
"""
def operate(self, text: str, params: Dict = None) -> str:
entity_type = params.get("entity_type", "DEFAULT")
mapping = params.get("entity_mapping")
if mapping is None:
raise ValueError("Missing `entity_mapping` in params")
# Check if already hashed
if entity_type in mapping and text in mapping(entity_type):
return mapping(entity_type)(text)
# Hash and store
hashed = ""
mapping.setdefault(entity_type, {})(text) = hashed
return hashed
def validate(self, params: Dict = None) -> None:
if "entity_mapping" not in params:
raise ValueError("You must pass an 'entity_mapping' dictionary.")
def operator_name(self) -> str:
return "reanonymizer"
def operator_type(self) -> OperatorType:
return OperatorType.Anonymize 定義PAN和AADHAAR編號的自定義PII識別器
我們定義了兩個基於自定義的正則表達式的模式識別器 – 一個用於印度鍋的數字,一個用於Aadhaar數字。這些將檢測您文本中的自定義PII實體。
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, Pattern
# Define custom recognizers
pan_recognizer = PatternRecognizer(
supported_entity="IND_PAN",
name="PAN Recognizer",
patterns=(Pattern(name="pan", regex=r"\b(A-Z){5}(0-9){4}(A-Z)\b", score=0.8)),
supported_language="en"
)
aadhaar_recognizer = PatternRecognizer(
supported_entity="AADHAAR",
name="Aadhaar Recognizer",
patterns=(Pattern(name="aadhaar", regex=r"\b\d{4}(- )?\d{4}(- )?\d{4}\b", score=0.8)),
supported_language="en"
)設置分析儀和匿名引擎
在這裡,我們設置了Presidio Analyzerengine,註冊自定義識別器,然後將自定義匿名器添加到Anonymizerengine中。
from presidio_anonymizer import AnonymizerEngine, OperatorConfig
# Initialize analyzer and register custom recognizers
analyzer = AnalyzerEngine()
analyzer.registry.add_recognizer(pan_recognizer)
analyzer.registry.add_recognizer(aadhaar_recognizer)
# Initialize anonymizer and add custom operator
anonymizer = AnonymizerEngine()
anonymizer.add_anonymizer(ReAnonymizer)
# Shared mapping dictionary for consistent re-anonymization
entity_mapping = {}分析和匿名輸入文本
我們分析了兩個單獨的文本,它們都包含相同的鍋和Aadhaar值。自定義操作員確保它們在兩個輸入中都始終如一地匿名。
from pprint import pprint
# Example texts
text1 = "My PAN is ABCDE1234F and Aadhaar number is 1234-5678-9123."
text2 = "His Aadhaar is 1234-5678-9123 and PAN is ABCDE1234F."
# Analyze and anonymize first text
results1 = analyzer.analyze(text=text1, language="en")
anon1 = anonymizer.anonymize(
text1,
results1,
{
"DEFAULT": OperatorConfig("reanonymizer", {"entity_mapping": entity_mapping})
}
)
# Analyze and anonymize second text
results2 = analyzer.analyze(text=text2, language="en")
anon2 = anonymizer.anonymize(
text2,
results2,
{
"DEFAULT": OperatorConfig("reanonymizer", {"entity_mapping": entity_mapping})
}
)查看匿名結果和映射
最後,我們打印出匿名輸出,並在內部檢查用於維持跨值的一致哈希的映射。
print("📄 Original 1:", text1)
print("🔐 Anonymized 1:", anon1.text)
print("📄 Original 2:", text2)
print("🔐 Anonymized 2:", anon2.text)
print("\n📦 Mapping used:")
pprint(entity_mapping)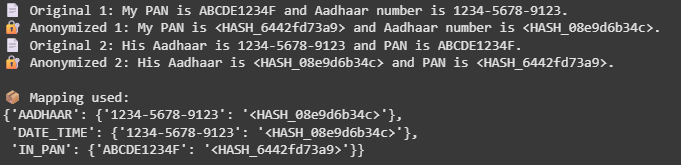
查看 代碼。 這項研究的所有信用都歸該項目的研究人員。另外,請隨時關注我們 嘰嘰喳喳 而且不要忘記加入我們的 100K+ ml子雷迪特 並訂閱 我們的新聞通訊。

我是新德里賈米亞·米利亞伊斯蘭伊斯蘭的土木工程畢業生(2022年),我對數據科學,尤其是神經網絡及其在各個領域的應用都非常感興趣。


