

Audio Dio-Based Human-Computer Interaction Remember
Machines that can respond to human speech with evenly expressive and natural Audio deo have become the main target in intelligent interaction systems. The Audio de-limiting modeling expands this vision by identifying the identity of the modeling speech, the understanding of the natural language and the Audio deio generation. Instead of relying on text conversions, the models of this space alone aim to understand and answer using sound alone. This is crucial not only for Ibility cessability and incorporation, but also for Voice Is assistants, Audio deo-based storytelling and applications such as hand-free computing, even crucial for achieving machine interaction like human-like machine.
Limitations of cascade speech pipelines
Despite the progress in the Audio Dio understanding, the clear challenge is pending: most systems still depend on the chain of speech-to-text, text processing and text-to-speech conversion. This modular approach can degrade the performance and response due to accumulated errors and delays. Moreover, these pipelines lack expressive control, representing them inappropriately for nunnant tasks such as emotional dialogue or dynamic speech synthesis. An ideal solution would be a perfectly unified model that will be able to understand the Audio Dio question and directly express Audio Dio answer, removing all text-based mediations there.
From token-based models to fully integrated LMM
Many methods have tried to address this. Initial approaches, such as Huginggupt and I degupt, use cascade architectures that combine different speech and language models delo. When they expand the work coverage, these systems struggle with real-time and voice is interaction. Later tasks, such as V All L-E, SpeechGPT, I Deplam and Queen 2-Audio Dio, presents token-based systems that convert Audio Dio into independent representations. Nevertheless, these models also often output the output text and require a separate OD door, which limits their ability to produce immediate, immediate Audio deio answers.
Step-Audio Dio-AQA presenting: End from the end ACUA System
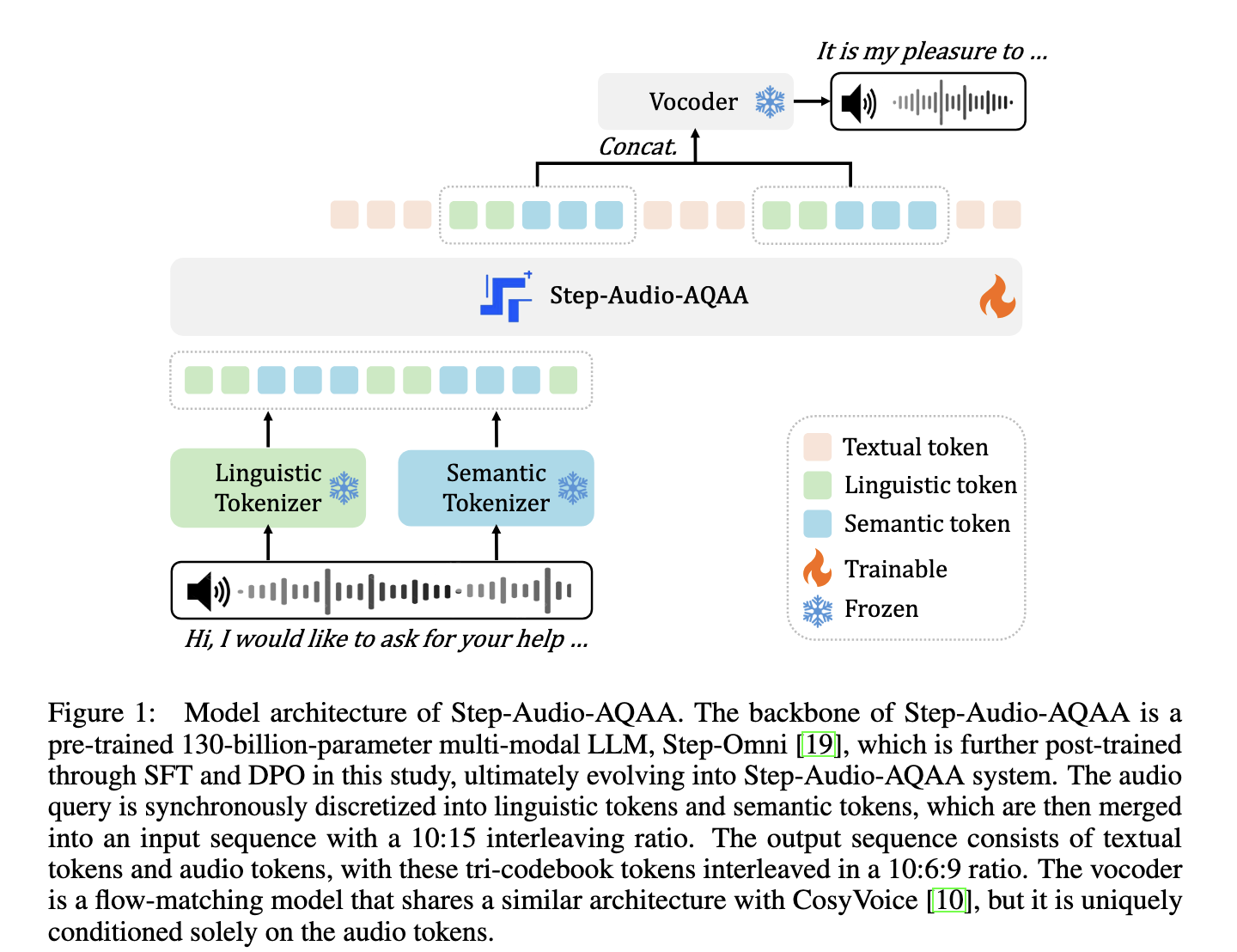
Stepfan researchers introduced Step-Audio Dio-AQA, a full end-to-end larger Audio degwae model, especially the Audio Dio Query-Audio Dio, is designed for reply tasks. Unlike previous models, the Step-Audio Dio-AQA transforms the spoken input directly into an intermediate text without turning the spoken input into a meaningful text. In this architecture, a dual-codbook tokenizer, a 130-billion-parameter backbone named Step-Om, combines flow-matching wodar for LLM and natural speech synthesis. The integration of these components enables seamless, low-pattern interaction.

Tokenization, architecture and voice is control
This method starts with two separate Audio deo tokenizers – one for linguistic features and the other for semantic processes. Linguistic tokenizers, based on pariformer, have structured speech elements such as phonemes at 16.7 Hz using a codebook of 1,024 tokens. Meanwhile, the semantic tokenizer (inspired by Cosvois 1.0) encodes acoustic prosperity at 25 Hz with 4,096 tokens. This is interlaved in 2: 3 ratio and passes in step-omni, trained on multimodal decoder-only LLM text, Audio deio and image data. After this, the model outputs the Tri-Codebook sequences of Audio Dio and text tokens, which are transformed into a vodder liquid speech. This setup enables the fine-grained voice is control, including the emotional tone and speech rate.
Benchmark evaluation and results
This model was evaluated using the Stepel-Audio Dio-360 Benchmark, which includes multi-term, multi-dactal Audio Dio functions in nine categories, including creativity, gaming, emotion control, role and voice is understanding. Compared to sophisticated Models Dello, such as Kimi-Audio Dio and Quain-Om, Step-Audio Dio-Aka achieved the highest average opinion scores in most categories. In particular, in the text-audio deo token ratio experiments, the configuration with a 10:15 ratio achieved the top display with chat (3.03), consistency (0.65) and facts (0.67) scores. In various Audio deo interliving techniques, marker-saving contents performed best with chat (2.1), consistency (0.57) and fact (0.57) scores. This number reflects its power in producing respondents in response to a ceiling, emotionally rich and context-aware Audio deio.

Conclusion: toward an expressive machine speech
Step-Audio Dio-AQA modular speech processing gives a strong remedy for the limits of pipelines. By combining advanced post-training strategies such as expressive Audio deo tokenization, a powerful multimodal LLM, and direct selection Optim ptimization and model merge, it succeeds in responding to high-quality, emotionally resonant Audio Dio. This task is a significant step to enable machines to communicate with speech that is not only functional but also meaningful and fluid.
Check Paper and model on a hug face. All credit for this research goes to researchers of this project. Also, feel free to follow us Twitter And don’t forget to join us 100 k+ ml subredit And subscribe Our newsletter.
Nikhil is an intern consultant at MarketechPost. He is gaining a dual degree in materials in the technology of the Indian organization in Kharagpur. Nikhil AI/ML is enthusiastic that always researches application in areas such as biometrials and biomedical vigels. With a strong background in the physical expression, he is looking for new progress and chances of contributing.


