

बड़े भाषा मॉडल डेल (एलएलएमएस) मॉडल मुख्य रूप से उनके आंतरिक JNWLEGE पर आधारित होते हैं, जो वास्तविक समय या JNWeldge- गहन प्रश्नों को संभालते समय अपर्याप्त हो सकते हैं। यह सीमा अक्सर गलत प्रतिक्रियाओं या उदासी की ओर ले जाती है, जिससे एलएलएम बाहरी पहचान क्षमताओं के साथ बढ़ाते हैं। सुदृढीकरण शिक्षा का लाभ देकर, शोधकर्ता सक्रिय रूप से अपने स्थिर Junowledge- आधारित समर्थन से संबंधित जानकारी को पुनर्प्राप्त करने और एकीकृत करने के तरीकों पर काम कर रहे हैं और इन मॉडलों की क्षमता को एकीकृत कर रहे हैं।
वर्तमान LLMS का उन्नत और डोमेन-विशिष्ट Jnowledge एक प्रमुख मुद्दा है। चूंकि इन मॉडलों को विस्तृत डेटासेट पर प्रशिक्षित किया गया है, इसलिए वे हाल के विकास को शामिल नहीं कर सकते हैं, इसलिए वे वास्तविक समय की जानकारी की आवश्यकता वाले गतिशील प्रश्नों के उत्तरों के साथ संघर्ष करते हैं। जबकि इस मुद्दे को कम करने के लिए समीक्षा-संवर्धित पीढ़ी (आरएजी) के तरीकों को पेश किया गया है, मौजूदा समाधान संरचित प्रॉम्प्टिंग और फाइन-ट्यूनिंग (एसएफटी) पर बहुत निर्भर करते हैं। ये दृष्टिकोण अक्सर विभिन्न डेटासेट में मॉडल के सामान्यीकरण को सीमित करते हुए, ओवरफिटिंग की ओर ले जाते हैं। एक विकल्प की आवश्यकता है जो एलएलएम को बाहरी खोज प्रणालियों के साथ स्वायत्त रूप से संपर्क करने की अनुमति देता है, उनकी अनुकूलनशीलता और सटीकता में सुधार करता है।
पिछले तरीकों ने मोंटे कार्लो ट्री सर्च (MCTS) जैसी बार-बार प्रॉम्प्टिंग, फाइन-ट्यूनिंग और ट्री-आधारित खोज तकनीकों का उपयोग करके एलएलएम में बाहरी खोज कार्यक्षमता को शामिल करने की कोशिश की है। जबकि ये तरीके कुछ अपडेट दिखाते हैं, वे महंगे गणना संसाधनों और स्वामित्व के मॉडल पर निर्भर करते हैं। उदाहरण के लिए, ठीक-ट्यूनिंग का अवलोकन किया गया, मॉडल को तर्क पथ को याद करने के लिए मजबूर करता है, जो नए दृश्यों को सामान्य करने की उनकी क्षमता को नकारात्मक रूप से प्रभावित करता है। । इन सीमाओं को एलएलएम के लिए अधिक स्वायत्त और कुशल खोज विधि के विकास की आवश्यकता होती है।
चीन के रेनमाइन यूनिवर्सिटी और एक उपन्यास सुदृढीकरण शिक्षा ढांचे, एक उपन्यास सुदृढीकरण शिक्षा ढांचा, जिसे आर 1-सर्चर को प्रभावी ढंग से प्राप्त करने की क्षमता में सुधार करने के लिए डिज़ाइन किया गया, आर 1-सर्चर, एलएलएमएस जारी किया गया। यह संरचना एलएलएम को मानव निर्मित संकेतों या पिछले देखे गए फाइन-ट्यूनिंग की आवश्यकता के बिना एक बाहरी खोज प्रणाली का अनुरोध करने के लिए एलएलएम को सक्षम करने के लिए एक दो-चरण सुदृढीकरण सीखने के दृष्टिकोण का उपयोग करती है। केवल सुदृढीकरण शिक्षा पर ध्यान केंद्रित करके R1-डिस्प्ले मॉडल को स्वायत्त रूप से सबसे अच्छी वसूली रणनीतियों का पता लगाने और सीखने की अनुमति देता है, तर्क कार्यों में सटीकता और दक्षता में सुधार करता है।
R1-डिस्प्ले फ्रेमवर्क को दो चरणों में डिज़ाइन किया गया है। पहला चरण मॉडल को बाहरी खोज क्रियाओं को शुरू करने के लिए प्रोत्साहित करता है, अंतिम उत्तर की सटीकता की परवाह किए बिना एक बहाली -आधारित पुरस्कार प्रदान करता है। यह चरण यह सुनिश्चित करता है कि मॉडल खोज क्वेरीज को ठीक से अनुरोध करना सीखता है। दूसरा चरण उत्तर-आधारित पुरस्कार प्रणाली को प्रस्तुत करके इस क्षमता में सुधार करता है, जो मूल्यांकन करता है कि क्या प्राप्त जानकारी किसी दिए गए समस्या को हल करने में योगदान देती है। सुदृढीकरण सीखने की प्रक्रिया इसी क्षति के कार्य पर निर्भर करती है जो बाहरी भूमि के प्रभावी उपयोग को लाभ पहुंचाते समय गलत या अनावश्यक पहचान को दंडित करती है। पिछले रेडी प्रोक्योरमेंट -आधारित तकनीकों के विपरीत, यह दृष्टिकोण LLM को उनकी अनुकूलनशीलता, गतिशील रूप से तर्क और पुनर्प्राप्ति के लिए उनकी अनुकूलनशीलता को एकीकृत करने की अनुमति देता है।
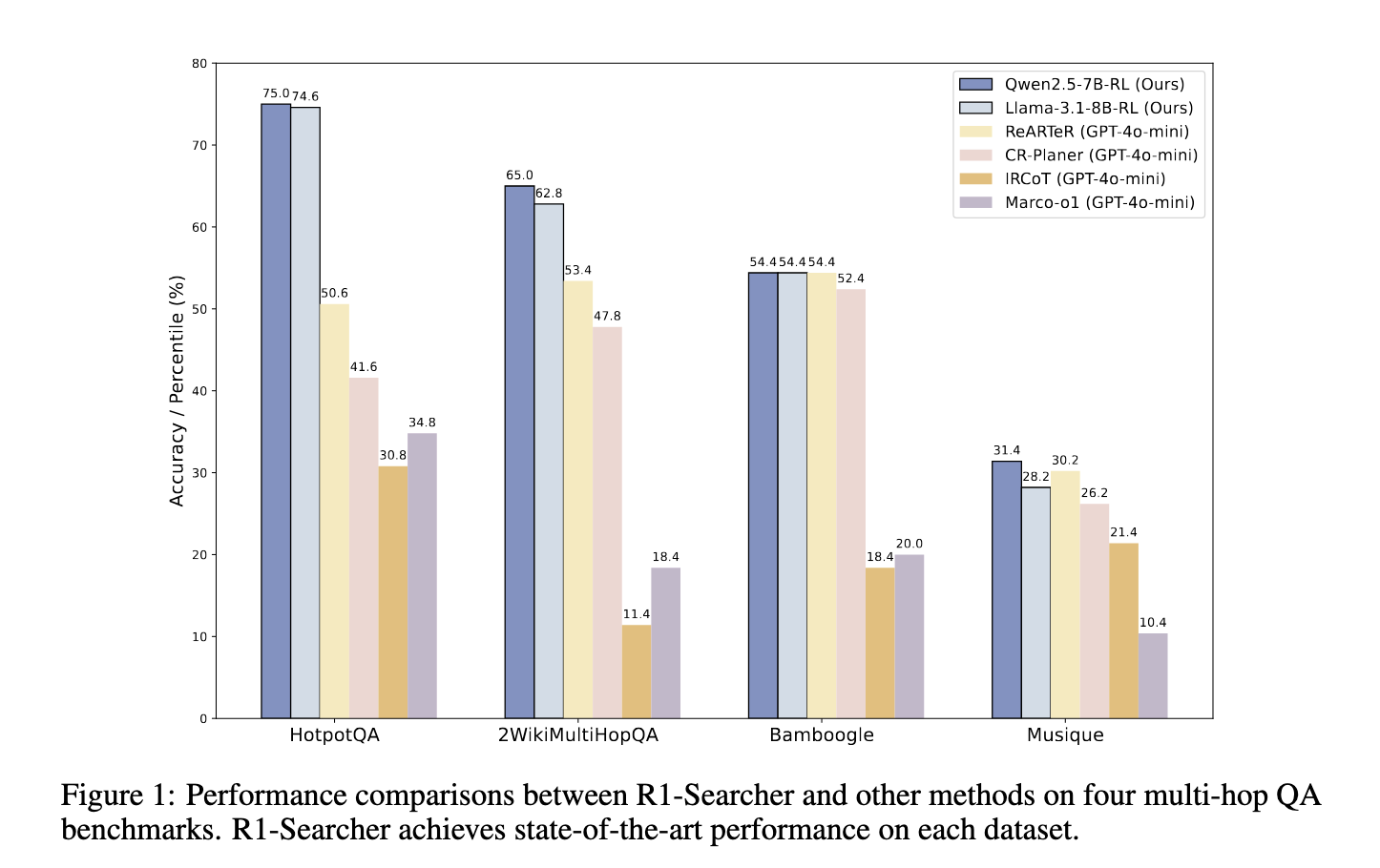
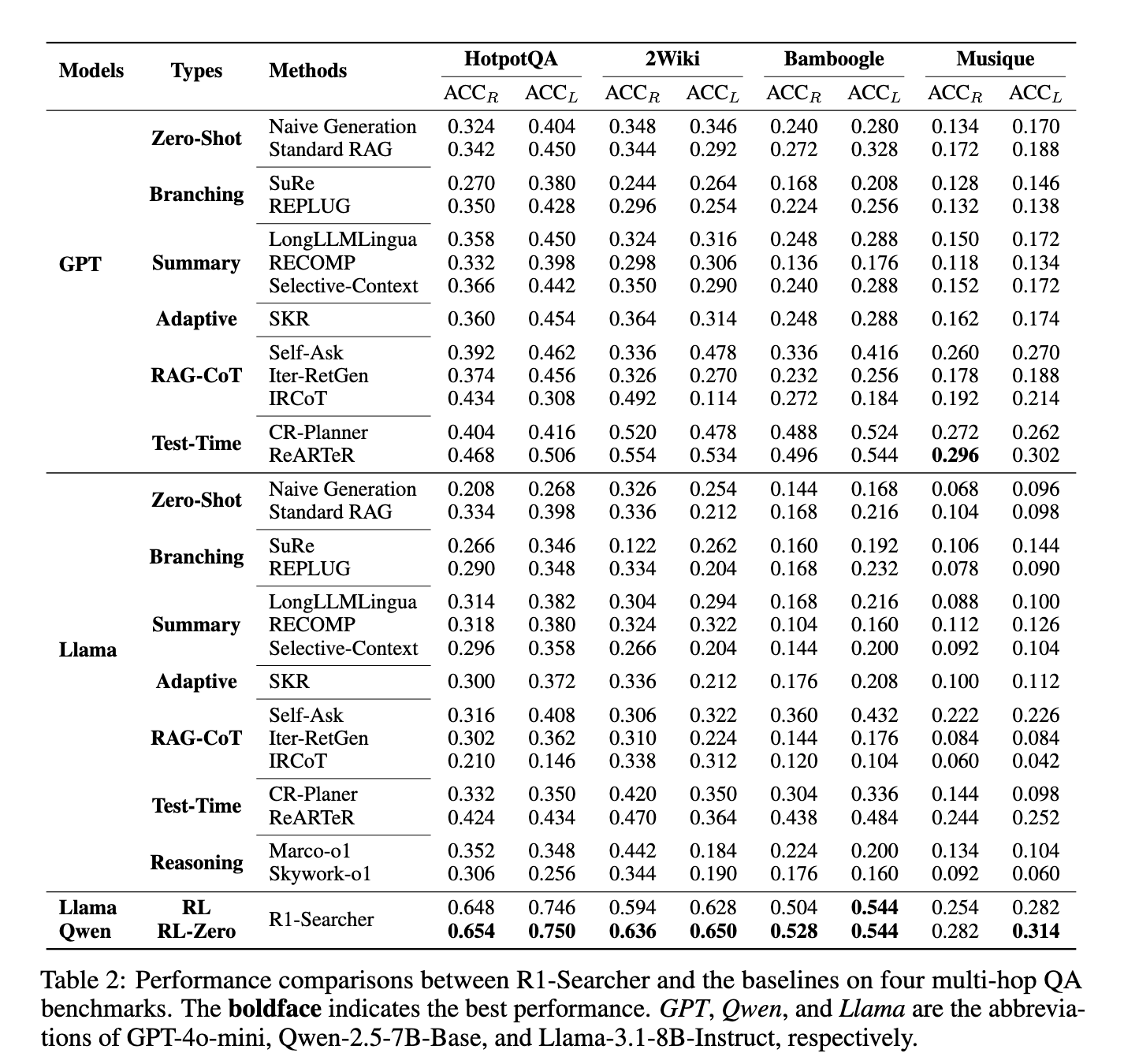
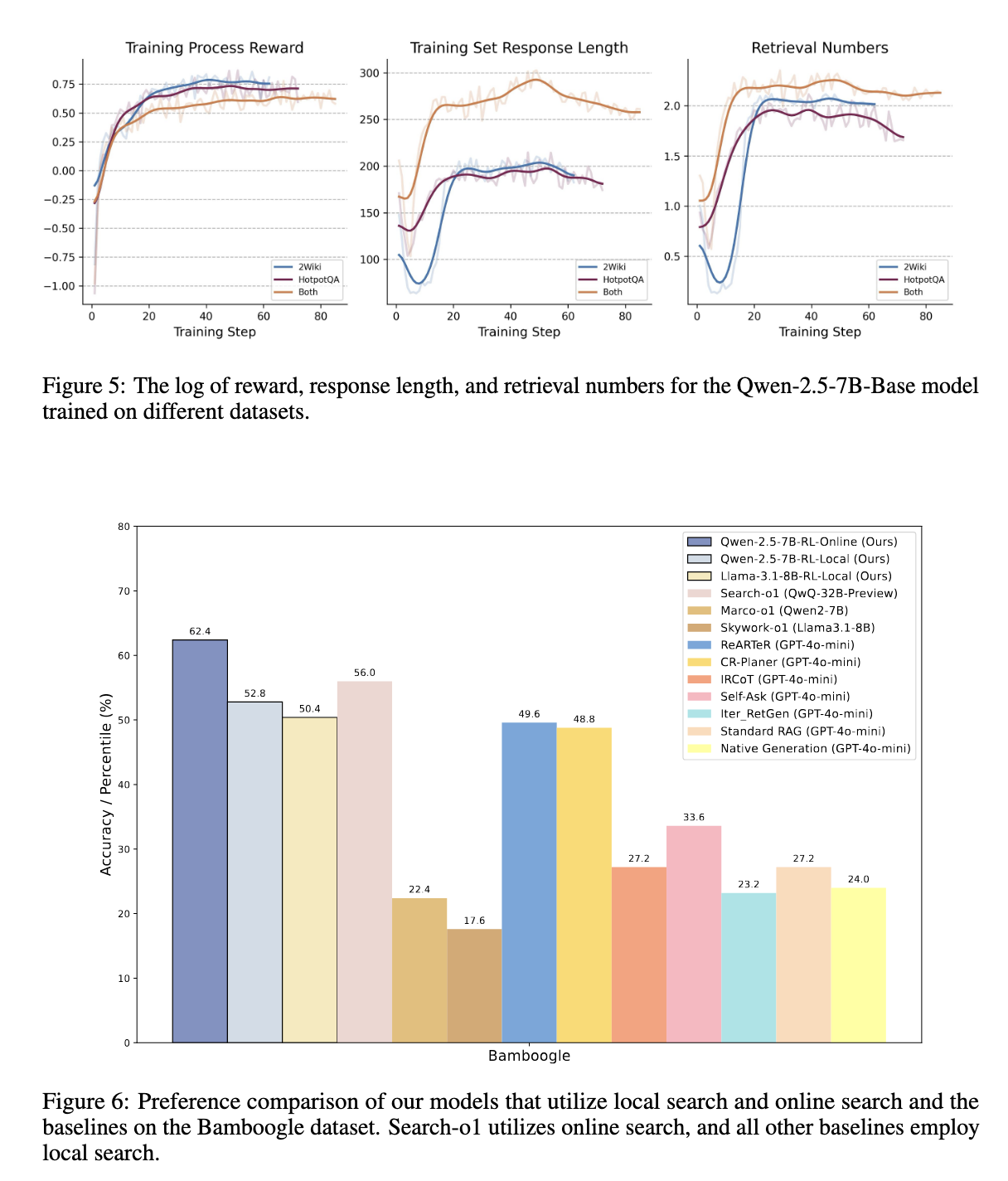
प्रायोगिक मूल्यांकन से पता चला कि आर 1-स्कोरर ने मौजूदा रिकवरी-ऑफ-फॉर्मिंग विधियों को अग्रेषित किया है, जिसमें जीपीटी -4 ओ-मीनि-आधारित मॉडल शामिल हैं। HOTPOTQA डेटासेट, सटीकता में 48.22%में सुधार हुआ है, जबकि 2wikimultihopqa डेटासेट पर, यह 21.72%बढ़ गया है। इसके बाद, उन्होंने बेबीबग डेटासेट पर अन्य मॉडलों का पीछा करके सामान्यीकरण की मजबूत क्षमताओं को दिखाया, तुलनात्मक पुनर्प्राप्ति-आधारित दृष्टिकोणों पर 11.4% सुधार प्राप्त किया। पिछली तकनीकों के विपरीत, जो बंद-स्रोत मॉडल और व्यापक गणना संसाधनों पर निर्भर करते हैं, आर 1-डिस्प्ले खोज और तर्क कार्यों में दक्षता बनाए रखते हुए सबसे अच्छा प्रदर्शन प्रदान करता है। अध्ययन से यह भी पता चलता है कि इस दृष्टिकोण ने एलएलएम-जनित प्रतिक्रिया में कमी और गलत सूचना से संबंधित सामान्य मुद्दों को सफलतापूर्वक कम कर दिया है।
निष्कर्ष बताते हैं कि स्वायत्त पहचान क्षमताओं के साथ एलएलएम को बढ़ाने से उनकी सटीकता और सामान्यीकरण में काफी सुधार हो सकता है। ठीक-ठाक-ट्यूनिंग के बजाय सुदृढीकरण शिक्षा का उपयोग करना, आर 1-डिस्प्ले मॉडल आधुनिक-दिन को सबसे अच्छी वसूली रणनीति सीखने की अनुमति देते हैं, जो याद किए गए उत्तरों पर निर्भरता को समाप्त करते हैं। यह दृष्टिकोण कृत्रिम बुद्धिमत्ता में प्रमुख प्रगति का प्रतिनिधित्व करता है, मौजूदा मॉडलों की सीमाओं को ध्यान में रखते हुए जब वे यह सुनिश्चित करते हैं कि विकसित Junoweltge आवश्यकताओं के अनुकूल है। अध्ययन के परिणाम एलएलएम में क्रांति के सुदृढीकरण की संभावना पर प्रकाश डालते हैं, जिससे वे विभिन्न तर्क के लिए अधिक विश्वसनीय हो जाते हैं, जिससे वे अधिक विश्वसनीय हो जाते हैं।
जाँच करना पेपर और GitHB पेज। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमसे जुड़ने के लिए मत भूलना 80K+ एमएल सबमिटेड।
। MEET PALLANT: व्यवहार दिशानिर्देशों और रनटाइम मॉनिटरिंग का उपयोग करके, अपने AI ग्राहक सेवा एजेंटों पर आवश्यक नियंत्रण और सटीकता प्रदान करने के लिए AI फ्रेमवर्क डेवलपर्स को प्रदान करने के लिए एक LLM-FIRST वार्तालाप किया गया है। 🔧 🔧 🎛 इसका उपयोग करना आसान है। और पायथन और टाइपस्क्रिप्ट में मूल ग्राहक एसडीके का उपयोग करके संचालित है।
निखिल मार्केटकपोस्ट में एक इंटर्न कंसल्टेंट है। वह खड़गपुर में भारतीय संगठन की प्रौद्योगिकी में सामग्री में दोहरी डिग्री प्राप्त कर रहा है। निखिल एआई/एमएल उत्साही है जो हमेशा बायोमेट्रियल और बायोमेडिकल विगल्स जैसे क्षेत्रों में आवेदन पर शोध करता है। भौतिक अभिव्यक्ति में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति और योगदान की संभावना की तलाश कर रहा है।
पार्लेंट: LLMS (B ED) के साथ एक विश्वसनीय AI ग्राहक का सामना करना


